时序数据库 vs. 关系型数据库,区别是什么
I’m ready to translate the article for you, but I’ll need the text you’d like translated. Could you please paste the content (or the portion you want translated) here? Once I have it, I’ll provide the Simplified Chinese version while keeping the source line and formatting intact.
介绍
许多团队默认使用关系型数据库,因为它们熟悉且通用。对于业务系统来说,这种选择通常是正确的。
但当工作负载发生转变——从可变的业务记录转向高频率的遥测流时——数据库架构就会以截然不同的方式变得重要。
并非所有数据问题都是关系型的,也并非所有数据库都是为时间而设计的。
Relational databases (RDBMS) 为电子商务平台、物流平台和 ERP 系统等企业系统提供动力,得益于其通用建模能力和强大的事务保证。
Time‑series databases (TSDB) 则专为时间索引数据而构建,广泛用于工业物联网、能源系统、可观测性平台、监控基础设施以及金融时间序列分析。
为了了解何时适合使用每种数据库,我们将在五个架构维度上进行比较。
Source: …
1. 事务机制:核心 vs. 常常次要
关系型数据库 – ACID 是基础
关系型数据库支持 ACID 事务,确保原子性、一致性、隔离性和持久性。
示例 – 银行转账
| 步骤 | 操作 |
|---|---|
| 1 | 账户 A 扣除 $10 |
| 2 | 账户 B 贷入 $10 |
两个操作必须要么一起成功,要么一起失败。如果系统崩溃或网络故障在操作中途发生,数据库必须回滚以保持一致性。
为在分布式系统中实现这一点,RDBMS 引擎维护:
- 前写日志(WAL)
- 状态跟踪
