Does Postgres Scale?
Source: Hacker News
When building a durable workflow execution system on Postgres
One of the most common questions we get is “does Postgres scale?”
There are plenty of posts from top tech teams asserting that Postgres does scale (e.g., Figma’s blog, Notion’s blog), but not all show how its performance scales in practice.
In this blog post we benchmark the scalability of a single Postgres server.
We focus on the performance of Postgres writes, because those are the bottleneck in workflow execution: a durable workflow must write to the database multiple times to checkpoint its inputs, its outcome, and the outcome of each of its steps.
- Raw Postgres write throughput – measured in a vacuum.
- Durable‑workflow workloads – one that starts workflows locally, and one that uses a Postgres‑backed queue.
Key findings
- A single server can sustain 144 K writes per second, or process 43 K workflows per second.
- That translates to 12 billion writes or 4 billion workflows per day – more than enough for most use cases.
All benchmark code is open‑source here.
All experiments were conducted on an AWS RDS db.m7i.24xlarge instance with 96 vCPUs, 384 GB RAM, and 120 K provisioned IOPS on an io2 volume.
Postgres Point‑Write Performance
We first measured the maximum write throughput Postgres can sustain to a single table.
The table schema is a simple three‑column table:
CREATE TABLE test (
id UUID PRIMARY KEY, -- UUIDv7
data TEXT,
ts TIMESTAMP
);Insert benchmark
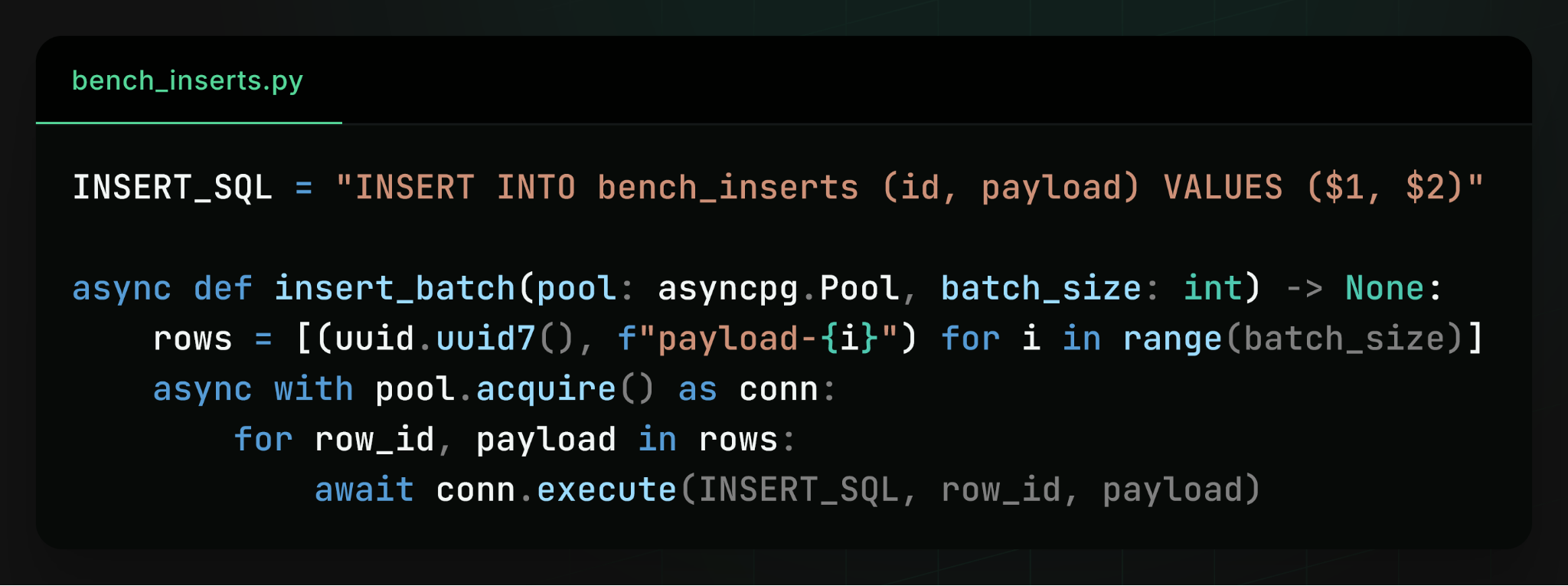
We benchmarked how many rows we can insert per second from a large number of async Python clients.
