给缓存键加版本,否则滚动部署会出错
Source: Dev.to
概览
滚动部署的设计目的是让多个版本的服务同时运行而不会出现停机。大多数团队会关注 API 和数据库层面的兼容性,但还有一个版本悄然交互的地方:缓存。
我们在一次生产环境的发布中遇到了这个问题,结果发现修复方案比整个事件本身还要简单。
事件
一次生产部署在滚动发布过程中出现故障。
- 日志中出现了反序列化错误
- 请求延迟增加
- 错误率上升
触发问题的变更很小:我们在模型类中重命名了一个字段。
这是一项 向后不兼容的更改。一般来说,应避免此类更改,但有时不可避免——尤其是在使用其他团队或外部系统拥有的模式时。
我们进行了必要的修改,以确保下游服务不会中断,并更新了集成测试使其通过。没有 API 合约的更改,也没有数据库迁移。从外部依赖的角度来看,这次更改是安全的。
我们没有预料到的是缓存。
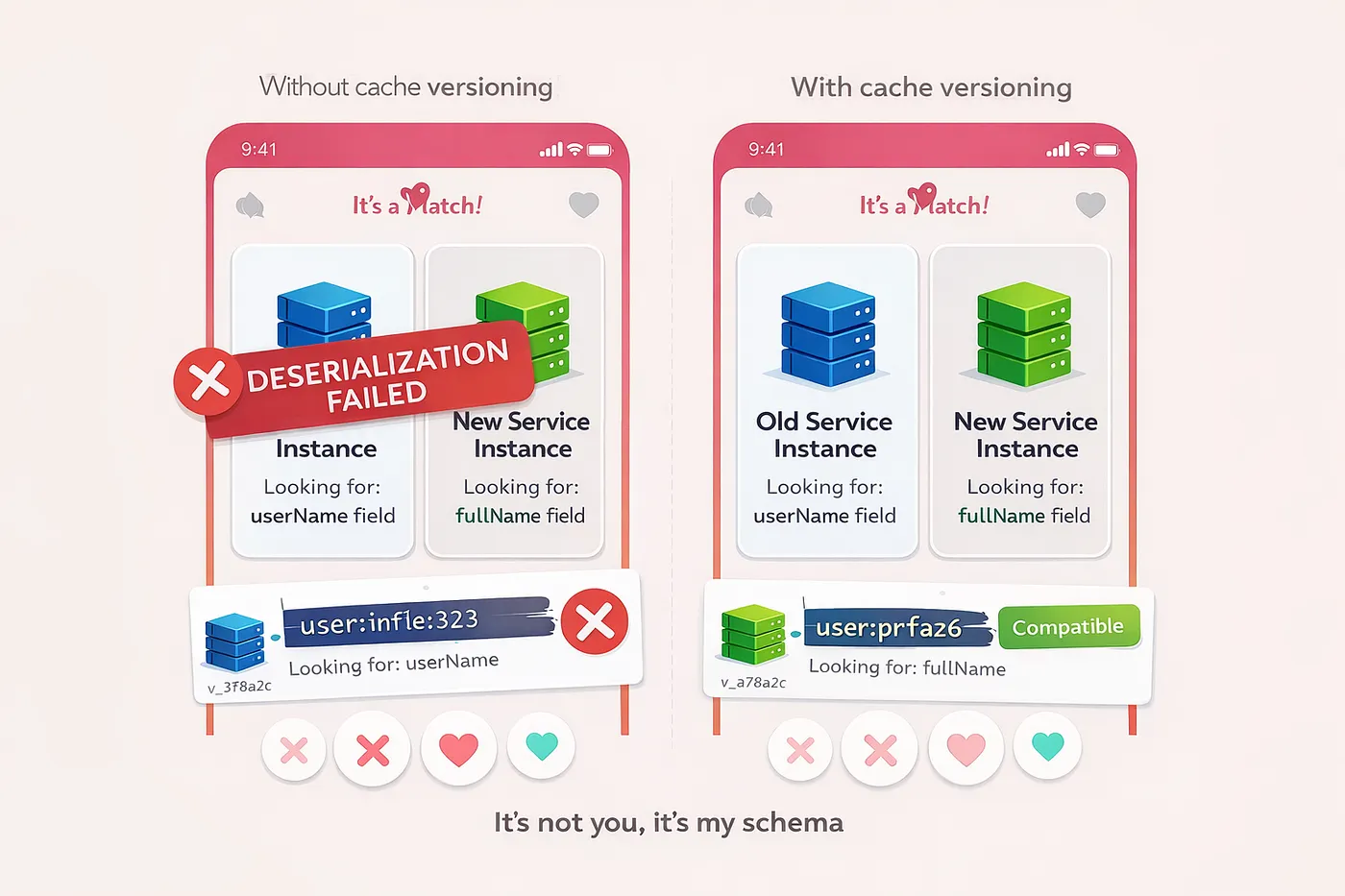
该服务是一个数据聚合器。它消费上游数据,对其进行增强,然后向下游发布结果。它没有持久存储。但在滚动部署期间,两个版本的服务同时运行时,新实例无法反序列化旧实例写入的缓存数据——而旧实例也在处理新实例写入的数据时失败。
这并未被我们的集成测试捕获。问题仅在滚动发布期间出现,当时多个服务版本同时存活。
故障不在我们的 API、数据库层或下游依赖中。
而是在 共享缓存。
当此问题出现时(以及何时不出现)
该问题并不适用于所有架构。
如果你的缓存是:
- 本地的
- 内存中的
- 按实例或按主机范围限定的
那么每个服务版本只会看到自己写入的数据,模式更改自然是相互隔离的。
只有在以下 全部 条件同时满足时,问题才会出现:
- 缓存是共享的或分布式的(Redis、Memcached 等)
- 多个服务版本同时运行
- 这些版本读取并写入相同的缓存条目
换句话说:滚动部署 + 共享缓存。
如果你的部署方式是这样,这种失效模式并不罕见——它是必然的。
实际出了什么问题
大多数团队将缓存视为内部优化手段。但共享缓存是 共享状态,而在独立部署的版本之间共享状态实际上是一种契约。
在滚动部署期间,缓存的生命周期会超过任何单一服务版本。旧代码和新代码会同时与其交互。
简化时间线
14:23:01 - Deployment starts, new instances come up
14:23:15 - Old instance writes: {"userId": 123, "userName": "alice"}
