使用 AI 编码代理时,大多数开发者错过的第一技能
Source: Dev.to
(未提供要翻译的正文内容。如需翻译,请提供文章的具体文本。)
AI 编码代理的争论
关于 AI 编码代理的争论遗漏了最重要的因素。问题不在于提示工程,而在于理解上下文窗口。
开发者们意见分歧:
- 一方声称 “编码代理很糟糕。”
- 另一方坚持 “是你使用方式不对;这是技能问题。”
两种观点都有其道理,但最常见的技能问题并非提示工程,而是对工具主要限制的根本误解。
我在开发者中最常看到的技能问题,并不是缺少提示工程,而是没有充分考虑上下文窗口。
什么是上下文窗口?
上下文窗口 是大型语言模型在单次会话中处理的全部输入和输出 token 的集合。可以把它看作模型的 工作记忆——在生成回复时模型能够看到并考虑的所有信息。
它包括:
- 输入 Token – 你的系统提示、指令以及用户消息。
- 输出 Token – 助手生成的回复。
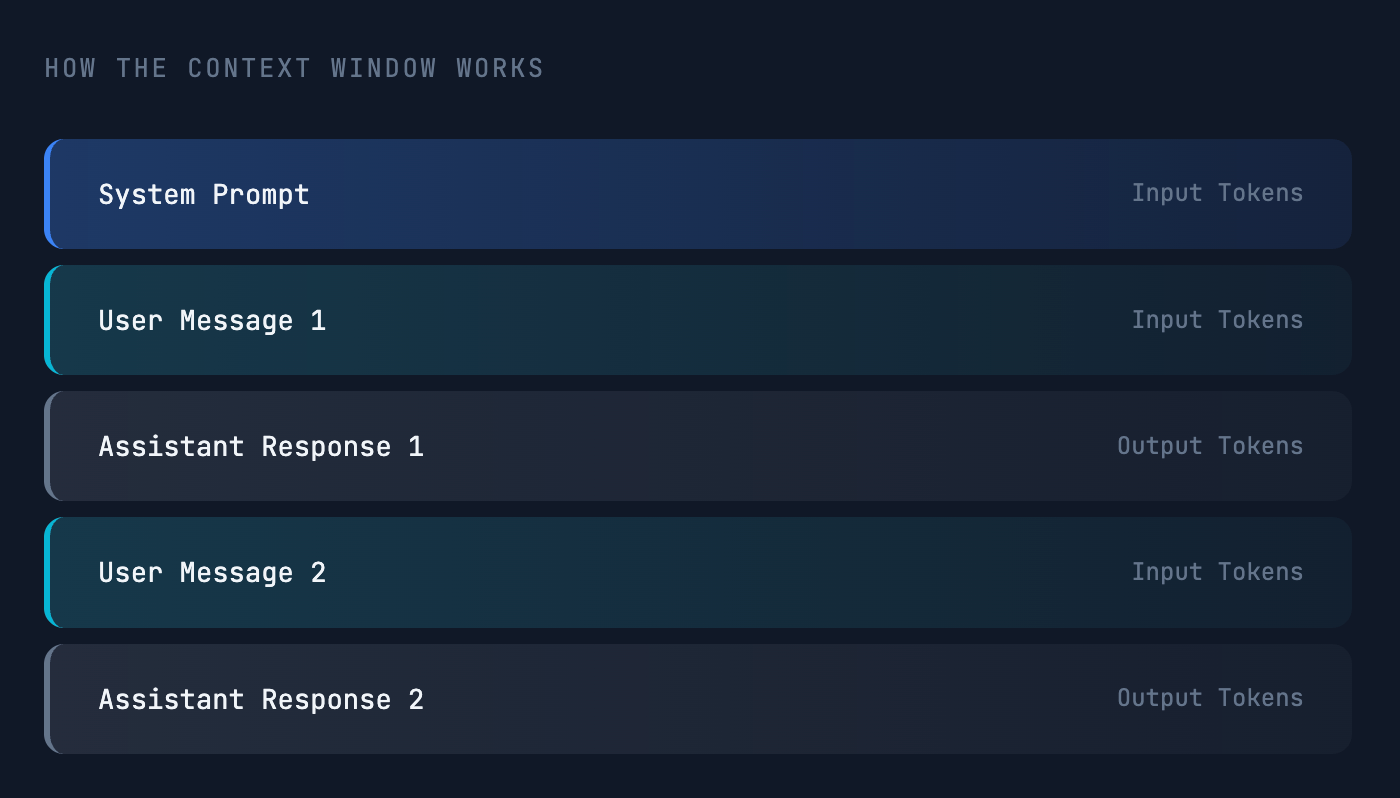
随着对话的进行,token 数量会不断增加。最终你会触及模型提供商设定的上限。这可能发生在对话过长 或 单次输入过大(例如上传大量文档)时。超过上限会导致错误,生成会被冷却停止。
2025年的上下文窗口
模型提供商根据架构和成本设定不同的限制。限制范围可以从几千个 token 到几百万个 token 不等,但 更大并不一定更好。

