为什么云基础设施是事件驱动的?
I’m happy to translate the article for you, but I need the full text of the article itself. Could you please paste the content you’d like translated (excluding any code blocks or URLs you want to keep unchanged)? Once I have the text, I’ll provide the Simplified Chinese translation while preserving the original formatting and source link.
什么是事件驱动架构(超越教材)
从本质上讲,事件驱动架构很简单:
某件事发生变化 → 系统自动响应。
事件指任何有意义的状态变化,例如:
- CPU 超过阈值
- 流量突然激增
- 虚拟机出现健康问题
- 部署被推送
- 成本异常出现
- 安全规则被修改
系统不再等待人工干预或同步请求,而是监听这些变化并实时作出响应。
这带来了:
- 松耦合的系统
- 更快的响应速度
- 更高的弹性
- 极少的人为干预
Amazon Web Services、Microsoft Azure 和 Google Cloud 等云平台本质上就是围绕这种模型构建的,使用的服务包括 AWS Lambda、Google Cloud Pub/Sub 等。

Source:
响应式可扩展性:因事件而扩展
传统基础设施基于假设进行扩展。
事件驱动的基础设施基于现实进行扩展。
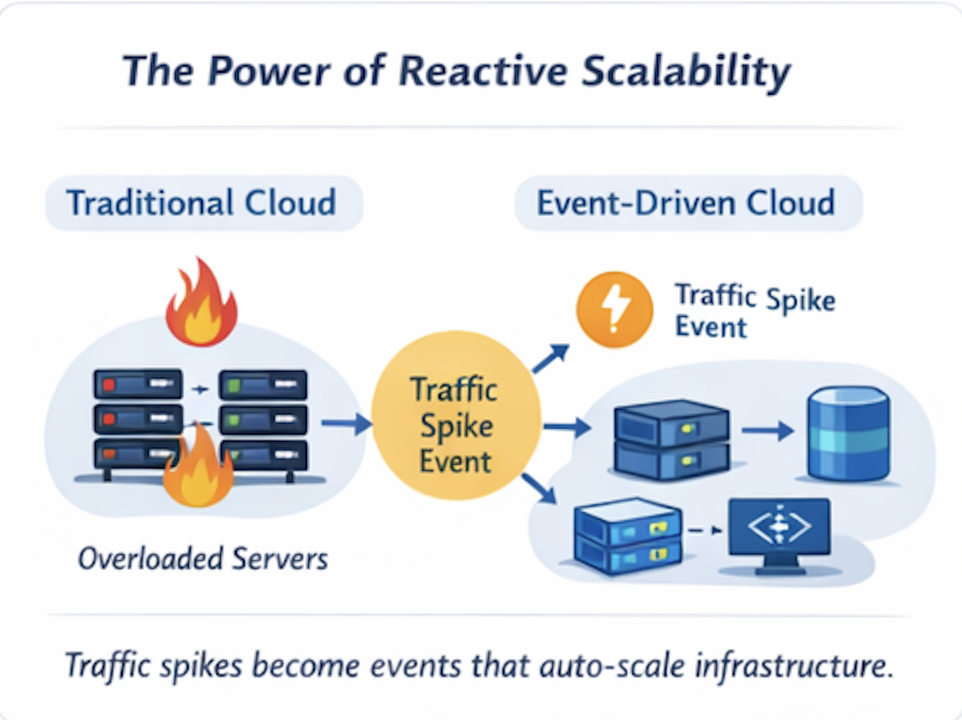
旧问题
一次突发的流量激增(秒杀、功能上线、营销高峰)会压垮固定容量。
结果
- 响应时间变慢
- 出错
- 警报页面弹出
- 收入损失
事件驱动的现实
流量增长被视为一个事件,而不是意外。这个单一信号会自动触发:
- 启动新的容器或实例
- 负载均衡器重新分配流量
- 只读副本向外扩展
- 缓存主动预热
所有这些都在几秒钟内完成,无需人工介入。
- 开发者 遭遇的火灾救援更少。
- FinOps 只在需要时才看到容量——没有闲置浪费。
自动化修复:故障只是另一件事
故障是不可避免的。停机则不是。
在事件驱动的云环境中,故障不会引发恐慌——它们会触发工作流。
示例