14:23:18 - New instance reads same key, expects: {"userId": 123, "fullName": "alice"}
14:23:18 - Deserialization fails
14:23:19 - New instance writes: {"userId": 456, "fullName": "bob"}
14:23:20 - Old instance reads same key, expects: {"userId": 456, "userName": "bob"}
14:23:20 - Deserialization fails字段重命名引入了一个破坏性更改——不是在 API 层,而是在 缓存层。
为什么常见的替代方案难以扩展
当出现这种情况时,团队通常会考虑以下其中一种:
- 在部署期间暂停或排空流量
- 清空整个缓存
- 跨团队紧密协调发布时间
所有这些方法都可能奏效,但它们会增加运维负担并降低部署灵活性。随着系统和团队的增长,它们也难以扩展。
我们希望找到一种让滚动部署再次变得无聊的解决方案。
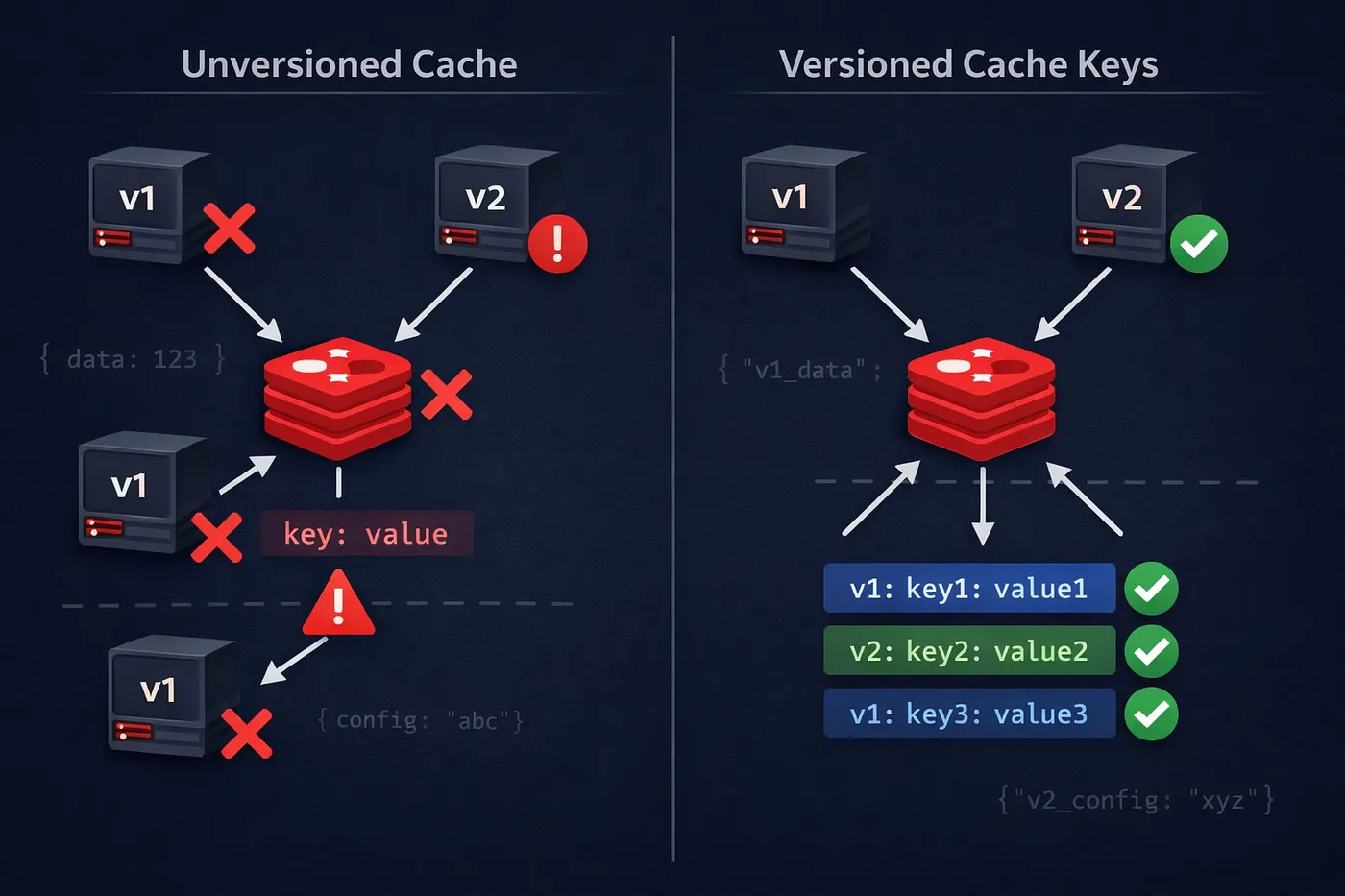
解决方案:为缓存键添加版本
而不是使用如下的缓存键:
user:123我们添加了显式的版本前缀:
v1:user:123
v2:user:123每个服务版本只读取和写入与其自身版本匹配的键。
就这么简单。
我们如何计算缓存键版本
一个关于缓存键版本化的未解之谜是 如何管理版本本身。
硬编码版本号或手动递增虽然可行,但容易忘记且会增加流程负担。我们希望版本化能够 自动且透明。
我们的做法是直接从 被缓存的模型类结构 中派生版本:
- 使用反射检查模型类。
- 提取其结构形状:
- 字段名称
- 字段类型
- 嵌套对象(递归)
- 创建该形状的规范表示。
- 对表示进行哈希计算。
- 将哈希值用作缓存键的版本标识。
由于版本与实际数据模式绑定,任何更改(例如字段重命名、添加/删除字段、类型变更)都会自动生成新版本,从而消除人为错误的风险。
要点
- 共享缓存在滚动部署期间成为服务版本之间的 契约。
- 未版本化的缓存键在模式演进时可能导致反序列化失败。
- 简单的键版本化(
v1:…、v2:…)可以将每个版本的数据隔离开来。 - 从模型结构中派生版本使过程 自动化 且 万无一失。
通过将缓存视为版本化的契约,滚动部署保持平稳,团队能够在无需昂贵协调的情况下自由迭代。
缓存键的修复
因为版本是从模型结构派生的:
- 任何结构性更改(字段重命名、类型更改、添加或删除字段)都会产生一个新版本。
- 如果模型没有任何变化,版本保持不变。
- 版本提升会自动发生,仅在需要时进行。