- 并发控制机制
- 回滚和恢复协议
事务完整性是核心需求,因为业务数据经常被修改并且会受到并发更新的影响。
时序数据库 – 对于写入,事务往往不那么关键
在许多工业物联网写入工作负载中,数据来源于传感器。每条记录代表特定时间戳下的真实测量(例如温度、风速、电压)。
典型特征:
- 仅追加数据
- 每条记录相互独立
- 没有多行原子更新
- 没有写写冲突
在这些工作负载中,繁重的事务协调会带来额外开销,却没有相应的价值。因此,TSDB 系统会在事务复杂性与写入规模之间进行权衡——优先考虑高吞吐、稳定的流式写入。
2. 写入模式:一致性‑中心 vs. 吞吐量‑中心
关系型数据库 – 强模式 & 一致性
RDBMS 通常存储:
- 配置数据
- 人员记录
- 业务实体
- 金融交易
数据通常通过结构化表单录入,必须严格符合预定义的模式和约束。由于事务语义:
- 写入被分组
- 整个批次提交或回滚
- 一致性优先于原始吞吐量
这种设计适用于对相关实体正确性要求极高的系统。
时序数据库 – 极致写入吞吐
时序工作负载差异巨大:
- 数据来源于传感器或设备
- 设备数量可从数千到数百万不等
- 采样间隔可能是秒或毫秒
- 写入速率可达每秒数千万个点
TSDB 系统为以下目标而构建:
- 高并发写入
- 高吞吐量
- 无序数据处理
示例 – Apache IoTDB 利用其底层存储格式 Apache TsFile,实现:
- 列式数据写入
- 毫秒级数据访问
- 针对不稳定网络环境的无序分离存储机制
- 在基准测试场景下的稳定高吞吐写入
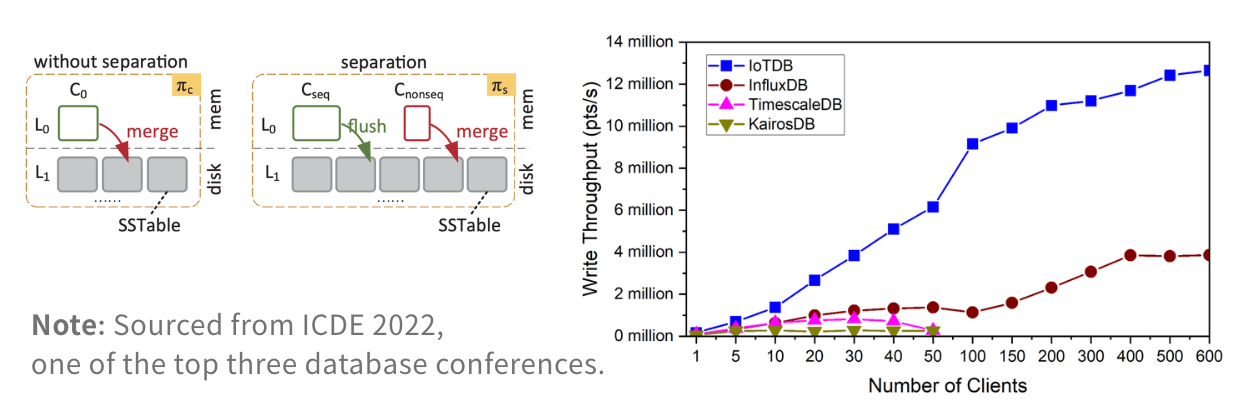
3. 存储与压缩:通用型 vs. 时间序列优化型
关系型数据库 – B+ 树与通用压缩
RDBMS 存储引擎通常使用:
- B+‑tree 索引
- 行式或混合存储
- 通用压缩算法(LZ77、DEFLATE 等)
压缩是可选的,并根据工作负载需求进行调优。存储格式针对多维查询和事务一致性进行优化。
时间序列数据库 – 时间序列优化存储
