Svelte 编译器提升了 55% 的速度。修复只用了 3 个文件。
Source: Dev.to


来自奥斯陆的一位开发者在这个 PR 提交前三天打开了一个 GitHub issue。他的问题很简单:
“Svelte 在提升工具性能方面有什么路线图吗?”
Rich Harris 的回答更简短:没有正式的路线图。先进行性能分析,然后修复发现的问题。
于是 Mathias Picker 正是这么做的。他对 Svelte 编译器进行了性能分析,发现了两个隐藏在两个子系统交叉点的算法问题,并提交了一个只涉及三个代码文件的 pull request。
Rich Harris 的审查意见: “太棒了!”
该 PR 当天就合并了。Svelte 编译器的分析阶段提升了 20 %–55 % 的速度。但差异文件并没有显示出以下事实:其中一个文件 state.js 是在所有三个编译阶段被 30 个文件 共享的全局状态。对它的修改会影响 2,036 个下游文件。
GitHub 说: 4 个文件被更改。
依赖图说: 2,036。
The PR
sveltejs/svelte#17823 — “perf: optimize compiler analysis phase”
Svelte 的编译器分为三个阶段:
- Parse – 文本 → AST
- Analyze – 提取含义(作用域、响应性、CSS 剪枝)
- Transform – 生成 JavaScript
分析阶段是编译器确定作用域、响应性和 CSS 剪枝的地方——正是这一步让 Svelte 产生魔法般的体验。
其中隐藏了两个问题。
Problem 1: CSS 剪枝对每个元素遍历样式表一次
编译器需要确定哪些 CSS 规则实际应用于哪些元素——未使用的规则会被剪除。旧代码对每个元素循环,并对每个元素遍历整个 CSS AST:
// Before: O(n × m) — n elements, m CSS rules
for (const node of analysis.elements) {
prune(analysis.css.ast, node); // walks entire stylesheet each time
}对于 50 个元素和 100 条 CSS 规则,这意味着对样式表 AST 进行 50 次完整遍历。
Fix: 反转循环——只遍历一次样式表,在每个选择器内部匹配元素。
// After: one walk, elements matched inside
prune(analysis.css.ast, analysis.elements);问题 2:在每个 AST 节点上深度克隆堆栈
Svelte 支持 “ 注释来抑制警告。编译器在一个堆栈中跟踪这些注释。旧代码在 每个 AST 节点 上调用 structuredClone(ignore_stack),即使 ignore 注释在每个组件中只出现 0–5 次:
// Before: deep‑clone on every AST node visit
ignore_map.set(node, structuredClone(ignore_stack));一个典型的组件有 500–2,000 个 AST 节点。这意味着对几乎从不改变的数组进行 500–2,000 次深度克隆。
修复: 缓存快照,仅在 push_ignore 或 pop_ignore 实际改变堆栈时重新构建它。
export function get_ignore_snapshot() {
if (cached_ignore_snapshot === null) {
cached_ignore_snapshot = ignore_stack.map((s) => new Set(s));
}
return cached_ignore_snapshot;
}结果(500 次编译后)
| 组件 | 之前 | 之后 | 加速 |
|---|---|---|---|
| 80+ 选择器,12 个元素 | 3.405 ms | 2.680 ms | 21 % |
嵌套 each 块 | 2.034 ms | 1.575 ms | 23 % |
| 100 条规则,50 个元素 | 10.099 ms | 4.564 ms | 55 % |
三个文件。两处修复。显著的性能提升。
Source: (保持原样,不翻译)
依赖图展示的内容
GitHub 的 diff 隐藏了这三个文件在 Svelte 架构中的位置(第四个被修改的文件是 .changeset 元数据条目——没有代码)。

文件位置