Each row is inserted in a separate transaction.
Result: a Postgres server can handle up to 144 K writes per second – roughly 12 billion writes per day.
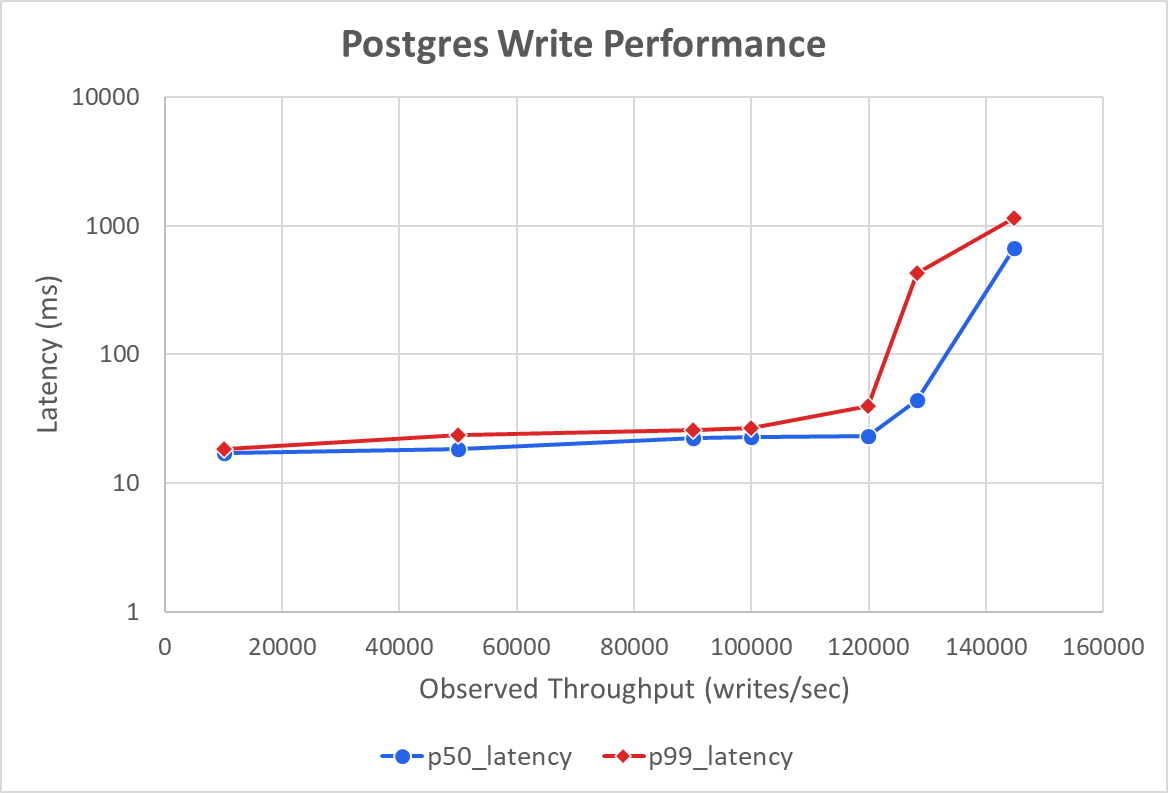
Where the bottleneck lies
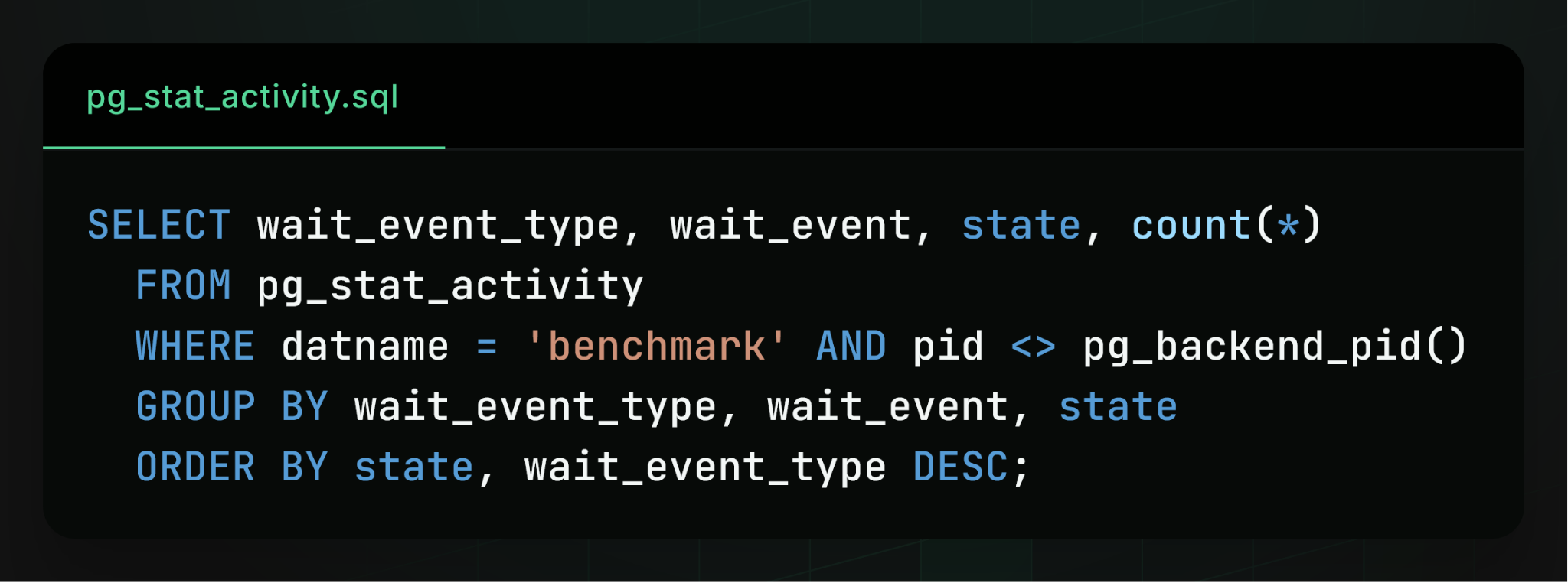
Top‑line metrics (CPU, IOPS) were not fully utilized, so we inspected the built‑in pg_stat_activity view to see what each backend process was doing:
The bottleneck turned out to be flushing the write‑ahead log (WAL) to disk.
