我们在布朗大学的 Hackathon 中获胜 🏆
Source: Dev.to
请提供您希望翻译的文章正文内容(除代码块和 URL 之外的文字),我将把它翻译成简体中文并保持原有的 Markdown 格式。
Inspiration
我们都遇到过不知道从何入手的家庭维修问题。一个独居在公寓的女性,或是刚学会洗衣的大学新生(就是我!),都可能碰到日常的麻烦:从马桶堵塞到水管漏水。
有时,仅仅为了检查一个小问题而邀请陌生人进入我们的居住空间会让人感到不舒服。而在像纽约这样的城市,即使是一次快速的技师上门也可能费用不菲,这对年轻人和老年人来说都是沉重的经济负担。我们意识到,很多人其实只需要清晰、一步一步的指导,告诉他们先做什么,以及哪些操作是真正安全的。
正是这些体会激发了我们打造一个交互式家庭故障排查平台的想法,它的体验就像是 FaceTiming 你的爸爸:一个对家用电器和维修有经验的人。
功能概述
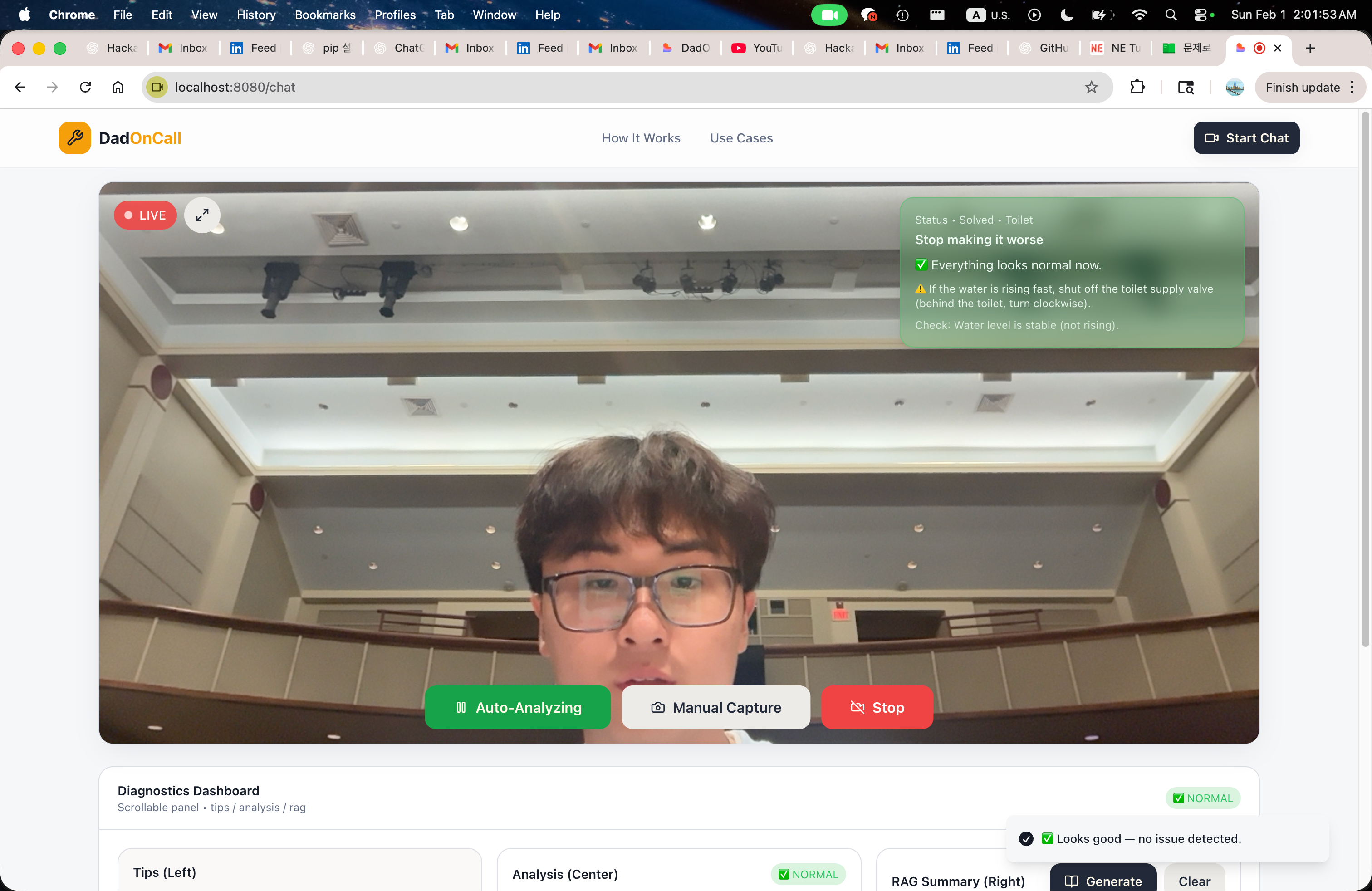
HandyDaddy 在处理家庭问题时提供帮助,范围从简单的风扇故障到更棘手的任务,例如如何使用马桶塞。 在有 HandyDaddy 之前,我们常常要打电话给爸爸或花很长时间在网上搜索信息,但这些方式无法针对你的具体情况提供实时反馈。
HandyDaddy 通过实时视频,根据所看到的内容提供一步步的指导来解决这一问题。 它不仅仅是向语言模型发送提示并盲目信任其生成的内容,而是采用更可靠的流程:结构化输出 + 基于 RAG 的检索,从而使响应保持有据、效率高且安全。
我们是如何构建它的
我们将 HandyDaddy 打造成一个个人实时、以视觉为先的家居维修助理。核心思路很简单:与其让用户描述问题,不如让他们 SHOW(展示)出来。
-
Vision layer – 系统持续从实时视频流中捕获图像,并将其发送给 Gemini,后者充当视觉模型。对于每一帧,Gemini 会生成 JSON 格式的结构化分析,识别装置、位置、潜在问题以及安全等级。该结构化输出成为后续所有工作的基础,同时生成针对文档的语义搜索查询。
-
Retrieval‑Augmented Generation (RAG) – 我们使用 FAISS 和句子嵌入自行构建向量库,索引用 Markdown 编写的真实维修和安全文档。我们不是让模型“自行推断”,而是检索最相关的信息并直接输入到解决阶段。
-
Planning layer – 来自 Groq 的高性能大语言模型根据三个输入合成清晰的分步计划:精炼后的分析、检索到的文档以及安全约束。此种分离(视觉 → 推理 → 检索 → 规划)使每个模型专注于单一职责,便于调试和提升可信度。
-
State management – 所有中间状态按会话存储在 Redis 中,使系统能够随时间跟踪进度,而不是把每张图像当作孤立请求。为实现透明化,我们构建了本地的 “backstage viewer”,可以准确展示数据在管道中的流动,从原始视觉输出到最终指导。
总体而言,HandyDaddy 类似我们的父亲:不追求速度和力量,而是通过精心编排——约束输出、分离职责、并以真实文档为依据——来实现可靠的协作。
我们遇到的挑战