版本是 针对每个模型类 的,而不是全局的。每个缓存的模型会独立演进。
概念上,缓存键的形式如下:
<version>:<model>:<id>这使得在任何模型结构变更时都能透明地提升版本,而开发者无需在重构时记得手动更新缓存版本。
示例(Java)
下面是一个简化示例,展示如何使用反射从类结构中派生稳定的哈希值:
import java.lang.reflect.Field;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.util.*;
import java.util.stream.Collectors;
public class RecursiveCacheVersioner {
public static String getVersion(Class<?> rootClass) {
// Use a Set to prevent infinite recursion on circular dependencies
String schemaBuffer = buildSchemaString(rootClass, new HashSet<>());
return hashString(schemaBuffer);
}
private static String buildSchemaString(Class<?> clazz, Set<Class<?>> visited) {
// Base case: if we've seen this class or it's a basic type, just return the name
if (isSimpleType(clazz) || visited.contains(clazz)) {
return clazz.getCanonicalName();
}
visited.add(clazz);
StringBuilder sb = new StringBuilder();
sb.append(clazz.getSimpleName()).append("{");
// Sort fields to ensure the hash is deterministic
List<Field> fields = Arrays.stream(clazz.getDeclaredFields())
.sorted(Comparator.comparing(Field::getName))
.collect(Collectors.toList());
for (Field field : fields) {
