使用 LMAX Disruptor 在 Java 中构建高性能内存事件代理
Source: Dev.to
Introduction
我大部分时间都在编写用于数据分析、工程、文件系统操作和 Web 项目的 Python 代码,同时也会使用一些 Go,因为它的并发模型更简洁——或者出于新鲜感使用 Rust。我最初是用 C 编程的,后来通过 Java 学习面向对象编程。离开 JVM 七年后,我对它的变化产生了好奇,于是决定通过构建一个对性能要求极高的项目重新投入使用。最终实现了一个事件路由器,在笔记本电脑上能够以 每秒 700 万次以上的调度 处理速度运行,关键是消除了两个主要瓶颈:锁和内存分配。
Why Java when Python and Go exist?
作为一名 Python 开发者,我通常会使用像 PyPubSub 或 Blinker 这样的库来进行事件处理。这些库在 I/O 密集型应用中表现良好,但在 CPU 密集型的事件处理上会因为 GIL(在 Python 3.14 之前的版本)而受限。
Go 基于 channel 的并发模型配合 goroutine 能优雅地处理事件,且像 EventBus 这样的库提供了在 Go 生态中自然的发布‑订阅模式。然而,这两个生态系统都没有直接对应 Disruptor 那种机械‑同情(mechanical‑sympathy)的方法。
- Python 的解释器开销以及 Go 的垃圾回收器(虽然比 Python 的好)都会引入延迟,而在每秒数百万次事件的场景下,这种延迟会变得明显。
- 如果你正在构建一个系统,几微秒的事件处理时间乘以数百万次实际上会产生重大影响(如金融系统、实时分析、游戏服务器),Java 成熟的 JIT 编译、精细调优的 GC 选项以及像 Disruptor 这样的库——它们利用 CPU 缓存行为——能够提供难以匹配的性能。
基于锁的典型事件总线
典型的事件总线使用在 synchronized 块中包装的队列。当线程 A 想要发布事件时,它会:
- 锁定队列。
- 添加事件。
- 解锁队列。
线程 B 执行相同的步骤。在高吞吐量下,线程花在 等待锁 上的时间比实际工作时间更多。
问题
- 锁竞争 – 频繁的锁/解锁循环成为瓶颈。
- CAS 开销 – 即使是 Java 的
ConcurrentLinkedQueue也依赖 compare‑and‑swap 操作,这会引入内存屏障和额外的延迟。 - 对象分配 – 为每条消息创建新的
Event实例会产生大量垃圾。每秒数百万的事件会导致垃圾回收器持续运行,产生明显的停顿。
环形缓冲区
Disruptor 本质上是对 循环缓冲区 数据结构的高度调优实现——一个固定大小的数组,环形回绕以复用槽位。任何学习过数据结构和算法的人都可能遇到过这种模式,但 Disruptor 专门针对多线程事件处理进行锁‑自由的优化。

Source: Wikipedia – Circular Buffer Animation
{kind=link}
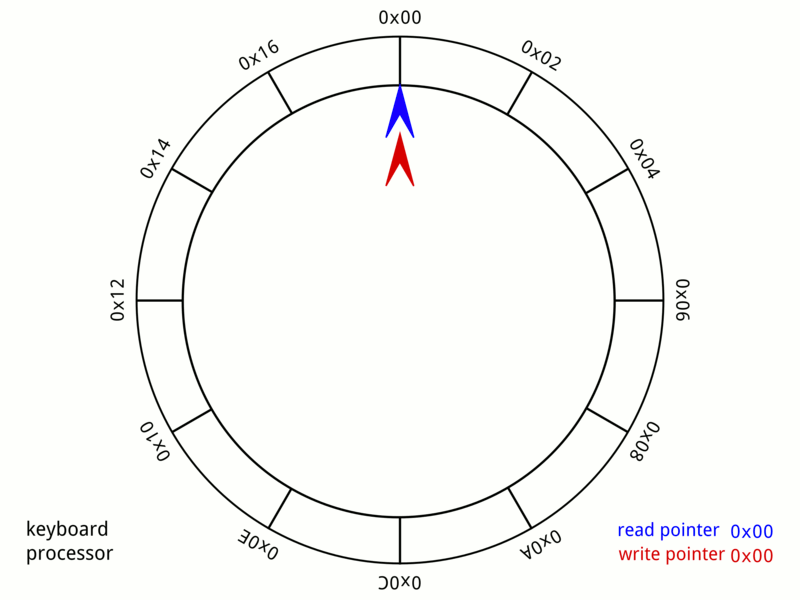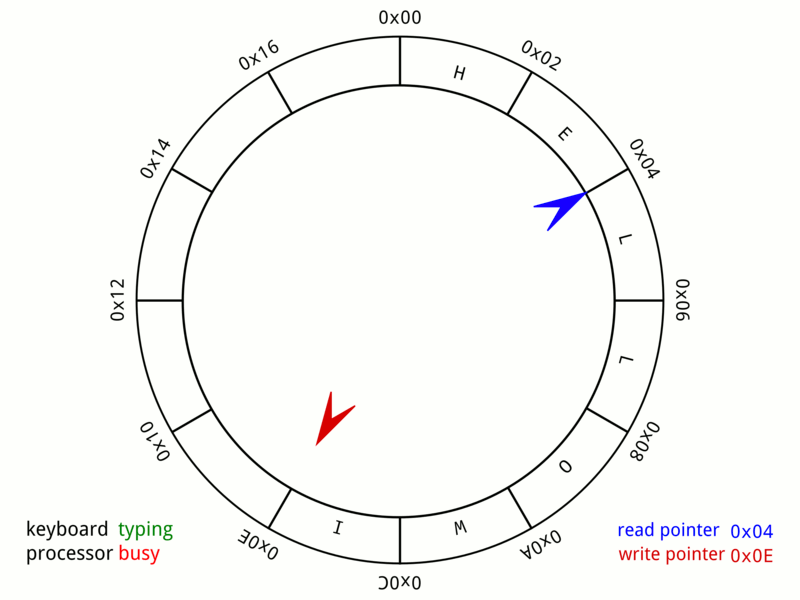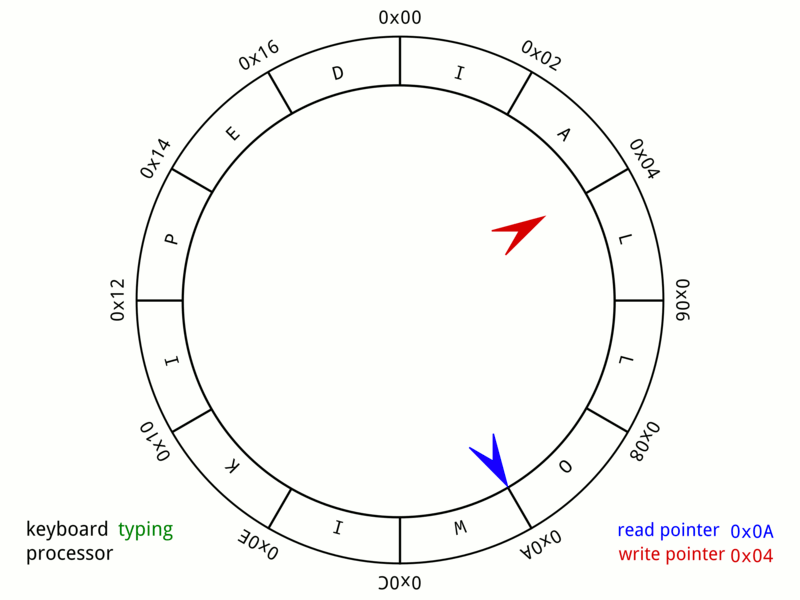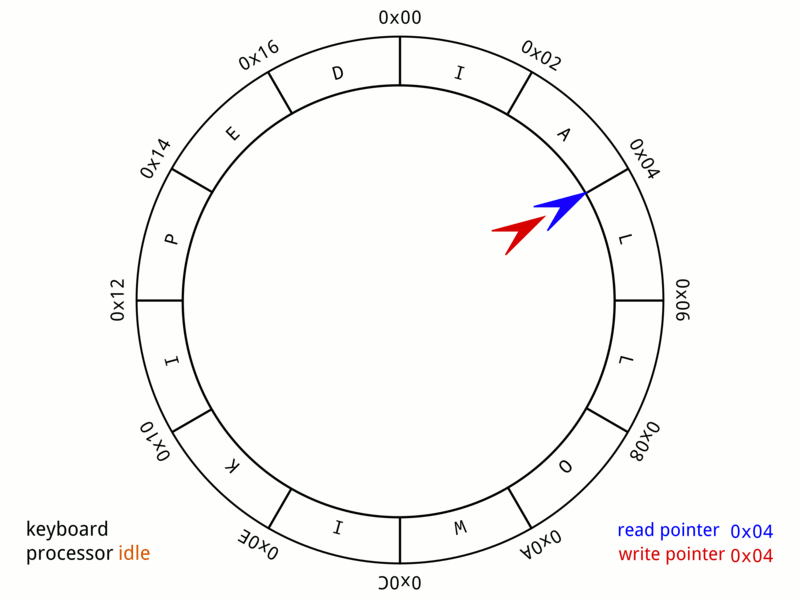
想象一个拥有 16 384 个预分配 Event 槽位的循环数组。发布者声明下一个可用槽位,将数据直接写入该槽,并标记为就绪。
- 无锁。
- 无分配。
- 仅通过原子序列号来协调写入位置。
当生产者发布时,它调用 ringBuffer.next() 来获取一个序列号,将数据复制到 ringBuffer.get(sequence),最后调用 ringBuffer.publish(sequence)。这里的 “复制” 指的是设置已有 Event 实例的属性——不会创建新对象。