When a write occurs, Postgres:
- Appends a description of the write to the WAL.
- Flushes the WAL to disk (via the
fsyncsystem call). - Acknowledges the commit to the client.
The actual data files are updated later in the background. This design maximizes performance because only the relatively cheap WAL write is done synchronously.
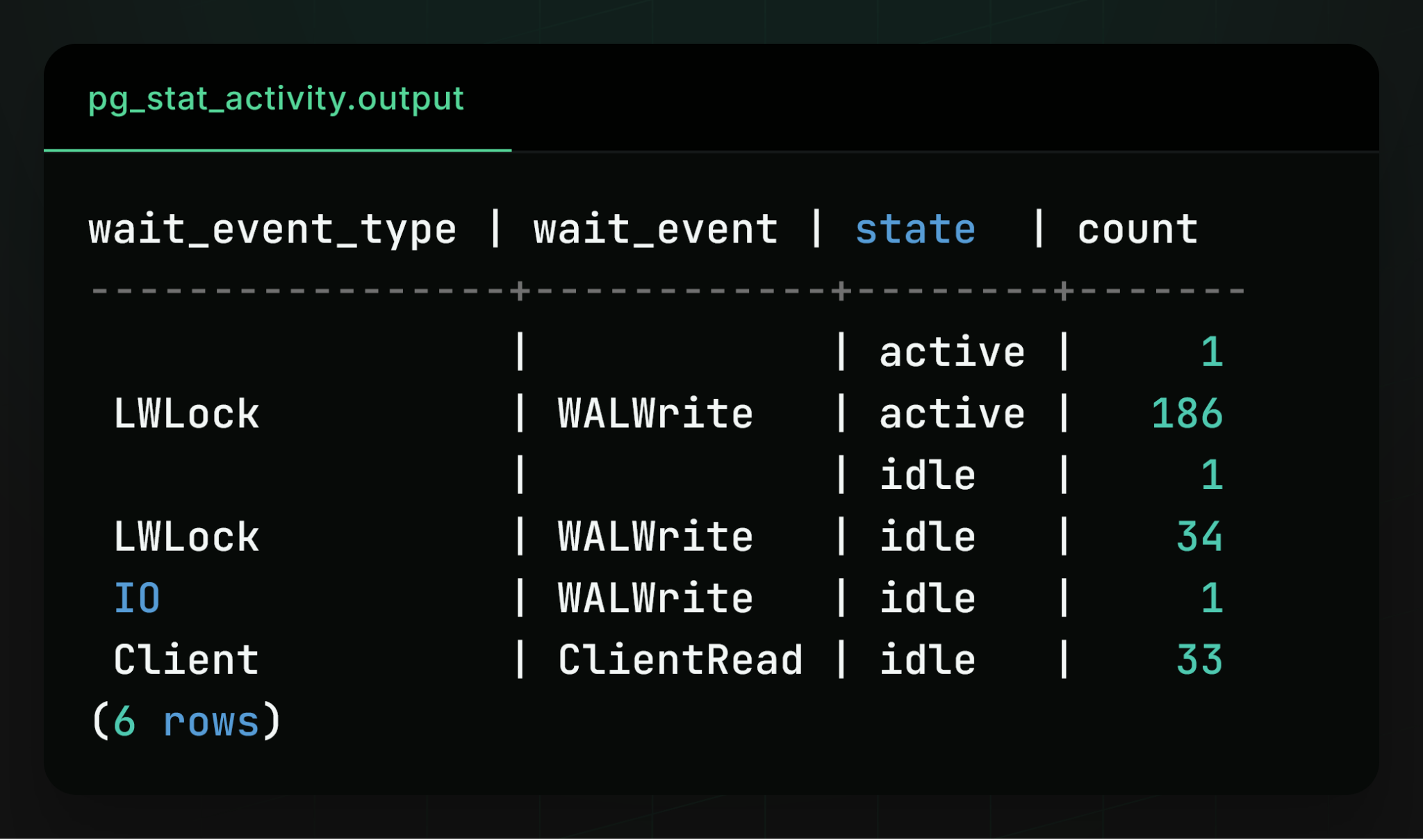