sb.append(field.getName()).append(":");
// RECURSIVE STEP: if the field is another model, get its structural string too
sb.append(buildSchemaString(field.getType(), visited));
sb.append(";");
}
sb.append("}");
return sb.toString();
}
private static boolean isSimpleType(Class<?> clazz) {
return clazz.isPrimitive()
|| clazz.getName().startsWith("java.lang")
|| clazz.getName().startsWith("java.util");
}
private static String hashString(String input) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hash = digest.digest(input.getBytes(StandardCharsets.UTF_8));
// Java 17+ native hex formatting
return HexFormat.of().formatHex(hash).substring(0, 8);
} catch (Exception e) {
return "default";
}
}
}生成器看到的内容:
对于包含 Address 对象的 User 类,构建器会生成如下规范字符串:
User{address:Address{city:String;zip:String;};id:int;name:String;}该字符串随后被哈希,以创建版本前缀。
关于语言支持的说明
此方法在 强类型语言 中效果最佳,因为这些语言在运行时可以获取类型信息(例如 Java、Kotlin、C#)。反射使得能够可靠地检查模型结构并从中派生稳定的版本。
在更动态的语言(如 JavaScript)中,由于运行时类型信息有限或隐式,可能需要采用不同的方式——例如显式定义 schema、使用 schema 版本化,或在构建时生成代码。底层思路仍然适用,只是实现细节会有所不同。
关于性能的说明
缓存键的版本会在 服务启动时对每个模型类计算一次,而不是在每次缓存读取或写入时计算。这使得运行时开销可以忽略不计,并确保缓存操作仍然保持原有的高速。版本计算是 pa