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import org.jetbrains.annotations.NotNull;
/**
* 路由器是一个事件总线,供订阅者附加并接收相关事件。
*/
public class EventRouter {
private final @NotNull Disruptor disruptor;
private final @NotNull RingBuffer ringBuffer;
/**
* 在事件总线上发布一个事件。
*/
public void publish(@NotNull Event e) {
long sequence = this.ringBuffer.next();
try {
// Event 类具有自定义属性:type、from、payload、timestamp。
Event bufferedEvent = ringBuffer.get(sequence);
bufferedEvent.setType(e.getType());
bufferedEvent.setFrom(e.getFrom());
bufferedEvent.setPayload(e.getPayload());
bufferedEvent.setTimestamp(e.getTimestamp());
} finally {
this.ringBuffer.publish(sequence);
}
}
}消费者看到已发布的序列号并按顺序处理它们。
Source: …
调度策略
一旦事件被放入环形缓冲区,路由器就会将其分发给所有已注册的订阅者。每种事件类型都有一个 订阅者列表,以便路由器能够快速定位对该类型感兴趣的监听器。当事件到达时,路由器:
- 查找该事件类型对应的订阅者列表。
- 为 每个 订阅者向线程池提交一个分发任务。
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.jetbrains.annotations.NotNull;
/**
* Thread pool for dispatching events to subscribers.
* The pool size matches the number of available CPU cores, keeping the CPU busy
* without oversubscribing.
*/
private final ExecutorService DISPATCH_POOL =
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* Dispatch an event to all its subscribers.
*
* @param e the event to dispatch
* @param sequence the sequence number of the event in the ring buffer
*/
private void dispatch(@NotNull Event e, long sequence) {
// Retrieve the list of subscribers for the event's type.
List<Subscriber> subs = subscriberMap.get(e.getType());
if (subs == null || subs.isEmpty()) {
