알리바바, 35시간 연속 자율 수행 AI ‘Qwen3.7-Max’ 공개…오픈소스 대신 유료 API 사용 가능
Source: VentureSquare





알리바바가 35시간 연속 자율 작업이 가능한 최신 대형언어모델 ‘Qwen3.7-Max’를 선보였다. 앤스로픽 API 프로토콜을 기본 지원해 클로드 코드(Claude Code), 오픈클로(OpenClaw) 등과 즉각 연동되는 것이 강점이다. 다만 이전 시리즈와 달리 오픈소스가 아닌 유료 API 방식으로 전환해 개발자 커뮤니티의 엇갈린 반응을 얻고 있다.
![[알리바바], 35시간 연속 자율 수행 AI ‘Qwen3.7-Max’ 공개…오픈소스 대신 API 유료화 선택](https://www.venturesquare.net/wp-content/uploads/2026/05/qwen3.7-max-banner.png)
이미지 출처: Qwen 공식 블로그
중국 빅테크 기업 알리바바(Alibaba)의 AI 연구팀 큐원(Qwen)이 최장 35시간 연속 자율 작업을 수행할 수 있는 최신 인공지능 모델 ‘Qwen3.7-Max’를 공개했다.
AI 산업이 단순 텍스트 생성을 넘어 스스로 계획을 세우고 실행하며 궤도를 수정하는 ‘에이전트(Agent)’ 시대로 진입한 가운데, 이번 모델은 ‘장기 추론(long-horizon reasoning)’ 기능에 특화된 것이 특징이다. 언어모델이 수천 번의 대화 턴을 넘기면 지시사항을 잊거나 논리 루프에 빠지는 병목 현상을 극복하도록 설계됐다.
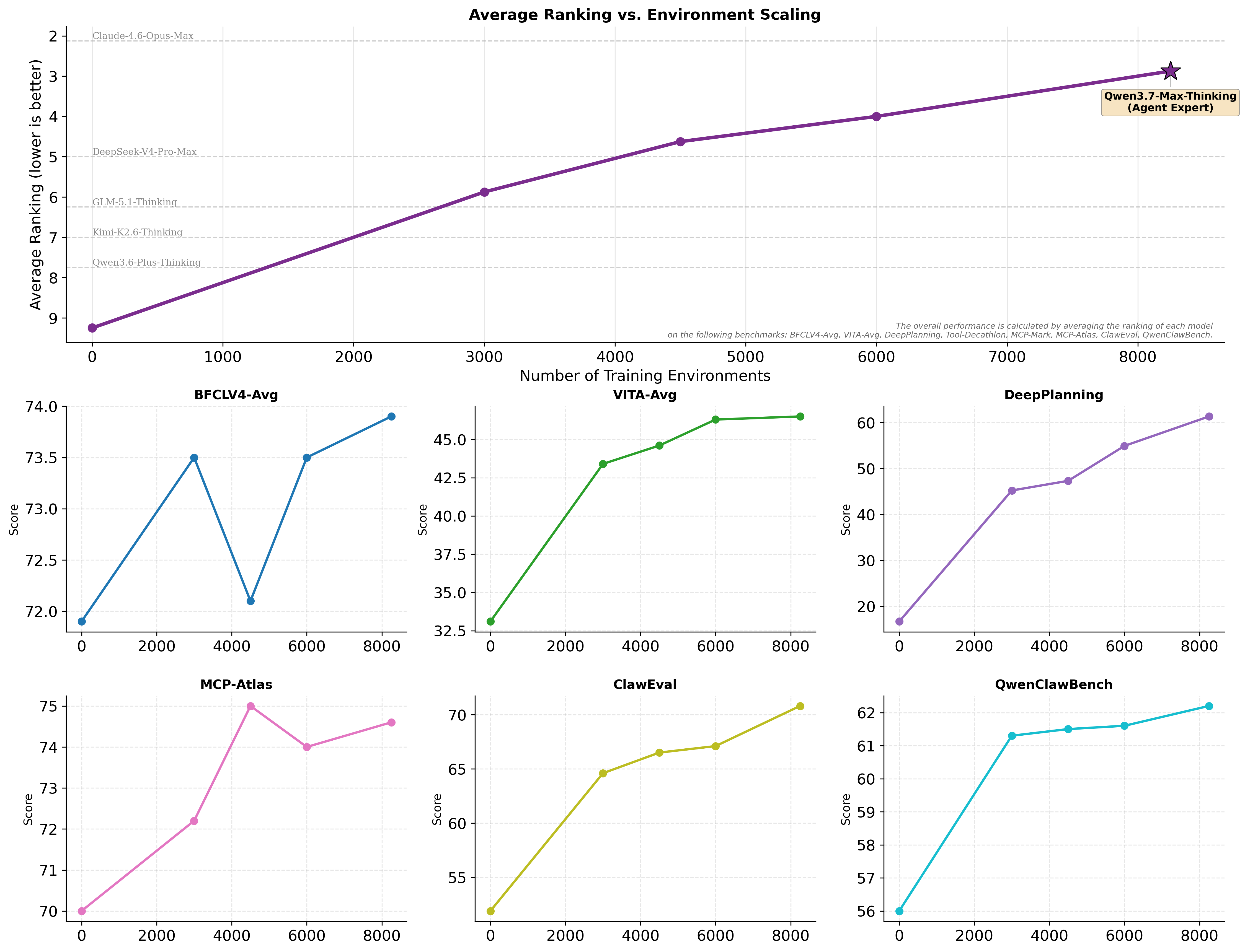
큐원 팀에 따르면 Qwen3.7-Max는 학습된 적 없는 서버 환경(T-Head ZW-M890 PPU)에서 주의력 커널(attention kernel) 최적화 임무를 35시간 동안 자율적으로 수행했다. 이 과정에서 도구 호출 1,158회, 커널 평가 432회를 진행하고 컴파일 오류를 스스로 진단 및 수정하여 10배의 속도 향상을 기록했다. 이는 7.3배와 5배 향상에 그친 뒤 스스로 세션을 종료한 중국 동종 업계의 GLM-5.1, Kimi K2.6을 상회하는 수치다.
이미지 출처: Qwen 공식 블로그
이러한 내구성은 ‘환경 확장(environment scaling)’ 학습에 기반한다. Qwen3.7-Max는 스타트업의 1년 주기를 시뮬레이션하는 ‘YC-Bench’ 평가에서 인사 관리와 계약 검토 등 수백 번의 의사결정 라운드를 거쳐 이전 세대(Qwen3.6-Plus) 대비 두 배에 가까운 208만 달러의 가상 수익을 창출해냈다. 또 훈련 환경을 속이려 할 때 이를 자율적으로 감지하고 스스로 규칙을 추가해 행동을 수정하는 자체 모니터링 기능도 내장했다.
이미지 출처: Qwen 공식 블로그
범용성을 극대화한 ‘크로스 하네스 일반화(cross-harness generalization)’도 눈에 띈다. 100만 토큰의 방대한 컨텍스트 윈도우를 바탕으로, 특정 독점 인터페이스에 얽매이지 않고 앤스로픽(Anthropic) API 프로토콜을 네이티브로 지원한다. 이를 통해 개발자는 ‘클로드 코드(Claude Code)’나 ‘오픈클로(OpenClaw)’ 같은 기존 외부 에이전트 프레임워크에 모델을 즉각 연동할 수 있다.
이 같은 범용 접근 방식은 벤치마크 결과로도 나타났다. 수학적 추론을 평가하는 Apex Math에서 44.5점을 받아 클로드 오퍼스 4.6 맥스(34.5점)를 앞섰으며, 현실 코딩 에이전트 벤치마크인 MCP-Atlas에서도 76.4점의 높은 점수를 기록했다.
업계의 관심은 새로운 배포 방식에 쏠리고 있다. 알리바바는 앞서 Qwen 2.5, Qwen 3.6 등 주요 모델의 가중치를 공개하며 오픈소스 생태계를 이끌어왔다. 하지만 이번 3.7-Max는 철저히 상업적 API(API-only)로만 제공된다. 이는 오픈AI(OpenAI)나 앤스로픽처럼 폐쇄적 수익 모델로 선회한 것을 의미하며, 로컬 환경에서 최고 수준의 모델을 구동하려던 개발자 및 오픈소스 커뮤니티 사이에서는 아쉬움 섞인 반응이 나온다.
다만 비용 측면에서는 전략적인 가격표를 달았다. 알리바바 클라우드 모델 스튜디오를 통한 이용 요금은 100만 토큰당 입력 2.50달러, 출력 7.50달러다. 중국 경쟁 모델인 딥시크 V4 Pro, GLM-5.1보다는 높은 금액이지만, 무거운 에이전트 워크플로우를 처리할 때 100만 토큰당 17~30달러가 소요되는 미국의 프론티어급 모델(GPT-5.4, 클로드 오퍼스 4.7 등) 가격을 크게 밑돌며 글로벌 엔터프라이즈 수요를 노리고 있다.
출처: Qwen 공식 블로그
Alibaba Unveils ‘Qwen3.7-Max,’ AI for 35 Hours of Continuous Autonomous Operation… Paid API Available Instead of Open Source
Image source: Qwen official blog
Qwen, the AI research team of Chinese big tech company Alibaba, has unveiled its latest artificial intelligence model, ‘Qwen3.7-Max,’ capable of performing autonomous tasks for up to 35 hours continuously.
As the AI industry enters the era of ‘Agents’ that move beyond simple text generation to autonomously plan, execute, and correct their course, this model is characterized by its specialization in ‘long-horizon reasoning.’ It is designed to overcome bottlenecks where language models forget instructions or fall into logical loops after thousands of conversation turns.
According to the Qwen team, Qwen3.7-Max autonomously performed an attention kernel optimization task for 35 hours in an untrained server environment (T-Head ZW-M890 PPU). During this process, it performed 1,158 tool calls and 432 kernel evaluations, and self-diagnosed and corrected compilation errors, recording a 10x speed improvement. This surpasses the performance of its Chinese competitors, GLM-5.1 and Kimi K2.6, which ended their sessions on their own after achieving only 7.3x and 5x improvements, respectively.
Image source: Qwen official blog
This durability is based on ‘environment scaling’ learning. In the ‘YC-Bench’ evaluation, which simulates a one-year startup cycle, Qwen3.7-Max generated $2.08 million in virtual revenue—nearly double that of the previous generation (Qwen3.6-Plus)—through hundreds of decision-making rounds, including HR management and contract reviews. It also features built-in self-monitoring capabilities that autonomously detect attempts to cheat the training environment and modify behavior by adding its own rules.
Image source: Qwen official blog
The ‘cross-harness generalization,’ which maximizes universality, also stands out. Based on a vast context window of 1 million tokens, it natively supports the Anthropic API protocol
without being tied to specific proprietary interfaces. This allows developers to immediately integrate models with existing external agent frameworks such as Claude Code or OpenClaw.
This general-purpose approach was also reflected in benchmark results. It received 44.5 points in Apex Math, which evaluates mathematical reasoning, surpassing Claude Opus 4.6 Max (34.5 points), and recorded a high score of 76.4 points in MCP-Atlas, a reality coding agent benchmark.
Industry attention is focused on the new distribution method. Alibaba has previously led the open-source ecosystem by releasing weights for major models such as Qwen 2.5 and Qwen 3.6. However, this 3.7-Max is being provided strictly as a commercial API (API-only). This signifies a shift toward a closed revenue model similar to OpenAI or Anthropic, drawing disappointed reactions from developers and the open-source community who had hoped to run top-tier models in local environments.
However, in terms of cost, it has adopted a strategic pricing strategy. The usage fee through Alibaba Cloud Model Studio is $2.50 for input and $7.50 for output per million tokens. While this is higher than competing Chinese models such as DeepSeak V4 Pro and GLM-5.1, it is significantly lower than the prices of US frontier models (GPT-5.4, Claude Opus 4.7, etc.) that cost $17 to $30 per million tokens to handle heavy agent workflows, targeting global enterprise demand.
Source: Qwen Official Blog
アリババ、35時間連続自律遂行AI「Qwen3.7-Max」公開…オープンソースの代わりに有料APIが利用可能
画像ソース:Qwen公式ブログ
中国ビッグテック企業アリババ(Alibaba)のAI研究チームのキューワン(Qwen)が最長35時間連続自律作業を行うことができる最新の人工知能モデル「Qwen3.7-Max」を公開した。
AI産業が単純テキスト生成を超えて自ら計画を立てて実行し、軌道を修正する「エージェント(Agent)」時代に進入した中で、今回のモデルは「長期推論(long-horizon reasoning)」機能に特化したのが特徴だ。言語モデルが数千回の対話ターンを超えると、指示を忘れたり、論理ループに陥るボトルネックを克服するように設計された。
キューワンチームによると、Qwen3.7-Maxは学習したことのないサーバー環境(T-Head ZW-M890 PPU)で注意カーネル最適化ミッションを35時間自律的に行った。この過程でツール呼び出し1,158回、カーネル評価432回を進行し、コンパイルエラーを自ら診断・修正し、10倍の速度向上を記録した。これは7.3倍と5倍の向上にとどまった後、自らセッションを終了した中国同種業界のGLM-5.1, Kimi K2.6を上回る数値だ。
画像ソース:Qwen公式ブログ
この耐久性は「環境の拡大」学習に基づいています。 Qwen3.7-Maxはスタートアップの1年周期をシミュレートする「YC-Bench」評価で人事管理や契約検討など数百回の意思決定ラウンドを経て、前世代(Qwen3.6-Plus)に比べて2倍に近い208万ドルの仮想収益を創出した。また、訓練環境を欺く際に、これを自律的に感知し、自らルールを追加して行動を修正する自己監視機能も内蔵した。
画像ソース:Qwen公式ブログ
汎用性を最大化した「クロスハーネス一般化(cross-harness generalization)」も目立つ。 100万トークンの膨大なコンテキストウィンドウに基づいて、特定の独占インターフェイスに縛られずにアンスロピックAPIプロトコルをネイティブにサポートする。これにより、開発者は「Claude Code」や「OpenClaw」などの既存の外部エージェントフレームワークにモデルを即座に連動することができる。
このような汎用アプローチはベンチマークの結果としても現れた。数学的推論を評価するApex Mathで44.5点を獲得し、クロードオファース4.6マックス(34.5点)を上回り、現実コーディングエージェントベンチマークであるMCP-Atlasでも76.4点の高いスコアを記録した。
業界の関心は新しい配布方式に注目されている。アリババは、先にQwen 2.5、Qwen 3.6など主要モデルの重みを公開し、オープンソース生態系を導いてきた。しかし今回の3.7-Maxは徹底的に商業API(API-only)でしか提供されない。これはオープンAI(OpenAI)やアンスロピックのように閉鎖的収益モデルに旋回したことを意味し、ローカル環境で最高レベルのモデルを駆動しようとしていた開発者とオープンソースコミュニティの間では物足りなさ反応が出てくる。
ちょうど費用の面では戦略的な価格表を付けた。アリババクラウドモデルスタジオによる利用料金は100万トークン当たり入力2.50ドル、出力7.50ドルだ。中国競争モデルであるディープシークV4 Pro、GLM-5.1よりは高い金額だが、重いエージェントワークフローを処理する際に100万トークン当たり17~30ドルを要する米国のフロンティア級モデル(GPT-5.4、クロードオファーズ4.7など)価格を大きく下回りグローバル。
出典: Qwen公式ブログ
阿里巴巴发布“Qwen3.7-Max”,人工智能可连续自主运行35小时……提供付费API而非开源版本
图片来源:Qwen官方博客
中国大型科技公司阿里巴巴旗下的人工智能研究团队Qwen发布了其最新的人工智能模型“Qwen3.7-Max”,该模型能够连续执行长达35小时的自主任务。
随着人工智能行业进入“智能体”时代,智能体不再局限于简单的文本生成,而是能够自主地规划、执行和纠正自身行为,该模型的特点是专注于“长远推理”。它的设计目的是为了克服语言模型在数千次对话后忘记指令或陷入逻辑循环的瓶颈。
据Qwen团队称,Qwen3.7-Max在未经训练的服务器环境(T-Head ZW-M890 PPU)下自主执行了35小时的注意力内核优化任务。在此期间,它执行了1158次工具调用和432次内核评估,并能够自我诊断和纠正编译错误,实现了10倍的速度提升。这一成绩超越了其国内竞争对手GLM-5.1和Kimi K2.6,后两者分别仅实现了7.3倍和5倍的性能提升便自行结束了测试。
图片来源:Qwen官方博客
这种持久性源于“环境扩展”学习。在模拟一年创业周期的“YC-Bench”评估中,Qwen3.7-Max 通过数百轮决策(包括人力资源管理和合同审查)产生了 208 万美元的虚拟收入,几乎是上一代产品(Qwen3.6-Plus)的两倍。它还内置了自我监控功能,能够自主检测试图作弊的行为,并通过添加自身规则来修正行为。
图片来源:Qwen官方博客
“跨框架泛化”功能也十分突出,它最大限度地提高了通用性。该功能基于包含 100 万个令牌的庞大上下文窗口,原生支持 Anthropic API 协议,而无需依赖任何特定的专有接口。这使得开发者能够立即将模型与现有的外部代理框架(例如 Claude Code 或 OpenClaw)集成。
这种通用方法也体现在基准测试结果中。它在评估数学推理能力的 Apex Math 测试中获得了 44.5 分,超过了 Claude Opus 4.6 Max(34.5 分),并在现实编码代理基准测试 MCP-Atlas 中取得了 76.4 分的高分。
业界关注的焦点集中在新的分发方式上。阿里巴巴此前曾引领开源生态系统,发布了 Qwen 2.5 和 Qwen 3.6 等主要模型的权重。然而,此次发布的 3.7-Max 模型却仅以商业 API(仅限 API)的形式提供。这标志着阿里巴巴正转向类似 OpenAI 或
Anthropic 的封闭式盈利模式,令原本希望在本地环境中运行顶级模型的开发者和开源社区感到失望。
然而,在成本方面,它采取了策略性的定价方式。通过阿里云模型工作室使用,每百万代币的输入费用为 2.5 美元,输出费用为 7.5 美元。虽然这高于 DeepSeak V4 Pro 和 GLM-5.1 等中国同类产品,但远低于美国前沿模型(如 GPT-5.4、Claude Opus 4.7 等)的价格。这些美国模型处理繁重的代理工作流,面向全球企业需求,每百万代币的费用高达 17 至 30 美元。
来源: Qwen官方博客
Alibaba dévoile « Qwen3.7-Max », une IA permettant 35 heures de fonctionnement autonome continu… Une API payante est disponible à la place d’une version open source.
Source de l’image : blog officiel de Qwen
Qwen, l’équipe de recherche en IA de la société technologique chinoise Alibaba, a dévoilé son dernier modèle d’intelligence artificielle, « Qwen3.7-Max », capable d’effectuer des tâches autonomes pendant 35 heures en continu.
Alors que l’industrie de l’IA entre dans l’ère des « agents » qui dépassent la simple génération de texte pour planifier, exécuter et corriger leur trajectoire de manière autonome, ce modèle se caractérise par sa spécialisation dans le « raisonnement à long terme ». Il est conçu pour surmonter les goulots d’étranglement où les modèles de langage oublient des instructions ou tombent dans des boucles logiques après des milliers d’échanges de conversation.
Selon l’équipe Qwen, Qwen3.7-Max a réalisé de manière autonome une tâche d’optimisation du noyau d’attention pendant 35 heures sur un serveur non entraîné (T-Head ZW-M890 PPU). Durant ce processus, il a effectué 1 158 appels d’outils et 432 évaluations de noyau, et a auto-diagnostiqué et corrigé les erreurs de compilation, enregistrant ainsi une amélioration de vitesse de 10x. Ce résultat surpasse les performances de ses concurrents chinois, GLM-5.1 et Kimi K2.6, qui ont interrompu leurs sessions après avoir atteint respectivement des améliorations de 7,3x et 5x.
Source de l’image : blog officiel de Qwen
Cette robustesse repose sur l’apprentissage par « mise à l’échelle de l’environnement ». Lors de l’évaluation « YC-Bench », qui simule le cycle de vie d’une startup sur un an, Qwen3.7-Max a généré 2,08 millions de dollars de revenus virtuels – près du double de ceux de la génération précédente (Qwen3.6-Plus) – grâce à des centaines de cycles de décision, incluant la gestion des ressources humaines et l’examen des contrats. Elle intègre également des fonctionnalités d’autocontrôle qui détectent automatiquement les tentatives de manipulation de l’environnement de formation et adaptent le comportement en ajoutant ses propres règles.
Source de l’image : blog officiel de Qwen
La « généralisation inter-harness », qui maximise l’universalité, est également remarquable. S’appuyant sur une vaste fenêtre contextuelle d’un million de jetons, elle prend en charge nativement le protocole API Anthropic sans être liée à des interfaces propriétaires spécifiques. Les développeurs peuvent ainsi intégrer immédiatement leurs modèles aux frameworks d’agents externes existants, tels que Claude Code ou OpenClaw.
Cette approche généraliste s’est également reflétée dans les résultats des tests de référence. Elle a obtenu 44,5 points à Apex Math, qui évalue le raisonnement mathématique, surpassant Claude Opus 4.6 Max (34,5 points), et a enregistré un score élevé de 76,4 points à MCP-Atlas, un test de référence pour agents de codage de la réalité.
L’attention du secteur se porte sur cette nouvelle méthode de distribution. Alibaba a jusqu’à présent joué un rôle moteur dans l’écosystème open source en publiant les pondérations de modèles majeurs tels que Qwen 2.5 et Qwen 3.6. Cependant, cette version 3.7-Max est proposée exclusivement via une API commerciale. Ce choix marque un tournant vers un modèle économique fermé, à l’instar d’OpenAI ou d’Anthropic, et suscite la déception des développeurs et de la communauté open source qui espéraient pouvoir exécuter des modèles de pointe en local.
Cependant, en termes de coûts, Alibaba Cloud Model Studio a adopté une stratégie tarifaire avantageuse. Les frais d’utilisation s’élèvent à 2,50 $ pour l’entrée et à 7,50 $ pour la sortie par million de jetons. Bien que ce tarif soit supérieur à celui des modèles chinois concurrents tels que DeepSeak V4 Pro et GLM-5.1, il reste nettement inférieur à celui des modèles américains de pointe (GPT-5.4, Claude Opus 4.7, etc.) dont le coût oscille entre 17 et 30 $ par million de jetons pour la gestion de flux de travail complexes impliquant de nombreux agents, ciblant ainsi la demande des entreprises internationales.
Source : Blog officiel de Qwen