开发者用于发布 AI 应用的前8大 Fal.AI 替代方案
I’m happy to help translate the article for you, but I don’t have the full text of the post. Could you please paste the content you’d like translated (excluding any code blocks or URLs you want to keep unchanged)? Once I have the text, I’ll provide a Simplified Chinese translation while preserving the original formatting.
为什么要考虑 Fal.AI 之外的选项?
要说明一点:Fal.AI 在它擅长的领域表现出色。它的重点在于:
- 快速推理
- 简洁的 API
- 托管的 GPU 访问
但现代 AI 应用往往需要的不止一个推理端点。它们需要编排、多模态流水线、全球规模以及生产级可靠性。这正是其他方案开始变得有意义的地方。
1. Hypereal AI

Hypereal 将自己定位为 AI 应用的基础设施层,尤其是处理丰富媒体和实时交互的应用。

Hypereal 背后的核心理念很简单:开发者应该专注于交付 AI 产品,而不是管理 GPU。从模型路由到全局推理,所有工作都由平台处理,让你可以把精力放在功能实现上,而不是基础设施。
关键亮点
- 为多种 AI 模态提供统一的神经接口
- 内置跨 LLM、扩散、音频和视频模型的编排
- 具备预测式自动扩缩的自适应推理
- 为实时场景优化的 <50 ms 延迟路径
- 使用 H100 与 H200 张量核心的专用 AI 计算资源
- 精选的生产级开源模型目录
- 支持实时流式传输的 REST API
- 零实例化(scale‑to‑zero)和按使用付费的计费模式
最适合的场景
- 构建生成式媒体产品的团队
- 实时化身和数字人
- 多模态 AI 应用
- AI 是核心体验而非仅仅一个功能的产品
2. Modal

Modal 为 Python 开发者提供瞬时点击体验。编写 Python 函数,挂载计算资源,让平台负责扩展和执行。
关键亮点
- Python 为先的开发模型
- AI 工作负载的无服务器执行
- 内置 GPU 支持
- 根据需求自动扩展
- 本地代码与生产环境之间的差距最小化
最适合
- 以 Python 为主的团队
- 将模型投入生产的研究人员
- 重视开发者体验的小团队
- 需要在基础设施控制上快速迭代的项目
3. RunPod

RunPod 更偏向于基础设施层面。它为开发者提供 GPU 访问权限,并让他们自行决定需要多少控制权。
关键亮点
- 按需和持久化的 GPU 实例
- 支持自定义容器
- 灵活的计费选项
- 适用于长期运行的推理工作负载
- 与自托管推理服务器配合良好
最适合的场景
- 能够自行管理部署的团队
- 优化 GPU 成本的开发者
- 定制化的推理流水线
推理设置
不适用于无服务器执行模型的工作负载
4. AWS SageMaker
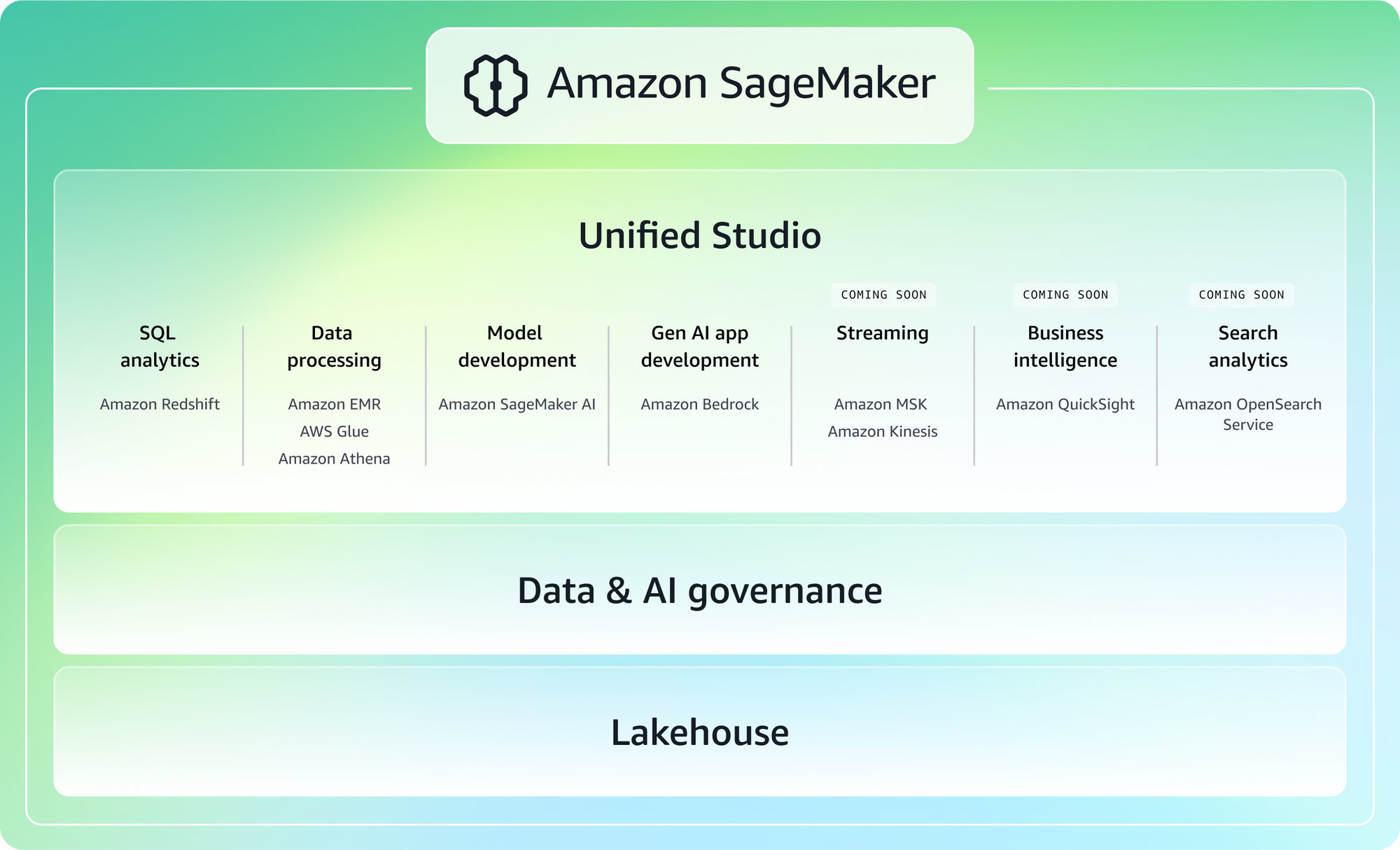
SageMaker 是一个庞大的平台,旨在覆盖整个机器学习生命周期,从训练到部署再到监控。它通常出现在已经深度使用 AWS 的大型组织或团队中。
关键亮点
- 端到端的机器学习生命周期管理
- 托管的训练和推理
- 与 AWS 服务的集成
- 支持大规模机器学习工作流
- 高度关注治理和安全
最适合
- 已在使用 AWS 的企业
- 拥有专职机器学习工程师的团队
- 受监管或合规要求严格的环境
- 需要标准化机器学习流水线的组织
5. Google Vertex AI