- 节点变得无响应
- 监控发出故障事件
- 实例被移出轮转
- 创建替代实例
- 流量被重新路由
- 事件被记录并发送警报
没有工单。没有等待。没有英雄式的抢救。
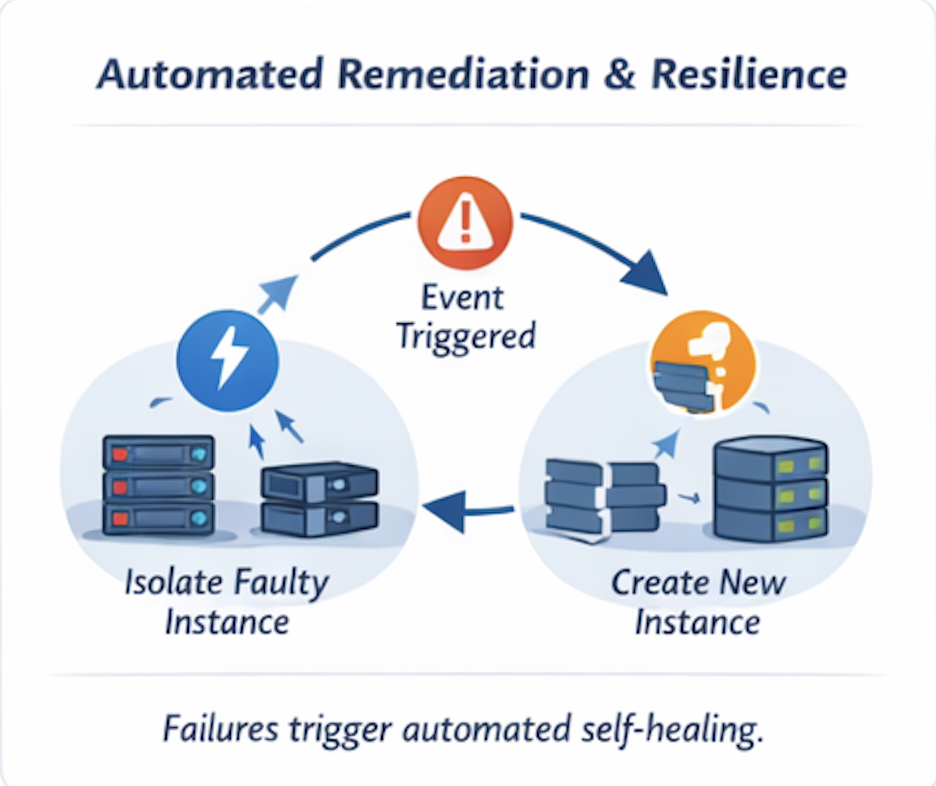
这就是自愈基础设施,只有当系统对事件作出响应而不是依赖人工流程时才可能实现。
配置、治理与合规 – 通过事件强制执行
在大型云环境中,配置漂移是必然的。手动强制执行无法规模化。
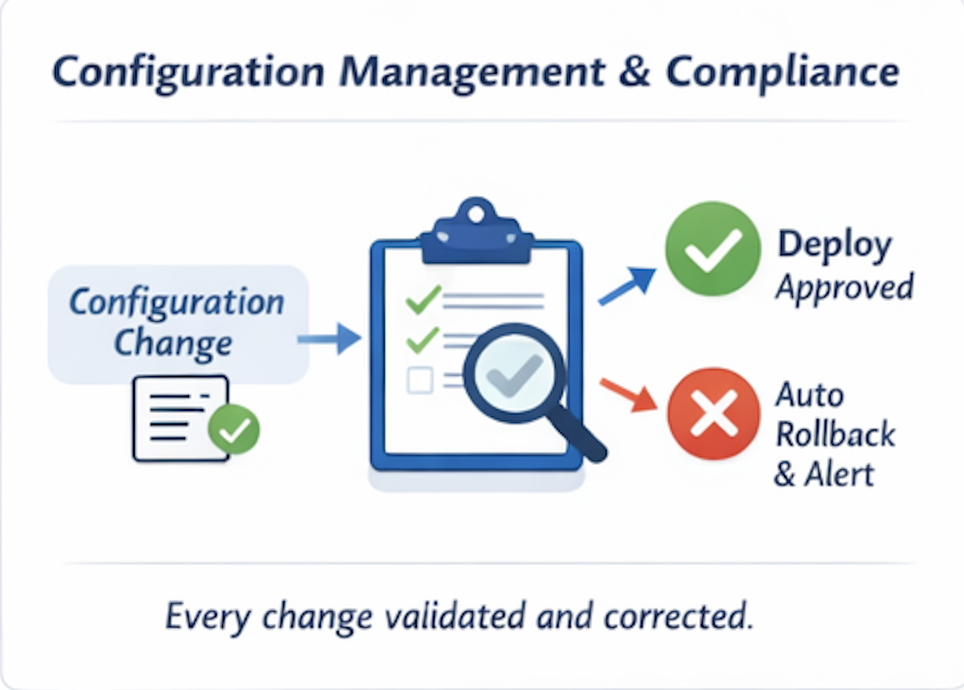
事件驱动的治理颠覆了传统模型:
- 每一次基础设施变更都会产生一个事件
- 每个事件触发自动化的策略检查
- 违规行为会立即生成纠正措施或警报
- 漂移在近实时内被检测并纠正
与其进行周期性审计和事后修复,合规性变得连续且自动化。这在以下场景尤为关键:
- 受监管的环境
- 多账户、多云部署
- 高速运转的工程团队
自动化:将信号转化为结果
这正是事件驱动云真正叠加价值的地方。把事件视为连接整个平台的粘合剂。

- 存储上传 → 处理函数
- 处理完成 → 数据库更新
- 数据库更新 → 通知
- 通知 → 下游工作流
每一步都会发出新的事件,串联操作而无需紧耦合。
结果是什么?
更少的 sc
事件驱动的云基础设施的优势
- 减少 cron 任务
- 减少手动运行手册
- 系统更可靠
工程师专注于构建产品。
FinOps 团队专注于优化信号,而不是追逐账单。
为什么这对 FinOps 更加重要
以下是不太舒服的真相:
云成本不会随机飙升。它们飙升是因为某件事发生了。
- 工作负载意外扩展
- 计划被删除
- 部署出现循环
- 服务进入空闲但仍保持运行
所有这些都是 事件。
事件驱动的基础设施使 FinOps 团队能够:
- 即时检测影响成本的事件
- 在账单爆炸前做出响应
- 自动关闭、缩减规模和优化
- 将成本直接关联到系统行为
没有事件,FinOps 只能被动。
有了事件,FinOps 成为实时成本控制。
云不会等待——你的基础设施也不应等待
现代云基础设施不再是管理服务器。
而是智能地响应变化。
事件驱动的架构通过使每一次变化 可观察、可操作、可自动化 来实现这一转变。
- 智能扩展
- 自愈系统
- 持续合规
- 实时成本优化
事件驱动的设计已不再是可选项。
如果你的云无法自动响应当前发生的情况,你已经落后。
云基础设施的未来不是静态的。
它 倾听。它 响应。它 优化。
而且它是 事件驱动 的。