其中最困难的挑战之一是从零开始构建系统架构,同时避免只做另一个 GPT 包装器的诱惑。我们不想让 HandyDaddy 看起来像一个只会给出通用答案、却并未真正理解情境的聊天机器人。由于该工具旨在帮助真实的人解决真实的问题——有时涉及水、电或安全——猜测是不可接受的。
为了让系统值得信赖,我们必须设计出比最初预想的更为复杂的架构。我们没有让单一模型完成所有任务,而是将系统划分为明确的阶段:
- Visual understanding (Gemini)
- Structured reasoning & output (JSON)
- Document retrieval (RAG)
- Step‑by‑step planning (Groq)
每个阶段都有其重要作用。虽然这在最初使开发变得更慢、更困难,但也让产品变得更加可靠。
另一个挑战是将模型的输出强制限制为严格的 JSON 架构,而不是自由文本。早期的尝试产生了许多疑惑和失败,但我们很快意识到这一约束是必不可少的。它使我们能够跟踪状态、推理安全性,并解释系统为何给出特定建议。
总体而言,最大的挑战是把 正确性和可信任 放在速度和简易性之上。为人们构建系统意味着要格外谨慎,即使这会带来不便。
Source: …
我们引以为豪的成就

- 实时视觉优先辅助 – 用户只需将手机摄像头对准问题,即可获得实时指导。
- 安全优先设计 – 结构化的 JSON 输出让我们能够强制安全约束,并在任务被判定为危险时中止。
- 基于事实的答案 – RAG 确保每条建议都有经过审查的维修文档作为依据。
- 透明的流水线 – 后台查看器让开发者和用户能够清晰看到系统是如何得出建议的。
- 可扩展的架构 – 解耦的组件(视觉、检索、规划、状态)使得替换模型或添加新知识源变得轻而易举。
HandyDaddy 展示了将视觉、结构化推理和检索增强生成相结合,如何将棘手的家居维修问题转化为可管理、引导式的体验——就像在视频通话中拥有一位知识渊博的父亲一样。

We’re most proud of the complete full‑cycle architecture we built and how it works in real time. HandyDaddy doesn’t just analyze a single image; it reacts, updates, and guides users step‑by‑step based on what it sees **LIVE**. This makes the experience feel personal and practical, not theoretical.
The live feedback loop is something we genuinely find useful and are proud of. Seeing the system detect a situation, assess risk, and immediately guide the next safe action feels like a full circle—something we would actually want to use in our college dorm starting tomorrow.
We’re also proud that the system is transparent. Every decision, from vision detection to document‑based guidance, can be traced and inspected. That clarity gives us confidence that the system isn’t guessing, and it helps us improve it faster.我们学到的

- 世界充满了问题,但时间总是有限的。这种紧张感让构建事物变得令人兴奋。熬夜(有时甚至只睡不到一分钟),逐行调试,并看到系统逐步成形,对我们来说真的既有趣又有意义。
- 我们中没有人之前从零开始设计完整的 AI 流水线。阅读研究论文、观看 YouTube 视频以及尝试不同的方法,让我们学到了远超预期的东西。我们学到的不仅是模型如何工作,更是 系统 如何运作,以及微小的设计决策如何影响信任、安全性和可用性。
- 最重要的是,我们意识到构建能够帮助不同人群——大学生、家庭,甚至老年人——的东西是多么有力量。这种想法让每个漫长的夜晚都值得。
HandyDaddy 的下一步
- 同步语音和图像输入 – 目前,HandyDaddy 支持图像分析和语音输入,但它们是分别处理的。由于图像捕获和语音更新会在前端触发不同的状态重置,真正的同步提交尚未完全解决。
- 合并流 – 我们的下一步是将语音和图像一起捕获为单一输入,这样系统不仅能理解它看到的内容,还能了解用户在同一时刻说的话。解决此问题将使 HandyDaddy 感觉更加自然和人性化。
- 扩展场景覆盖 – 除了多模态输入,我们还希望在保持相同核心原则的前提下处理更多家庭场景:复杂推理、基于事实并经过验证的知识,以及对真实用户的实际帮助。