了解 Debezium 的变更数据捕获
I’m happy to translate the article for you, but I’ll need the text you’d like translated. Could you please paste the content of the article (or the specific sections you want translated) here? I’ll keep the source line, formatting, markdown, and any code blocks exactly as they are while translating the surrounding prose into Simplified Chinese.
在系统之间移动数据听起来很简单——但实际上并非如此
随着应用程序的增长,团队很快会意识到,可靠地将数据从一个数据库复制到另一个数据库比看起来要困难得多。更新会被遗漏,删除难以追踪,系统会逐渐不同步。
这时 Change Data Capture (CDC)(变更数据捕获)就派上用场了。
在本文中,我将介绍 CDC 是什么,传统方法为何失效,以及 Debezium 如何以根本不同的方式捕获数据变更。
当今数据通常是如何移动的(以及为何会失败)
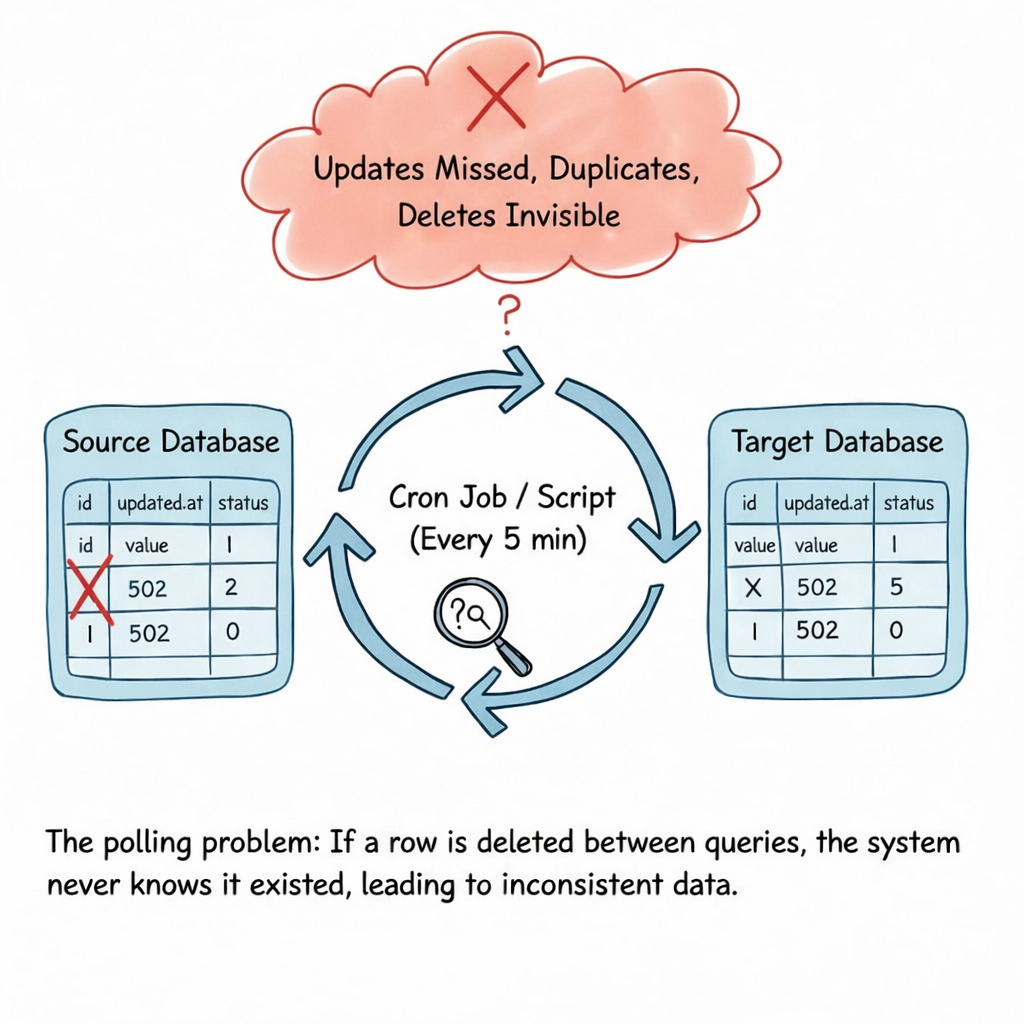
在许多系统中,数据通过定期查询数据库来获取新行或已更新的行。
常见的模式如下:
- 每隔几分钟运行一次作业
- 查询
updated_at > last_run_time的行 - 将结果复制到下游
- 重复
起初这看起来很合理——实现简单,在小规模时运行良好。
但随着系统规模的扩大,问题逐渐显现。
此方法的问题
- 错过更新 当时间戳重叠时
- 数据重复 当作业重试时
- 删除操作不可见 除非手动处理
- 高负载 在生产数据库上
- 延迟 数据更改与消费者看到之间的间隔
这种方法通常被称为 polling,在真实世界的条件下很快就会失效。
什么是变更数据捕获(CDC)?
