Antigravity: Beyond the Basics of AI Coding
Source: Dev.to
Antigravity: What Others Don’t Tell You
Writing software with AI can be as simple as it is complex. In this series I explore concepts that are essential for our daily workflow, using Antigravity as our primary tool for agentic development.
We often think we can just write a medium‑sized list of requirements, feed it to an AI, and get a perfect result. While this might work for simple solutions, it’s a bit like a junior developer from ten years ago who copies and pastes untested code that “just happens” to work.
Today I’ll show you how to manage development more efficiently by reusing patterns that actually work. I recently took an agentic‑coding course at my company and translated that knowledge into the Antigravity ecosystem. These principles are universal—you can apply them to any AI tool such as Codex, Claude Code, or GitHub Copilot.
Antigravity
If you haven’t installed Antigravity yet, you can do so via this download link or by following the official Google documentation. Antigravity is essentially a VS Code‑like IDE, integrated with advanced features Google has developed for us.
The standout feature is the integrated chat, sitting right next to your code. It’s not just a generic chat; it’s a contextualized chat. This brings us to a crucial topic: Context.
Google provides us with free models that we can use:
- Gemini 3 Pro (high)
- Gemini 3 Pro (low)
- Gemini 3 Flash
- Claude Sonnet 4.5
- Claude Sonnet 4.5 (thinking)
- Claude Opus 4.5 (thinking)
- GPT‑OSS
Obviously these have usage limits and must be used intelligently depending on the speed required, the quality of our data, and the complexity of the task.
Model Comparison
| Model | Context Window | Ideal Use Case | Reasoning | Speed |
|---|---|---|---|---|
| Gemini 3 Pro (high) | 2 M – 10 M | Science & massive repos | Maximum | Slow |
| Gemini 3 Pro (low) | 2 M – 10 M | Debugging & synthesis | Balanced | Medium |
| Gemini 3 Flash | 1 M | Automation & chat | Minimum | Ultra‑fast |
| Claude Sonnet 4.5 | 200 k+ | Coding & agents | High | Fast |
| Claude Sonnet 4.5 (thinking) | 200 k | Architecture & logic bugs | Extended | Slow |
| Claude Opus 4.5 (thinking) | 200 k | Strategy & research | Frontier | Very slow |
| GPT‑OSS | Custom | Privacy & local‑first | Variable | Local |
Note: These models have usage limits. Use them intelligently based on the required speed, quality, and complexity of your data.
Understanding Context
Context is the set of information we provide to a model alongside our query to get a relevant answer.
Naturally, the larger the context, the longer it takes for the model to respond. It is best to minimize context whenever possible to ensure fast, coherent responses. A bloated context can lead to hallucinations, a phenomenon often called “Lost in the Middle”—where the LLM loses focus or gets confused by the volume of data.
How Do I Reduce Context?
- Some agents handle this automatically.
- Others use “compact” instructions to summarize previous history, because the more we chat, the more the context grows. This concept is called Tokenization.
A token can be a character, a word, or a part of a word (like “‑tion”), depending on the model. For example, GPT‑4 (the model behind ChatGPT) breaks the phrase:
“I can’t wait to build AI applications”
into nine tokens, as shown below:

The JSON vs. Markdown Trick
A great way to understand how many tokens we are using is by using a tool such as tiktokenizer (or any similar tokenizer).
Tiktokenizer shows us how many tokens we are using, but not how we could save them.