From the activity view we observed that exactly one process was flushing the WAL (in a group commit), while the vast majority of other processes were waiting on the WAL lock. This is a well‑known bottleneck for extremely write‑intensive workloads, because Postgres has a single WAL and every write must pass through it.
Durable‑Workflow Performance
A durable workflow performs exactly two Postgres writes:
- Start – creates the workflow entry and records its inputs & initial status.
- Completion – records the outcome and final status.
If a workflow has steps, it performs one additional write per step to checkpoint that step’s outcome.
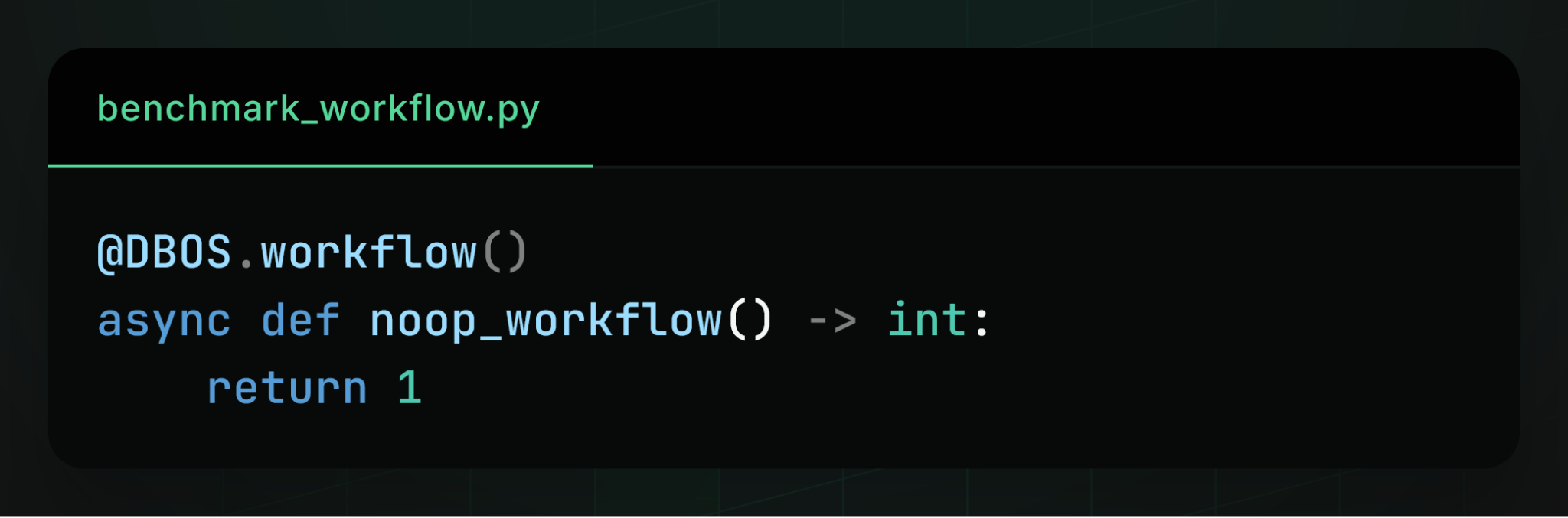
No‑op workflow benchmark
We evaluated simple no‑op workflows with no steps:
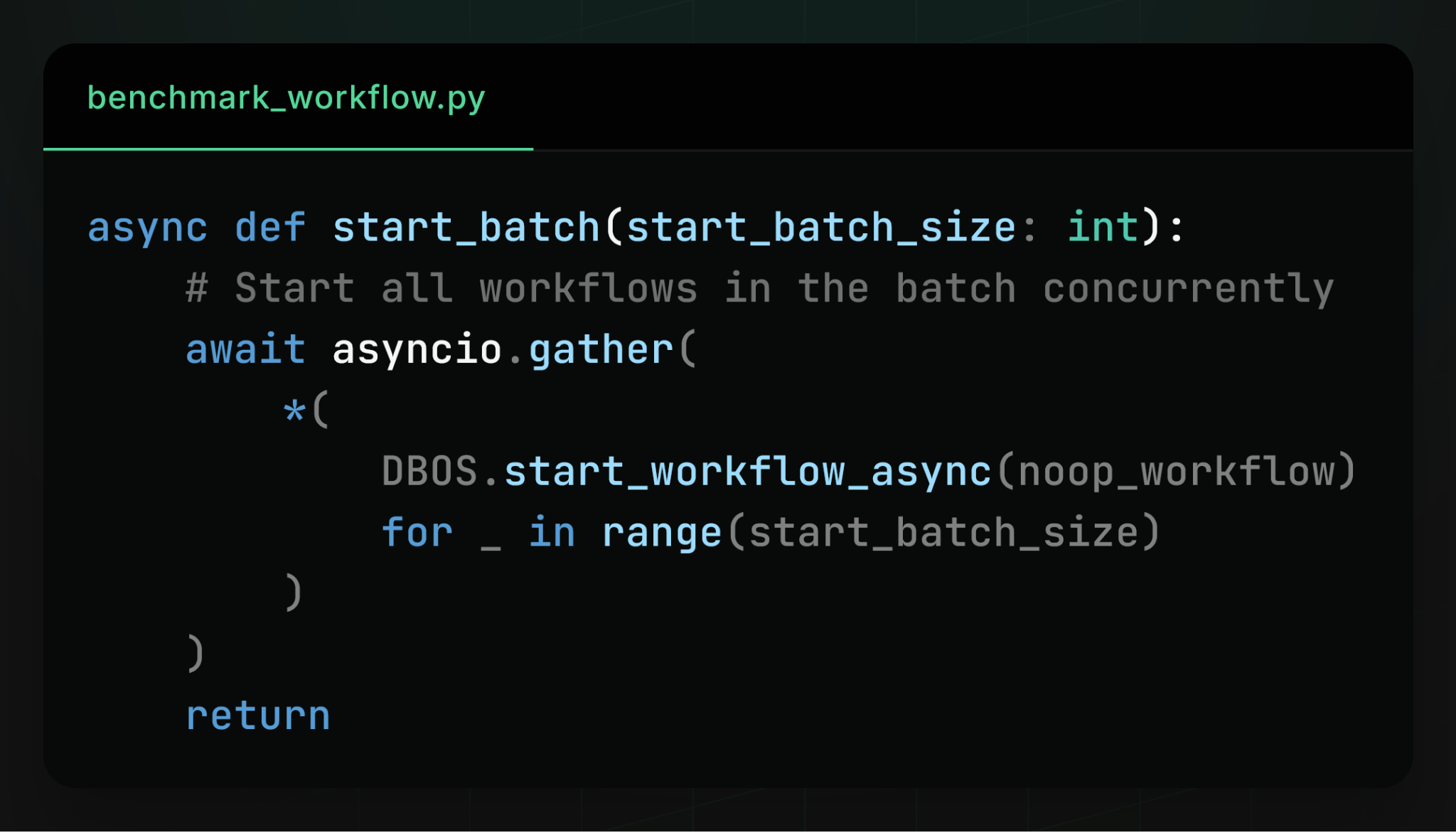
We started many workflows concurrently from many async Python clients:
Result: a single Postgres server can process up to 43 K workflows per second.