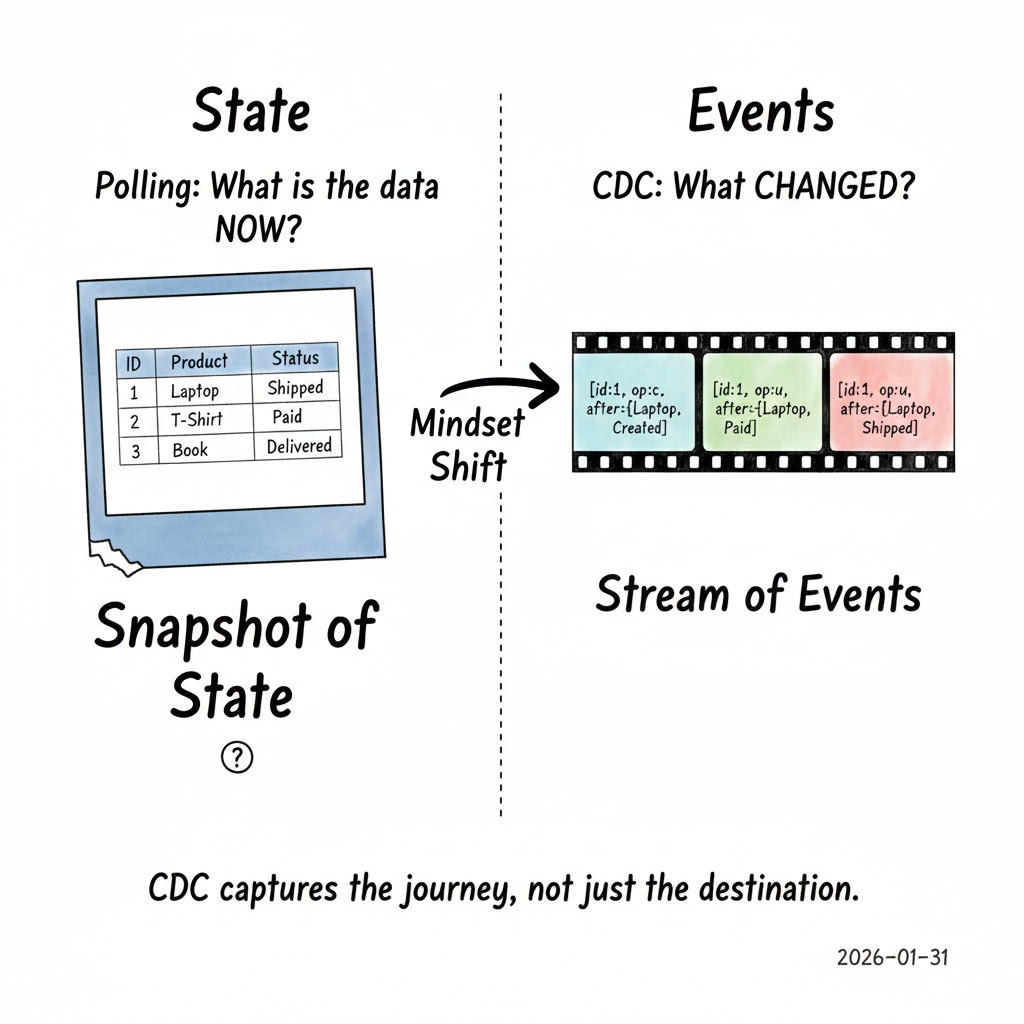
Instead of repeatedly asking:
“现在数据是什么样的?”
CDC asks a different question:
“有什么变化?”