| 文件 | 位置 | 角色 | 导入影响 |
|---|---|---|---|
state.js | packages/svelte/src/compiler/state.js | 共享全局状态(警告、文件名、源码、忽略栈) | 被 30 个文件 在所有三个阶段中导入 |
index.js | packages/svelte/src/compiler/phases/2-analyze/index.js | 分析阶段入口点 | 为每个组件组织分析遍历 |
css-prune.js | packages/svelte/src/compiler/phases/2-analyze/css/css-prune.js | 执行 CSS 死代码消除 | 决定哪些 CSS 规则适用于哪些元素 |
当你在 3‑D 图中选中 state.js 并展开其冲击半径时,涟漪立刻出现:在所有三个阶段中有 30 个直接导入者,这些导入者又进入阶段入口点,阶段入口点再进入编译器根节点,编译器根节点又被每个测试套件使用。当涟漪停止时,3,301 个文件中有 2,036 个被点亮——62 % 的整个 Svelte 代码库,仅因对这三个文件的更改。
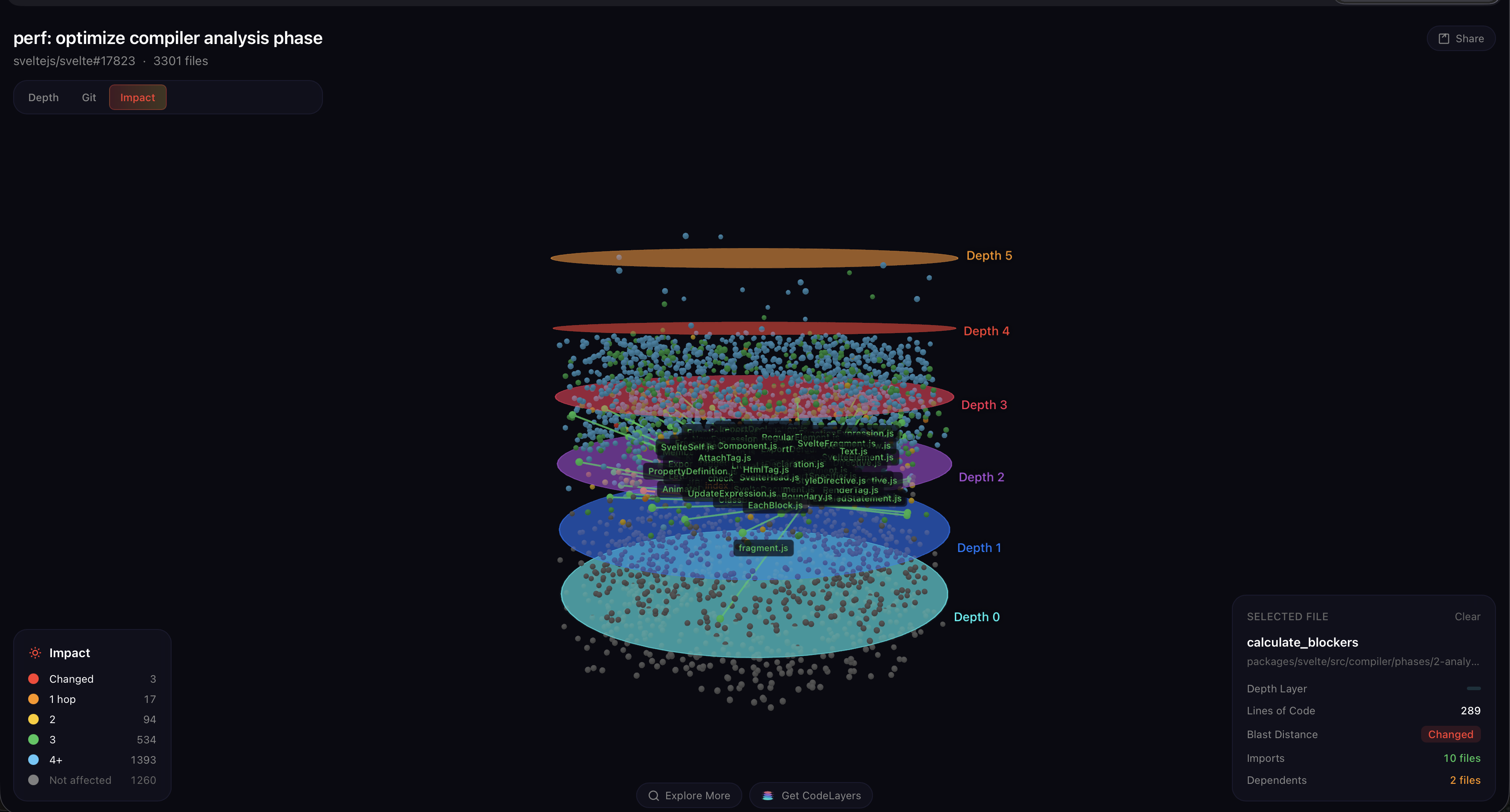
This is the insight a flat diff view can’t give you. `state.js` is the most connected file Mathias touched — it’s not in the analysis phase at all, it’s *below* it, shared by everything. That’s why these optimizations matter so much: the code paths he fixed run on **every AST node of every component**, inside a module that the entire compiler depends on. A 3‑file fix with a 2,000‑file blast radius — because the files are load‑bearing.更大的故事
Mathias 并没有只停留在一个 PR。八天内他打开了 五 个性能相关的 pull request:
| PR | 修复内容 | 加速 | 查看 |
|---|---|---|---|
| #17811 | Parser hot paths | 18 % faster | View in 3D |
| #17823 | Analysis phase (this PR) | 21‑55 % faster | View in 3D |
| #17839 | Element interactivity caching | ~8 % faster | — |
| #17844 | O(n²) scope‑name scanning | ~10 % faster | View in 3D |
| #17846 | CSS selector pruning | ~16 % faster | View in 3D |
全部由 Rich Harris 合并,并在数天内发布。
这一切始于一个问题:“Svelte 在提升工具性能方面的路线图是什么?”
答案竟是:一名使用分析器的开发者,八天时间,五个 pull request。
亲眼看看
我们把这个 PR 通过 CodeLayers Explore 运行了一遍——只需粘贴任意 GitHub PR 的 URL,即可获取交互式 3‑D 依赖图。下面是 sveltejs/svelte#17823:
- 点击任意节点。
- 旋转图形。
- 选中已更改的文件,观察冲击半径在深度环中的扩散。
- 查看分析阶段相对于解析器和转换器的位置。
想在自己的 PR 上获得同样的可视化吗?
- VS Code 插件 – 在编码时内联显示冲击半径(树视图、侧边装饰、跨 11 种语言的 CodeLens 注释)。本地运行,数据不离开你的机器。
- GitHub Action – 在每个 PR 上自动发布 3‑D 可视化链接。两分钟即可完成配置,审阅者立刻看到 diff 所无法展示的内容。
这就是 Blast Radius #1 —— 一个每周系列,我们将真实的开源 PR 通过 3‑D 依赖图进行可视化,展示 diff 漏掉的细节。有什么 PR 想让我们可视化?在 Bluesky 找到我们。