In other words, adding Postgres‑backed durability to an application executing 43 K workflows per second will not become a bottleneck.
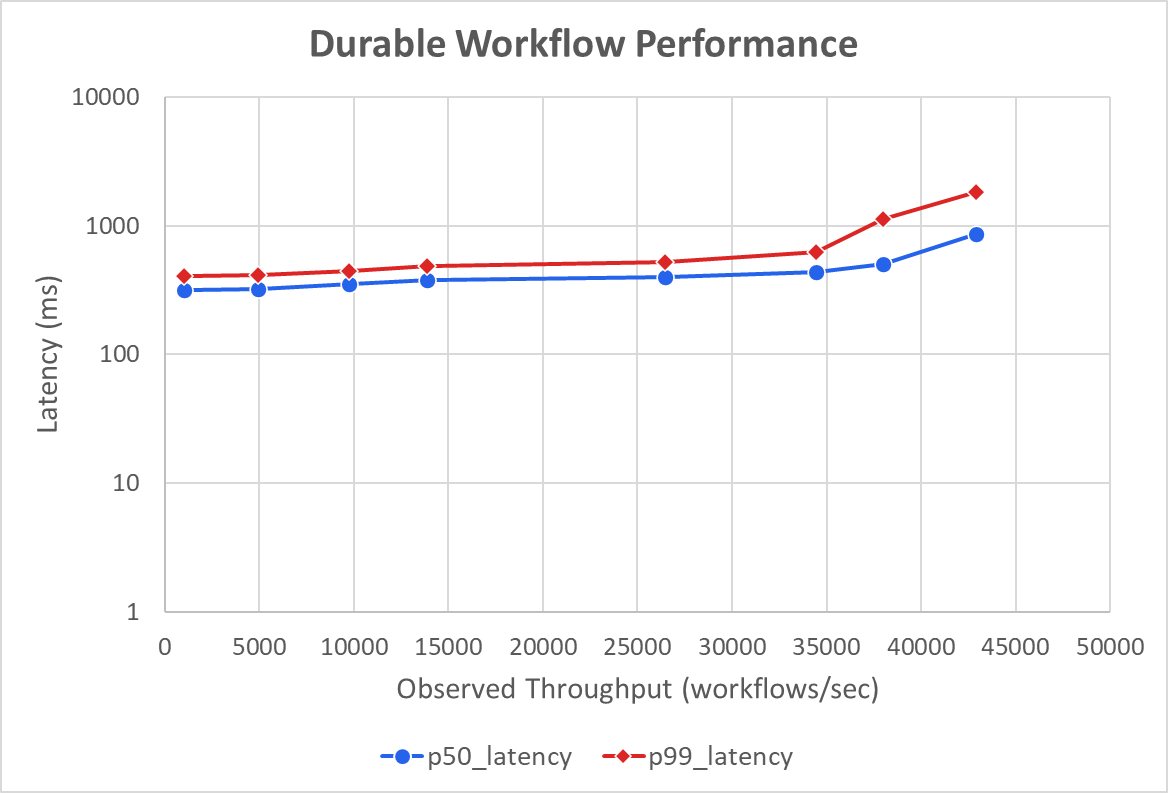
Bottleneck analysis
As with the raw INSERT benchmark, the limiting factor was the WAL: how quickly Postgres could commit workflow INSERTs and UPDATEs by flushing their WAL entries to disk. This is unsurprising because both workloads are completely write‑dominated.