Vertex AI 提供一个统一平台,用于构建、训练和部署机器学习模型,重点强调 MLOps。它在希望拥有结构化工作流和长期可维护性的团队中非常受欢迎。
关键亮点
- 统一的训练和推理平台
- 托管的机器学习流水线
- 强大的 MLOps 工具
- 与 Google Cloud 服务深度集成
- 支持自定义模型和工作流
最适合
- 已在 Google Cloud 上的团队
- 将 MLOps 置于优先位置的组织
- 具有复杂机器学习流水线的产品
- 长期、面向生产的机器学习系统
6. Hugging Face 推理端点

如果你使用过开源模型,几乎肯定已经接触过 Hugging Face。他们的推理端点使得可以直接从 Hugging Face Hub 部署模型变得非常简便。
关键亮点
- 直接从 Hugging Face Hub 部署
- 支持流行的 Transformer 模型
- 自定义容器选项
- 简易的基于 API 的访问
- 为机器学习工程师提供熟悉的生态系统
最适合
- 以开源为先的团队
- 以 Transformer 为主的工作负载
- 机器学习工程师原型化生产 API
- 已在使用 Hugging Face 模型的团队
7. Baseten

Baseten 在 AI 推理的“生产”环节投入了大量精力。它专为向用户交付 AI 功能并对可靠性、延迟和可观测性有极高要求的团队而构建。
关键亮点
- 生产级推理 API
- 低延迟模型服务
- 内置可观测性
- 可扩展的部署架构
- 面向真实用户流量设计
最适合的场景
- 负责交付 AI 功能的产品团队
- 对性能要求严格的应用
- 需要大规模可靠性的团队
- AI 驱动的 SaaS 产品
8. Self‑Hosted Inference (Kubernetes + GPUs)
自行运行所有组件可让您拥有完全的控制权,但也需承担全部责任。这通常不是第一步,但对某些团队而言,它是正确的长期选择。
关键亮点
- 对基础设施的完整所有权
- 自定义调度与扩展
- 无供应商锁定
- 兼容 Kubernetes 与 GPU 节点
- 高度可定制的部署流水线
最适合
- 拥有丰富 DevOps 与 MLOps 经验的团队
- 受监管或对安全高度敏感的环境
- 致力于长期成本优化的组织
- 需要完整基础设施控制的产品
我如何在这些平台之间做选择
- AI 是功能还是产品?
- 我是否需要多模态流水线?
- 我想管理多少基础设施?
- 六个月后,扩展会是什么样子?
不同的答案会导致不同的工具。
最终思考
Fal.AI 仍然是许多使用场景的可靠选择。但随着 AI 产品的增长,基础设施决策开始决定什么是可能的 以及 什么是痛苦的。
本列表中的平台体现了围绕 AI 部署的不同理念。有的侧重简洁,有的侧重控制,还有的侧重生产规模的编排。没有唯一的“最佳”选项,只有最适合你的。
如果说我学到了一件事,那就是:
最好的 AI 平台是那种在你的产品真正起飞后,你不必更换的平台。