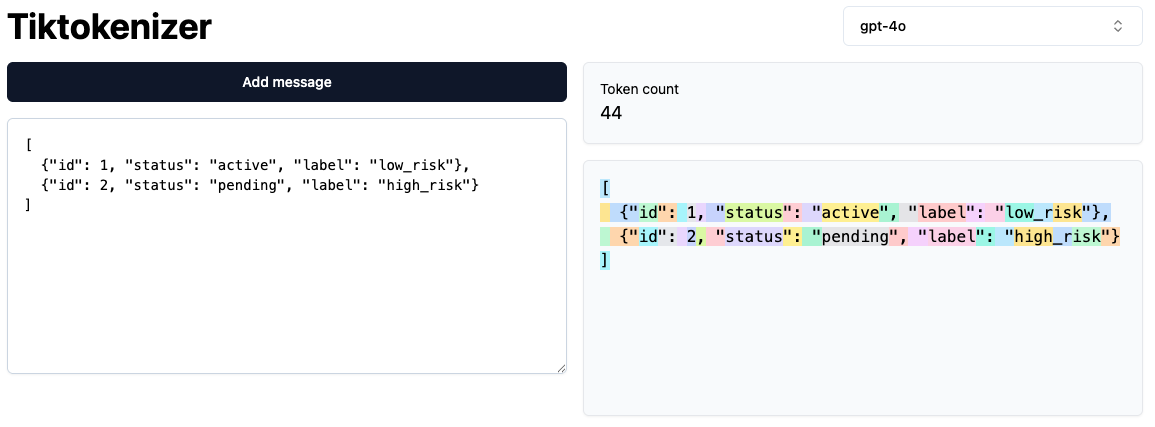
Example: JSON
[
{"id": 1, "status": "active", "label": "low_risk"},
{"id": 2, "status": "pending", "label": "high_risk"}
]This format counts as 44 tokens.
Convert to Markdown
By converting the same data to a Markdown table (or list), you almost always save tokens because you eliminate the syntax overhead (braces and repeated keys).
| id | status | label |
|----|---------|-----------|
| 1 | active | low_risk |
| 2 | pending | high_risk |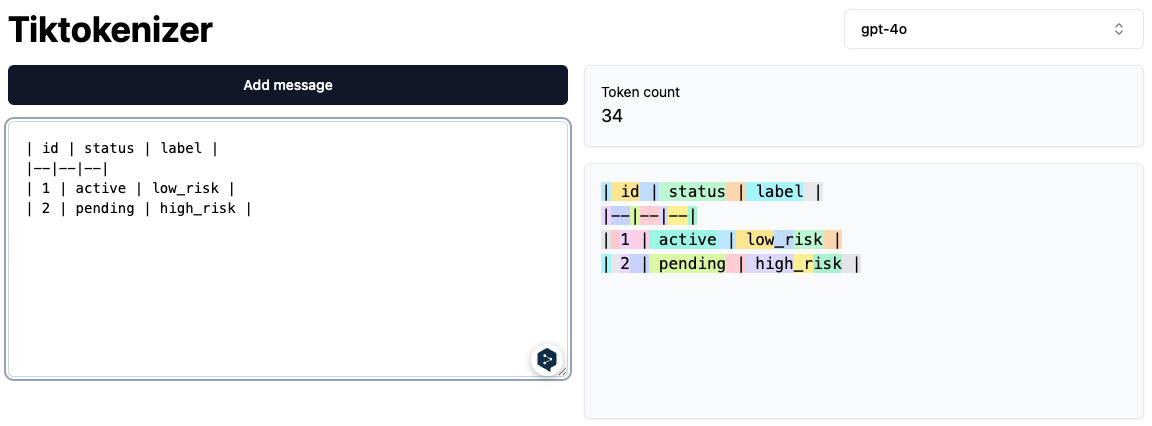
Avoid “TOON” Formats
While newer compression formats like “Toon” offer significant token savings, they aren’t always your best ally. LLMs are primarily trained on vast datasets of natural language, so feeding them heavily compressed or non‑standard representations can degrade performance or increase hallucination risk.
End of cleaned‑up markdown segment.
e and established standards. Moving away from these “standard” patterns in favor of niche formats can actually degrade the model’s reasoning performance.
Tips and Tricks
As a final tip for this first installment of Antigravity: What others don’t tell you, I highly recommend the Antigravity Cockpit extension. It provides an intuitive dashboard with infographics to monitor your remaining usage limits for each model.

See you in the next one! 👋🏻