Two factors explain the difference between raw INSERT performance and workflow performance:
- Additional UPDATE statements for workflow status changes add extra WAL traffic.
- Transaction overhead (starting/committing a transaction for each workflow step) introduces a small amount of extra latency.
Takeaways
- Postgres scales far beyond what most teams expect – a single high‑end instance can sustain hundreds of thousands of writes per second.
- The WAL is the primary bottleneck for write‑heavy workloads; understanding and tuning WAL behavior (e.g.,
wal_buffers,commit_delay,synchronous_commit) can push the limits even further. - For durable workflow systems, Postgres provides ample headroom – even at tens of thousands of workflows per second, the database does not become a performance limiter.
Feel free to explore the benchmark code and adapt it to your own workloads!
Durable Queues Performance
We next measure the scalability of Postgres‑backed queues. This is similar to the previous benchmark, but instead of directly executing workflows, clients enqueue them onto a Postgres queue. Workers then dequeue and execute them. This requires four Postgres writes per workflow:
- Enqueue – write to create the workflow entry and record its inputs & initial status.
- Dequeue – write to update the status (batched with all other workflows dequeued by the same executor at the same time).
- Start – write to update the status when the workflow begins execution.
- Complete – write to record the outcome and final status.
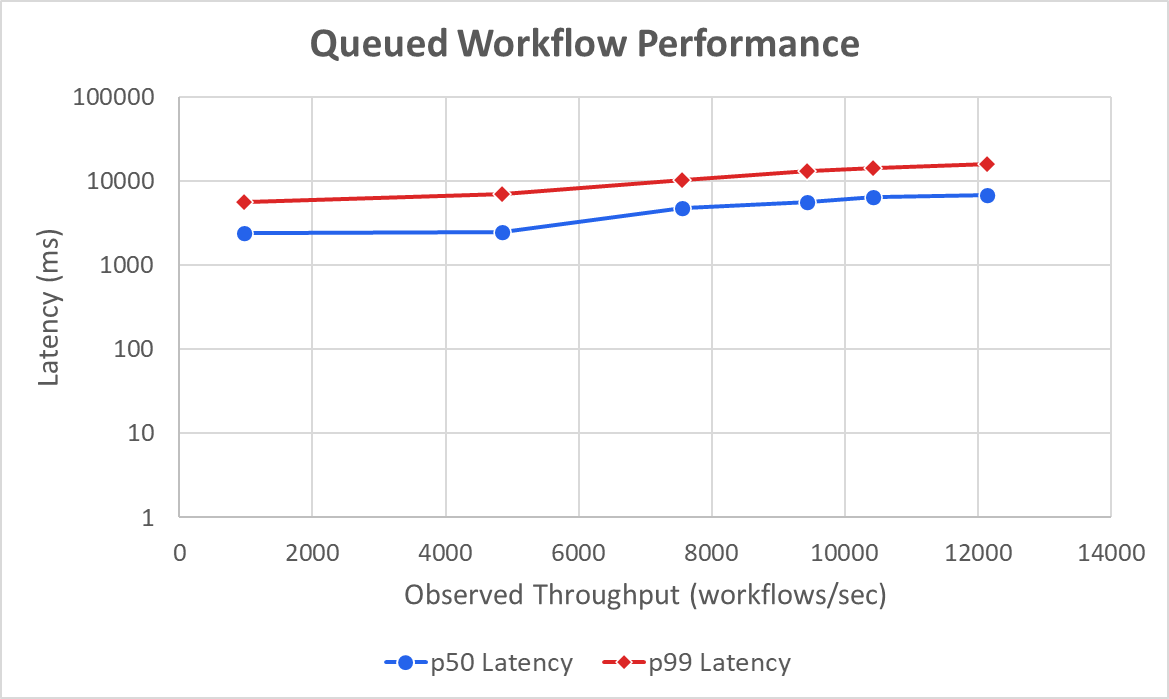
Overall, a single Postgres server can process up to 12.1 K queued workflows per second:
Bottleneck Analysis
The bottleneck this time was not the WAL but lock contention in the workflow_status table. All client processes were enqueueing to or dequeueing from the same few rows at the head of the queue, and contention limited performance (despite optimizations like SKIP LOCKED).