时间序列数据具有可被存储引擎利用的结构特性:
- 强时间局部性
- 顺序追加模式
- 连续数据点之间的微小差异
这些特性使得以下技术成为可能:
- 列式存储
- 行程长度编码(RLE)
- 差分编码
- 专用压缩算法
在 IoTDB 中,底层格式 Apache TsFile 提供:
- 多维索引(设备、传感器、时间戳)
- 快速时间范围过滤
- 相比通用格式,查询吞吐量提升 5–10 倍
- 压缩率最高提升至 15 倍
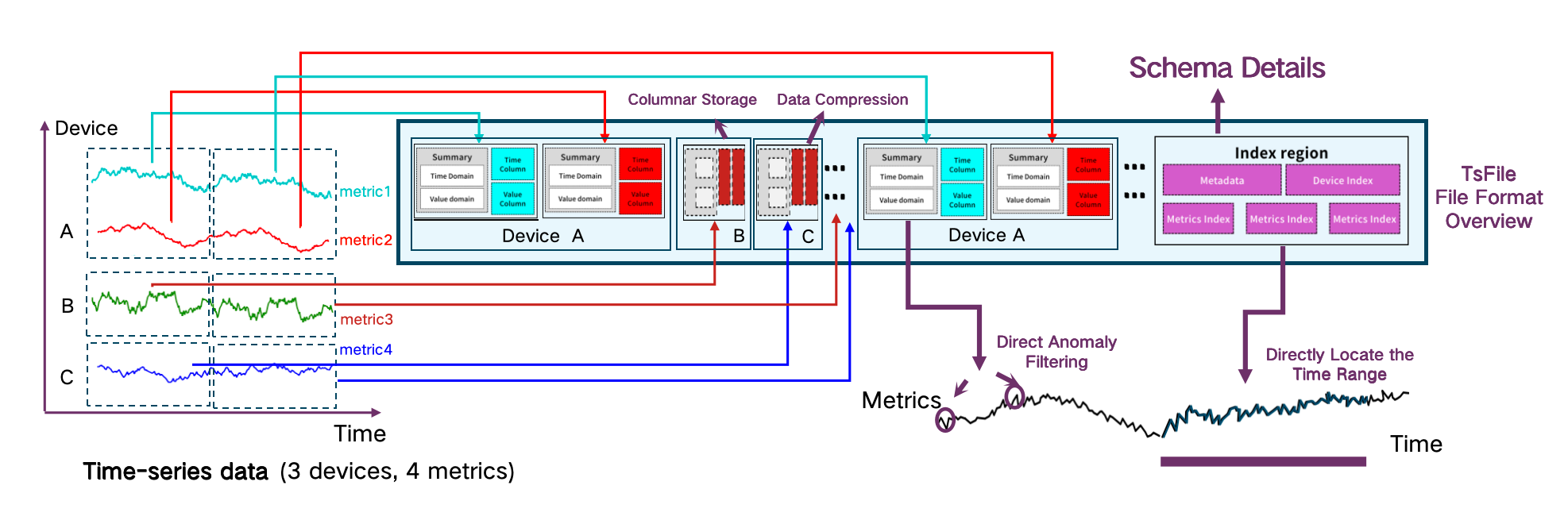
上述比较突显了关系型数据库在一致性关键、基于模式的工作负载中的优势,而时间序列数据库在处理海量、仅追加、带时间戳的流数据时的优势。
查询模式:精确检索 vs. 时间维度分析
关系型数据库 – 基于实体的查询
典型的 SQL 结构:
SELECT -- select target columns
FROM -- define the source table
WHERE -- set filtering conditionsRDBMS 的优势
- 精确过滤
- 多表连接
- 复杂业务逻辑查询
- 外键关系
目标是准确的实体检索以及结构化数据集之间的关系一致性。
时序数据库 – 大规模时间分析
常见的 TSDB 查询特征:
- 对数周、数月或数年的趋势分析
- 对数十万条数据点的大规模聚合
- 高频仪表盘刷新(例如,每秒数百个指标)
用户期望
- 高查询吞吐量
- 高效的时间窗口过滤
- 原生时序处理能力
IoTDB 的能力
- 通过 TsFile 实现高吞吐量的时间范围查询
- 为可视化提供下采样
- 大约 100 种内置时序函数(分段、缺口填补、数据修复等)
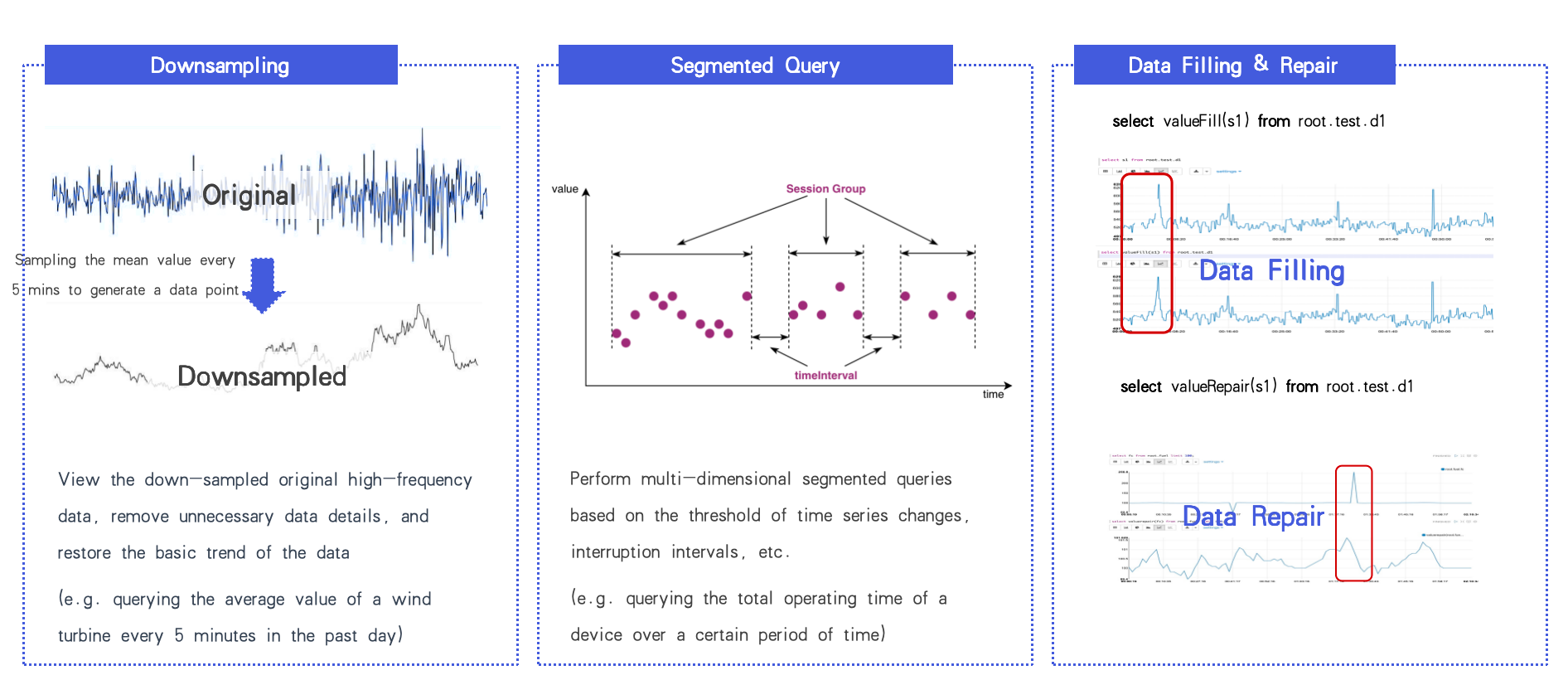
数据流通:集中管理 vs. 边缘‑云协作
关系型数据库 – 平台中心存储
典型的 RDBMS 使用方式:
- 存储内部业务数据
- 使用专有存储格式
- 为集中式应用工作负载提供服务
系统演进时,数据迁移通常需要进行格式转换。