CDC 将 插入、更新和删除 视为 事件,而不是快照中的行。
关键洞察是数据库已经在内部记录了每一次更改——CDC 只是 监听 那些记录。这使得 CDC 与轮询根本不同。
介绍 Debezium
Debezium 是一个用于实现变更数据捕获(Change Data Capture)的开源平台。
从宏观上看:
- Debezium 捕获数据库中的变更
- 将其转换为事件
- 将事件发布到 Apache Kafka
需要早期理解的一件重要事情:
Debezium 不会查询表。
它读取数据库事务日志。
正是这一设计选择让 Debezium 强大。
Debezium 实际捕获变更的方式
每个关系型数据库都会维护内部日志:
| 数据库 | 日志名称 |
|---|---|
| PostgreSQL | WAL (Write‑Ahead Log) |
| MySQL | Binlog |
| SQL Server | Transaction Log |
这些日志的存在是为了让数据库能够:
- 从崩溃中恢复
- 复制数据
- 确保一致性
Debezium 会接入这些日志。
流程如下
- 应用程序向数据库写入数据
- 数据库在事务日志中记录该变更
- Debezium 读取日志条目
- 将变更转换为事件
- 将事件发布到 Kafka 主题
没有轮询。没有猜测。没有遗漏的变更。
CDC 事件包含什么?
Debezium 事件通常包括:
before– 行的先前状态after– 行的新状态op– 操作类型(c= 创建,u= 更新,d= 删除)- 元数据,例如时间戳和事务 ID
CDC 并不是表示状态,而是表示历史。这是一个细微但强大的转变。
实际案例:订单生命周期事件
想象一个 PostgreSQL 中的简单 orders 表。
随时间的变化
| 操作 | 变化 |
|---|---|
| 新订单创建 | status = CREATED |
| 订单付款 | status 变更 CREATED → PAID |
| 订单取消/完成 | status 再次变更 |
使用轮询 只能看到最新状态;删除经常丢失;中间的状态转变会消失。
使用 Debezium 每一次更改都会成为事件,保留完整的生命周期。消费者可以实时响应。
这使得 CDC 非常适用于:
- 分析
- 审计
- 搜索索引
- 缓存失效
Kafka 适合在哪里?
Kafka 充当 事件骨干。Debezium 将更改发布到 Kafka 主题,多个系统可以独立消费这些数据:
- 一个消费者更新缓存
- 另一个消费者填充分析存储
- 再有一个消费者将数据写入数据湖
这种解耦对于可扩展的架构至关重要。
分析系统的作用(细微但重要)
下游系统可以消费 CDC 事件进行分析。例如,像 ClickHouse 这样的分析型数据库常被用作 读取优化的汇聚点,其过程如下:
- CDC 事件被转换
- 被聚合
- 被高效查询
在此配置中:
- Debezium 捕获 变更
- Kafka 传输这些变更
- 分析系统专注于查询
每个系统各司其职,表现出色。
CDC 与其他方法的比较
| 方法 | 优点 | 缺点 |
|---|---|---|
| 轮询 | 实现简单 | 脆弱、低效,可能漏掉数据 |
| 数据库触发器 | 即时捕获 | 侵入性强,难以维护,可能影响性能 |
| 通过日志的 CDC(Debezium) | 可靠、可扩展、准确 | 需要额外的基础设施 |
CDC 并非魔法——但它与数据库内部实际工作方式相吻合。
需要注意的权衡
- Kafka 基础设施是必需的
- 模式更改需要仔细规划
- 回填历史数据可能并非易事
- 运营可视性和监控至关重要
CDC 管道是 系统,而不是一次性脚本。
Debezium 何时适用?
Debezium 是一个很好的选择,当你需要:
- 对每一次数据更改进行近实时传播
- 解耦的下游消费者(分析、缓存、搜索等)
- 强有力的保证,不会遗漏任何更新或删除
- 基于事件流的可扩展、容错架构
如果这些需求与你的项目相匹配,试试 Debezium 吧!
何时使用 CDC
- 您需要近实时的数据移动
- 多个系统依赖相同的数据
- 准确性比简易性更重要
当它可能是过度的
- 数据很少更改
- 批量更新足够
- 简单性是首要任务
结束语
Change Data Capture shifts how you think about data — from snapshots to events.
变更数据捕获(Change Data Capture)改变了你对数据的思考方式——从快照转向事件。
Debezium embraces this model by listening to the database itself, instead of repeatedly asking it questions. That difference is what makes CDC reliable at scale.
Debezium 通过直接监听数据库本身来采用这种模型,而不是反复向其提问。这一差异使得 CDC 在大规模环境下可靠。
If you’ve ever struggled with missed updates, fragile ETL jobs, or inconsistent downstream data, CDC is worth understanding — even if you don’t adopt it immediately.
如果你曾经为错过的更新、脆弱的 ETL 作业或不一致的下游数据而苦恼,了解 CDC 是值得的——即使你并不立即采用它。