初始化的 rt;稳态请求处理保持不受影响。
为什么这种方法有效
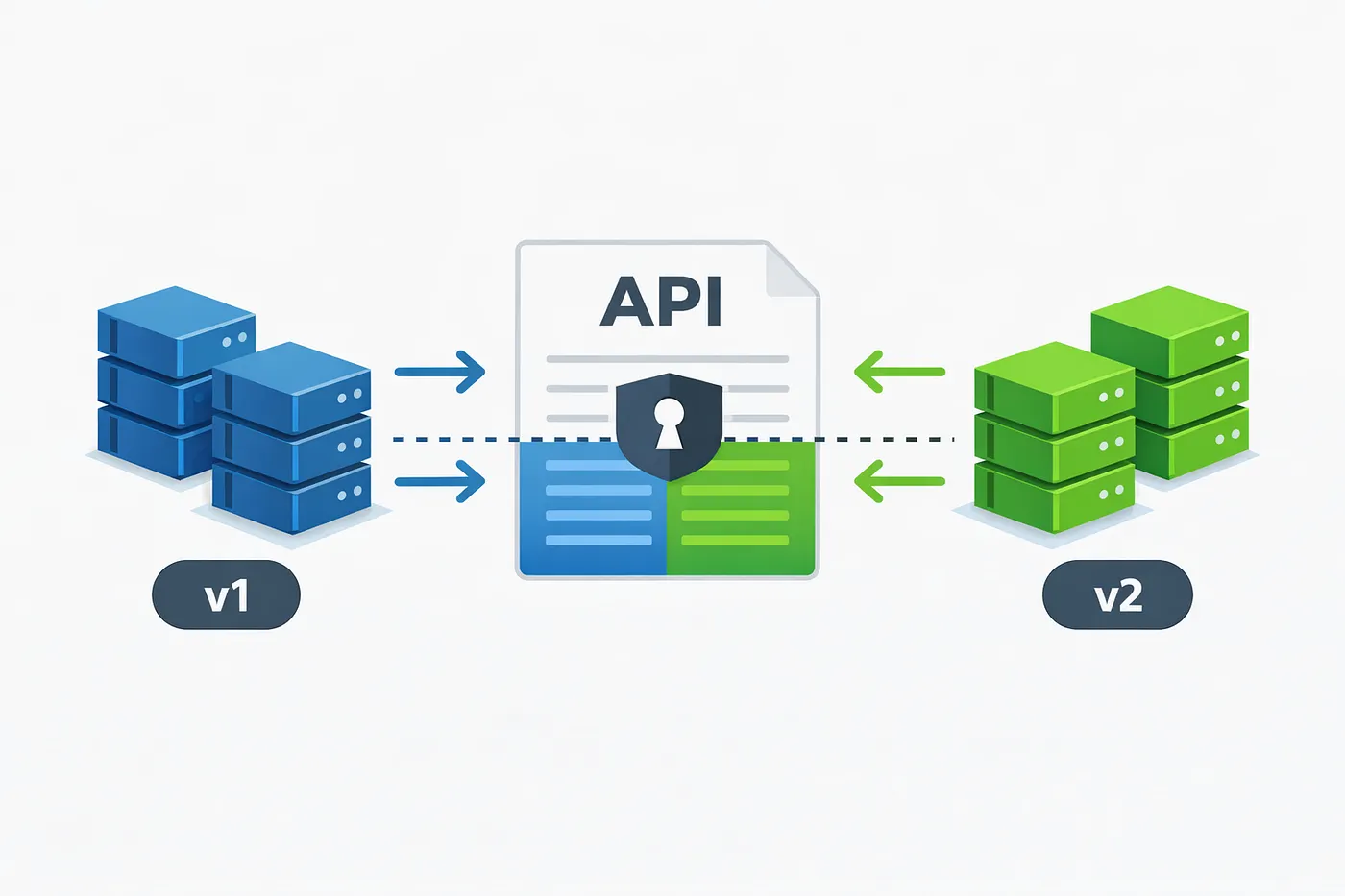
对缓存键进行版本化,使旧版本和新版本在滚动部署期间能够安全共存。每个版本只读取和写入它能够理解的数据,从而避免不兼容的表示发生冲突。
后果
- 部署期间无需刷新缓存。
- 不需要与其他团队协调。
- 破坏性的模式更改被版本隔离。
- 旧版和新版可以并行运行而不会出错。
由于版本是自动从模型结构派生的,无需手动管理版本。改变模型的重构会自然地使不兼容的缓存条目失效,而兼容的更改则不会导致不必要的缓存 churn。
部署完成后,旧版本停止访问缓存,它们的条目会根据 TTL 自然过期。缓存不再强制要求本来不应兼容的版本之间保持兼容性。
当此方法特别有用时
- 您在多个服务实例之间使用共享缓存。
- 您使用滚动更新频繁部署。
- 您无法完全控制上游模式。
- 您运行聚合器或微服务架构,不同服务可能独立演进。
Middleware Services
在我们的案例中,它允许上游提供方团队在不与我们协调缓存行为的情况下进行更改,同时确保我们这边的部署安全。
权衡与限制
像大多数架构决策一样,缓存键版本化也有值得提前了解的权衡。
缓存中的多个版本
在滚动部署期间,同一逻辑对象的多个版本可能同时存在于缓存中。以我们的情况为例,部署大约需要 15 分钟。在 1 小时 TTL 下,这在短时间内导致缓存条目大约 翻倍。
暂时更高的缓存使用
这种做法是用内存换取安全性。对我们来说影响不大:部署期间缓存利用率从 ~45 % 提升到 ~52 %,随后旧条目过期后恢复正常。
并非适用于所有环境
如果缓存内存极其受限,或者系统在部署期间需要严格的跨版本一致性,则此方法可能不适合。
过渡期间的有意缓存未命中
新版本在首次访问时会缓存未命中并重新计算值。这是预期且有意为之——比尝试反序列化不兼容的数据更安全。缓存 TTL 和缓存未命中路径应相应设计。
你获得的:更安全的滚动部署、更简化的运维行为以及在模式变更期间降低风险。
你放弃的:部署期间的一些缓存效率。
对我们而言,这一权衡非常值得。
更好的缓存思维模型
缓存常常被视为实现细节。实际上,共享缓存是系统 运行时契约 的一部分。
如果多个服务版本能够读取和写入相同的缓存数据,那么缓存兼容性的重要性与 API 或存储兼容性同等。
对缓存键进行版本化可以使该契约变得明确。
最终要点
如果您正在进行滚动部署并使用共享缓存:
默认对缓存键进行版本化。
这是一项小改动,却对可靠性产生巨大影响,并且在系统演进时保持部署的可预测性。