时序数据库 – 边缘‑云同步
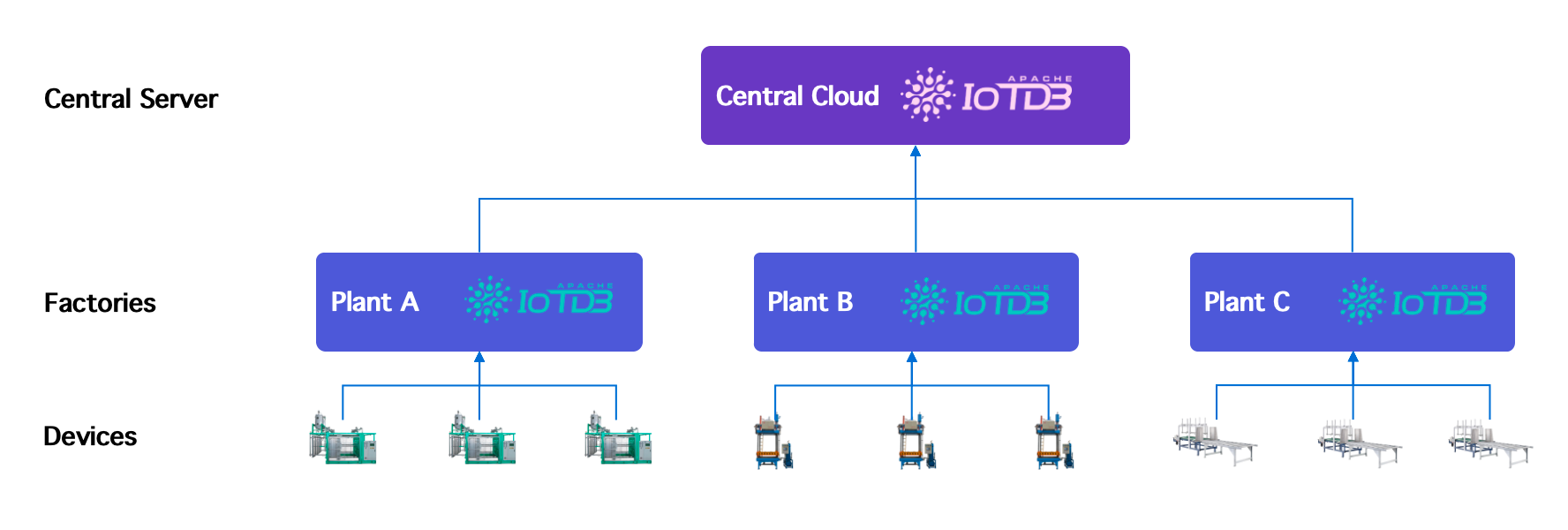
工业物联网架构通常遵循以下流程:
Devices → Edge nodes → Regional data centers → Central cloud platforms可能的额外约束包括:
- 生产网络隔离
- 单向数据网关
- 带宽限制
TSDB 优化目标
- 高效的跨终端同步
- 低带宽复制
- 最小化 CPU 开销
- 基于文件的传输
IoTDB 通过统一的 TsFile 格式满足这些需求,实现:
- 基于文件的数据交换
- 基于订阅的同步
相较于重新摄取的方式,带来的收益:
- 网络带宽节省最高可达 90 %
- 接收节点 CPU 节省最高可达 95 %
结论
The differences between time‑series databases and relational databases stem fundamentally from the nature of the data they serve.
| 维度 | 关系型数据库 | 时间序列数据库 |
|---|---|---|
| 数据模型 | 实体关系 | 时间索引指标 |
| 事务 | 必要 | 对于写入密集型工作负载而言不太核心 |
| 写入重点 | 一致性 | 高吞吐量 |
| 存储 | B+树,通用压缩 | 时间优化的列式存储格式 |
| 查询方式 | 多表精确查询 | 大规模时间分析 |
| 数据流 | 应用中心 | 边缘‑云协作 |
When choosing between a TSDB and an RDBMS, organizations should evaluate:
- 数据生成模式 – 数据是否与时间相关?
- 写入吞吐量要求
- 查询复杂度
- 边缘到云的同步需求
- 基础设施约束
选择正确的数据库架构不仅是技术偏好——它直接影响可扩展性上限、基础设施成本和长期运营效率。
注意: 这不是逐项特性比较;而是工作负载与架构的决策。