We hypothesize that this problem is exacerbated by Python’s relative inefficiency—many clients are needed to saturate Postgres. A faster language (e.g., Go) would require fewer clients and thus generate less dequeue contention.
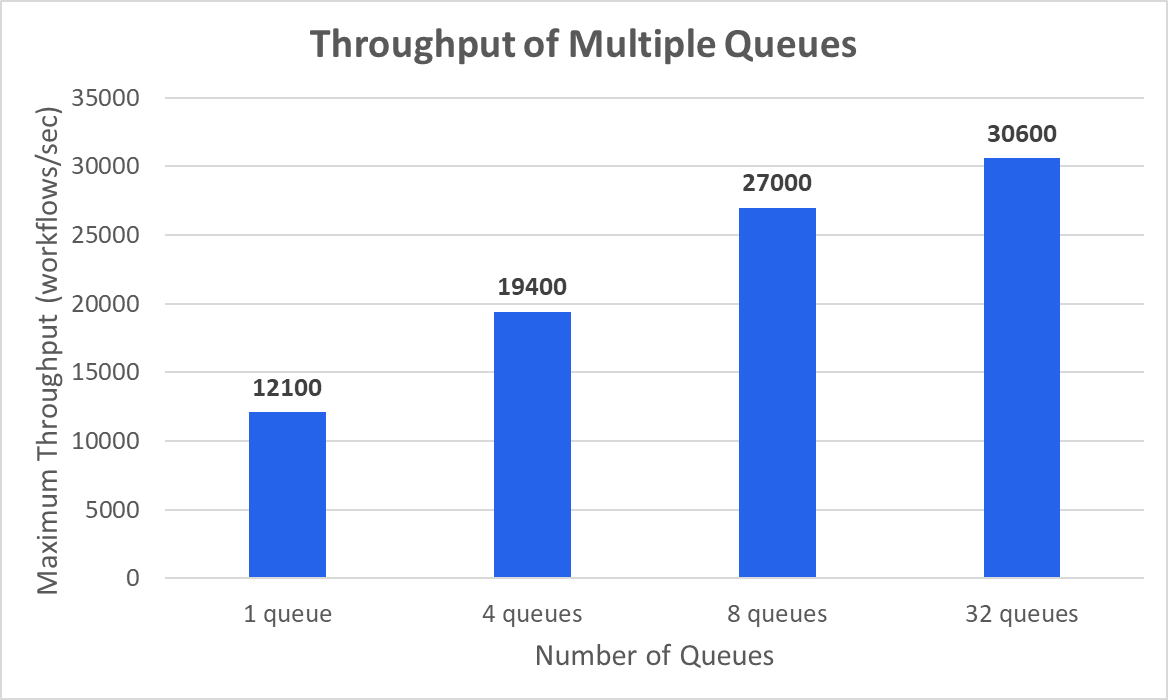
Scaling with Multiple Queues
To eliminate the contention bottleneck, we tested distributing work across multiple queues (or, equivalently, multiple partitions of the same queue). The maximum achievable workflow throughput increases with the number of queues, though with diminishing returns.
With enough queues/partitions, queued workflows achieve a throughput of 30.6 K workflows/sec—about two‑thirds of the 43 K workflows/sec achieved when directly starting workflows. This makes sense because queued workflows require more writes (three non‑batched + one batched vs. two non‑batched). At that scale, the database bottleneck again shifts to the WAL.
Summary
- A single Postgres server can perform 144 K small writes or process 43 K durable workflows per second.
- That translates to 12 billion writes or 4 billion workflows per day, sufficient for most applications.
- For higher performance, workloads can be sharded across multiple Postgres servers to handle virtually any load.
Learn More
If you enjoy building scalable, reliable systems, we’d love to hear from you. At DBOS, our goal is to make durable workflows as simple and performant as possible.
- Quickstart:
- GitHub:
- Discord community: