16 Performance Boost and 98% Cost Reduction: A Dive into the Upgraded SLS Vector Indexing Architecture
Source: Dev.to
Cost and Throughput Challenges of Vector Indexing in Log Scenarios
In semantic indexing, the embedding process is the key factor that determines the semantic recall rate. Throughout the entire semantic indexing pipeline, embedding also represents a core cost component.
- Cost: Embedding 1 GB of data can cost several hundred CNY.
- Speed: The throughput is limited to about 100 KB/s.
In comparison, the costs of index construction and storage are negligible. The inference efficiency of embedding models on GPUs directly determines the speed and total cost of building a semantic index.
For knowledge‑base scenarios, such costs may be acceptable because the data is relatively static and infrequently updated. However, for Simple Log Service (SLS) streaming data, new data is continuously generated, creating significant pressure on both performance and cost. With a few hundred CNY per gigabyte and a throughput of only 100 KB/s, this performance is unsustainable for production workloads.
To improve performance and cost efficiency for large‑scale applications, we conducted systematic optimizations targeting the inference bottlenecks of the embedding service. Through in‑depth analysis, solution selection, and customized improvements, we achieved a 16× increase in throughput while significantly reducing resource costs per request.
Technical Challenges and Optimization Strategies
To achieve optimal cost‑efficiency of the embedding service, we needed to address the following key challenges:
1. Inference Framework
Multiple inference frameworks exist on the market—vLLM, SGLang, llama.cpp, TensorRT, sentence‑transformers—each with different focuses (general‑purpose vs. specialized, CPU vs. GPU). Selecting a framework that best fits embedding workloads and maximizes hardware (especially GPU) performance is crucial.
The intrinsic computational efficiency of a framework for tasks such as continuous batch processing and kernel optimization can become an inference performance bottleneck for embedding models.
2. Maximizing GPU Utilization
GPU resources are expensive; under‑utilizing them is wasteful. This differs markedly from the CPU era.
- Batch processing: Embedding inference is highly sensitive to batch size. Processing a single request is far less efficient than batch processing. An efficient request‑batching mechanism is essential.
- Parallel processing: CPU preprocessing (e.g., tokenization), network I/O, and GPU computation must be fully decoupled and parallelized to prevent GPU idle time.
- Multiple model replicas: Unlike large chat models with massive parameters, typical embedding models have fewer parameters. A single replica on an A10 GPU may use only ~15 % of compute power and ~13 % of GPU memory. Deploying multiple model replicas on a single GPU to “use up” the resources is crucial for reducing costs and improving throughput.
3. Priority‑Based Scheduling
Semantic indexing involves two stages:
| Stage | Batch size | Priority |
|---|---|---|
| Index construction | Large | Low |
| Online query | Small | High (real‑time) |
It is essential to ensure that embedding tasks for query requests are not blocked by construction tasks. A fine‑grained priority‑queue scheduling mechanism is required—simple resource‑pool isolation is insufficient.
4. Bottlenecks in the End‑to‑End Pipeline
After GPU utilization improves, other parts of the pipeline (e.g., tokenization) may become new bottlenecks.
Solution
We eventually implemented the following optimization solution.

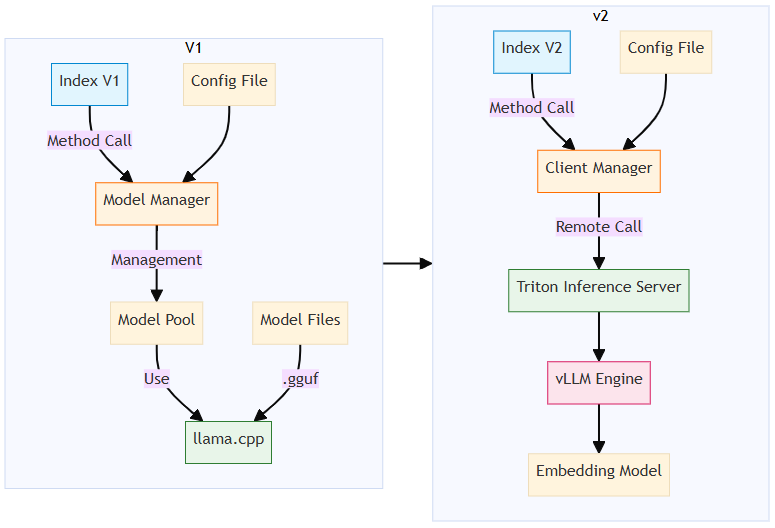
Optimization 1 – Selecting vLLM as the Core Inference Engine (Replacing llama.cpp)
-
Why we switched:
- Our initial choice of llama.cpp was based on its high C++ performance, CPU friendliness (some tasks run on CPU nodes), and ease of integration.
- Recent tests showed that, under identical hardware, vLLM (or SGLang) delivered 2× higher throughput than llama.cpp, while average GPU utilization was 60 % lower.
- The key difference lies in vLLM’s Continuous Batching mechanism and its highly optimized CUDA kernels.
-
Deployment change:
- We separated the embedding module into an independent service and deployed it on Elastic Algorithm Service (EAS) of Platform for AI (PAI).
- Both vector construction and query operations now obtain embeddings via remote calls.
- Although this introduces network overhead and additional O&M costs, it provides a substantial baseline performance boost and a solid foundation for further optimizations.
Optimization 2 – Deploying Multiple Model Replicas on a Single GPU
- Goal: Improve GPU utilization by running several model replicas on one A10 GPU.
- Chosen framework: Triton Inference Server.
- Allows easy control of the number of model replicas per GPU.
- Provides scheduling and dynamic batching capabilities to route requests to different replicas.
- Implementation detail: Bypassed the vLLM HTTP server and invoked the vLLM core library (
LLMEngine) directly in Triton’s Python backend, reducing overhead.
Optimization 3 – Decoupling Tokenization from Model Inference
- Problem discovered: With multiple vLLM replicas, tokenization became the new performance bottleneck after GPU throughput was improved.
- Solution: (Continuation of the original text)
[The original content was truncated here; the remaining steps would describe how tokenization was offloaded to a separate service or parallelized, the use of fast tokenizers, and any caching mechanisms employed.]
Result
- Throughput: Increased by ~16× compared with the baseline.
- Cost per request: Significantly reduced thanks to higher GPU utilization and fewer idle resources.
- Scalability: The system now handles continuous log streams in production without the previous performance or cost constraints.
Optimization 4 – Priority Queuing and Dynamic Batching
- Triton Inference Server comes with a built‑in priority‑queuing mechanism and a dynamic‑batching mechanism, which align perfectly with the requirements of the embedding service.
- Embedding requests during query operations are assigned a higher priority to reduce query latency.
- Dynamic batching groups incoming requests into batches, improving overall throughput efficiency.
Final Architecture Design
After addressing the performance bottlenecks of embedding, it was also necessary to refactor the overall semantic‑indexing architecture. The system needed to:
- Switch to calling remote embedding services.
- Enable full asynchronization and parallelization across the data‑reading, chunking, embedding‑request, and result‑processing/storage steps.
Embedding Calls
In the previous architecture, the embedded llama.cpp engine was invoked directly for embedding. In the new architecture, embedding is performed through remote calls.
Full Asynchronization and Parallelization
The old architecture processed data parsing → chunking → embedding sequentially, preventing the GPU‑based embedding service from reaching full load.
The new design implements full asynchronization and parallelization, efficiently utilizing network I/O, CPU, and GPU resources.
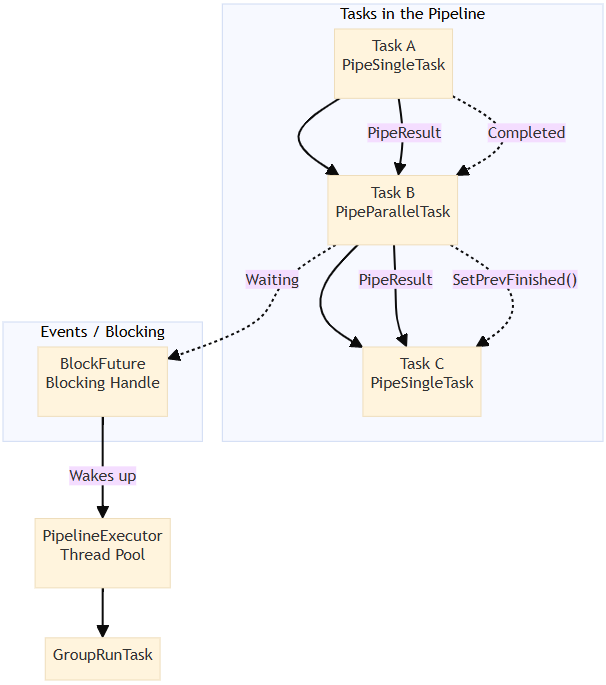
Pipeline Task Orchestration
We divided the semantic‑index construction process into multiple tasks and built them into a directed acyclic graph (DAG) for execution. Different tasks can run asynchronously and in parallel, and each task supports internal parallel execution.
Overall process
DeserializeDataTask
→ ChunkingTask (parallel)
→ GenerateBatchTask
→ EmbeddingTask (parallel)
→ CollectEmbeddingResultTask
→ BuildIndexTask
→ SerializeTask
→ FinishTaskPipeline Scheduling Framework
To efficiently execute pipeline tasks, we implemented a data‑ and event‑driven scheduling framework.
Fully Redesigned Construction Process
Through extensive code modifications, we achieved a major architectural leap, enabling high‑performance semantic index construction.

Conclusion: Higher Throughput and Cost Efficiency
After the full pipeline transformation, tests showed the following results:
- Throughput increased from 170 KB/s to 3 MB/s.
- The SLS vector indexing service is priced at CNY 0.01 per million tokens, offering a cost advantage of two orders of magnitude compared with industry alternatives.
You are welcome to use this service. For more information, see the usage guide.