return; // No one is interested.
}
// Submit a dispatch task for each subscriber.
for (Subscriber sub : subs) {
DISPATCH_POOL.submit(() -> sub.handle(e, sequence));
}
}- 线程池大小 –
Runtime.getRuntime().availableProcessors()确保线程池的线程数恰好等于 CPU 核心数,避免不必要的上下文切换。 - 零分配分发 –
Event对象是预先分配并复用的,因此分发仅涉及方法调用和最小的账务处理,不会产生额外的垃圾。
结论
通过将无锁环形缓冲区(Disruptor 模式)与轻量级调度线程池相结合,我们消除了传统事件总线的两个主要性能瓶颈:
- 锁竞争
- 过度的对象分配
其结果是一个能够在普通笔记本电脑上实现 每秒 700 万次以上调度 的事件路由器,证明了 Java 在高吞吐、低延迟领域仍然能够与 Python 和 Go 并肩竞争。
// See section “Copy‑on‑Write subscribers”
public void onEvent(Event e, boolean endOfBatch) {
SubscriberList holder = this.subscribers.get(e.getType());
if (holder == null) return;
var subs = holder.list;
if (subs.isEmpty()) return;
if (subs.size() == 1) {
subs.getFirst().onEvent(e);
} else {
for (Subscriber sub : subs) {
DISPATCH_POOL.submit(() -> sub.onEvent(e));
}
}
}线程池的大小与 CPU 核心数相匹配。这在保持主环形缓冲区单线程高速处理的同时,将订阅者回调并行化到多个线程上。
每个订阅者都有自己的单线程执行器(onEvent),用于排队接收的事件。这保证了每个订阅者内部的顺序(如果事件 A 先发布,则一定先于事件 B 处理),同时防止某个慢订阅者阻塞其他订阅者。
/**
* A subscriber listens to a given number of event types in his scope's range.
*/
public abstract class Subscriber implements AutoCloseable {
/**
* This executor ensures events are processed one at a time, in the order they are received,
* without blocking the event router.
*/
@NotNull
private final ExecutorService exec = Executors.newSingleThreadExecutor();
/**
* Return the scope of this subscriber.
*/
@NotNull
public abstract Scope scope();
/**
* Process an event received from a router.
*/
protected abstract void processEvent(@NotNull Event e);
/**
* Send data to this subscriber. This is fast and does not block the caller.
*/
public final void onEvent(@NotNull Event e) {
this.exec.submit(() -> this.processEvent(e));
}
@Override
public void close() throws TimeoutException, InterruptedException {
this.exec.shutdown();
if (!this.exec.awaitTermination(1, TimeUnit.MINUTES)) {
throw new TimeoutException("subscriber's executor thread termination timed out");
}
}
}选择 WaitStrategy
Disruptor 提供了几种等待策略,用于控制在没有新事件可用时消费者的行为。
| Strategy | Behaviour |
|---|---|
BlockingWaitStrategy | 使用锁;对 CPU 友好,但会增加延迟。 |
BusySpinWaitStrategy | 紧密自旋;延迟最低,但会消耗 100 % CPU。 |
SleepingWaitStrategy | 逐步退让;在 CPU 使用率和合理延迟之间取得平衡。 |
YieldingWaitStrategy | 空闲时调用 Thread.yield();位于中间地带——低延迟且不完全自旋。 |
我选择了 YieldingWaitStrategy,因为它在提供低延迟的同时避免了空闲期间的 CPU 浪费。对于处理突发事件且偶有安静时段的系统,yield 能在不占用 CPU 的情况下提供良好的吞吐量。
Source: …
本实验事件总线的附加功能
基于作用域的安全性
事件有四个作用域级别:
| Scope | 可见性 |
|---|---|
PUBLIC | 对远程参与者可见 |
FEDERATED | 对受信任的服务器可见 |
PRIVATE | 对本地受信任的参与者可见 |
ROOT | 完全访问权限 |
组件只能与其作用域相同或更低的事件进行交互。
- 注册 – 注册事件类型时,必须指定其作用域。
- 订阅 – 路由器会检查订阅者的作用域是否足够宽,以满足请求的事件类型。
- 发布 – 路由器在分发前会验证事件类型是否已存在。
EventRegistry 将已注册的事件及其作用域存储在 ConcurrentHashMap 中。一次查找仅是一次哈希表读取,几乎不增加额外开销(仅几微秒)。
写时复制的订阅者
每种事件类型映射到一个 SubscriberList,其中保存一个不可变的 List。当有新订阅者注册时,路由器会创建一个包含该订阅者的新列表,并原子地替换旧列表。
- 读取者 在没有任何同步的情况下看到一致的快照。
- 写入者 需要承担复制列表的成本,但相较于分发,订阅操作很少。
此设计在热路径(分发)上进行优化,以牺牲冷路径(订阅)的性能为代价。
基准测试结果
基准测试启动 4 个生产者线程,每个线程在 5 种事件类型上发布 250 000 条事件。每种类型有 4 个订阅者,总计 4 M 次分发操作(1 M 事件 × 4 个订阅者)。
| 机器 | 平均时间(50 次运行) | 分发次数 / 秒 |
|---|---|---|
| Intel Core i7‑13600H,16 GB RAM | 922 ms | 4.34 M |
| Intel Core Ultra 7‑155H,32 GB RAM | 528 ms | 7.58 M |
这些数字是在使用轻量级字符串负载且订阅者仅简单递增计数器的情况下获得的。 实际吞吐量取决于订阅者对事件的具体处理方式,但路由器本身增加的延迟极小。Disruptor 库据称能够实现更高的性能。
What This Experimental Event Bus Does Not Do
- No filtering beyond the event type.
不进行除事件类型之外的过滤。 - No wildcards, content‑based routing, or priority queues.
不支持通配符、基于内容的路由或优先级队列。 - No guaranteed delivery – if a subscriber falls too far behind and the ring buffer wraps, old unprocessed events are overwritten.
不保证投递——如果订阅者落后太多导致环形缓冲区回绕,未处理的旧事件会被覆盖。- The default ring buffer holds 16 K slots; being more than 16 K events behind can cause loss.
默认环形缓冲区拥有 16 K 插槽;落后超过 16 K 条事件会导致丢失。
- The default ring buffer holds 16 K slots; being more than 16 K events behind can cause loss.
- No persistence – events exist only in memory. A process crash discards any in‑flight events. This is an in‑process event bus, not a durable message queue like Kafka.
不持久化——事件仅存在于内存中。进程崩溃会丢失所有未完成的事件。这是一个 进程内 事件总线,而非像 Kafka 那样的持久化消息队列。 - No back‑pressure – the single‑threaded executor per subscriber means slow subscribers build up queues; publishers are not throttled when consumers can’t keep up.
不提供背压——每个订阅者使用单线程执行器,导致慢速订阅者的队列堆积;当消费者跟不上时,发布者不会被限流。
总结
Disruptor 由 LMAX 开发,LMAX 是一个旨在成为“全球最快交易平台”的交易平台。它展示了精心设计的环形缓冲区如何在单进程环境中提供超低延迟、高吞吐量的事件处理。该实验性总线展示了基于该基础构建的实用、范围限定的写时复制实现,同时也突出了要构建生产级消息系统所需的权衡和缺失功能。
代码已在 GitHub 上公开。