Gemini 的上下文窗口确实非常大,但正如我们将看到的……更大并不一定更好。
悖论:上下文越多,性能越差
违反直觉的真相: 给模型提供的信息越多,它在检索特定细节时的表现越差。这适用于所有模型,从最小的到最大的。
为什么无限上下文不存在
-
成本与内存
大语言模型的处理成本很高。更大的上下文会显著增加每次请求的内存消耗,从而提升计算成本和延迟。 -
性能下降
大语言模型的注意力 并非在整个上下文中均匀分布。对话最开头和最结尾的 token 对输出的影响最大。中间的 token 常常 被降级或完全忽视。
这被称为 “中间丢失”(Lost in the Middle)问题。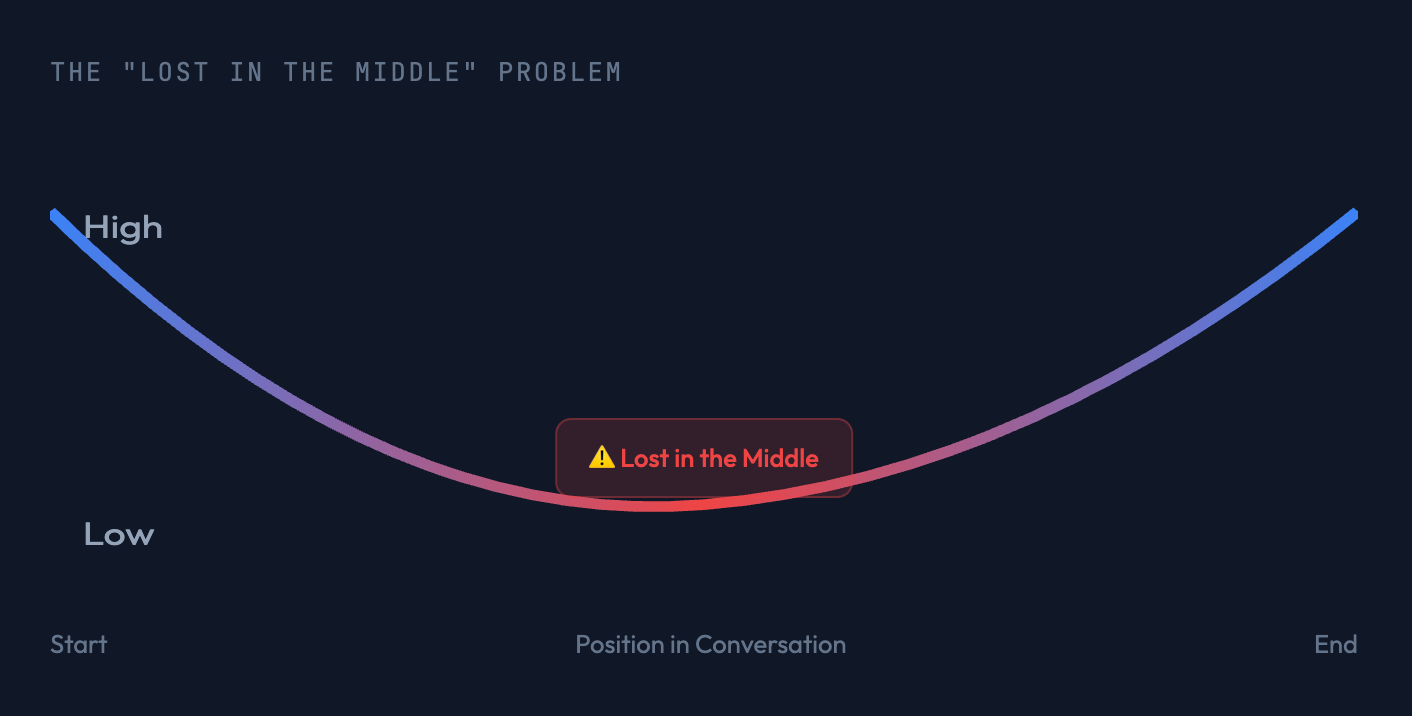
这不是 bug,而是 transformer 架构的涌现属性。它映射了人类的认知偏差:
- 首因效应 – 对开头项目的记忆更好。
- 近因效应 – 对结尾项目的记忆更好。
就像人类一样,模型在信息更少、更聚焦的情况下表现更好。
案例研究:如果模型无法利用,千万令牌窗口毫无用处
当 Meta 宣布推出拥有 1000 万令牌 上下文窗口的模型时,这似乎是一项突破。但在实际测试中,很快就暴露出严重的 中间丢失(lost‑in‑the‑middle) 问题。你可以向模型输入海量信息,却发现它无法有效检索或利用这些信息。
在评估大型语言模型(LLM)时,别只看上下文窗口有多大。要看它能多好地从该窗口中检索信息。
解决方案:保持上下文简洁聚焦
更短的上下文窗口较少出现 lost‑in‑the‑middle(中间丢失)问题。提升性能的关键是 主动管理:
- 定期清除编码代理的聊天记录,以刷新其“记忆”,确保你的指令保持高优先级。
- 这是提升结果的最有效方法。
第一步 – 完全透明地了解你的上下文使用情况
你无法管理你无法衡量的东西。一个优秀的编码代理会提供工具来检查当前上下文窗口的状态。例如,在 Cursor 中:

第2步 – 将 clear 设为默认操作
当你开始一个全新的、无关的任务——或是上下文使用率变高(例如,可用的 token 少于 5 万)时,最佳做法是彻底清除对话历史。这会释放整个上下文窗口,为你提供一个全新的空白页,并确保新任务的最佳性能。

第3步 – 在需要保留对话意图时使用 compact
compact 是一种替代方案,它会清除详细历史,但生成由 LLM 驱动的摘要。这样可以在更小的体积中保留对话的 氛围 或核心目标。

这保留了一些意图……就像为此对话准备的迷你规则文件。
注意: 生成摘要本身需要时间并消耗 token。
警告:隐藏上下文可能破坏性能
在使用会添加大量隐藏上下文的工具和配置时务必格外小心。这会从一开始就膨胀你的窗口,将实际对话推入可怕的 中部。
常见罪魁祸首
- LSP/MCP 服务器 – 可能向系统提示注入巨量工具集。
- 大型规则文件 – 在 Cursor、Claude Code 等工具中使用过于复杂或数量过多的自定义规则。
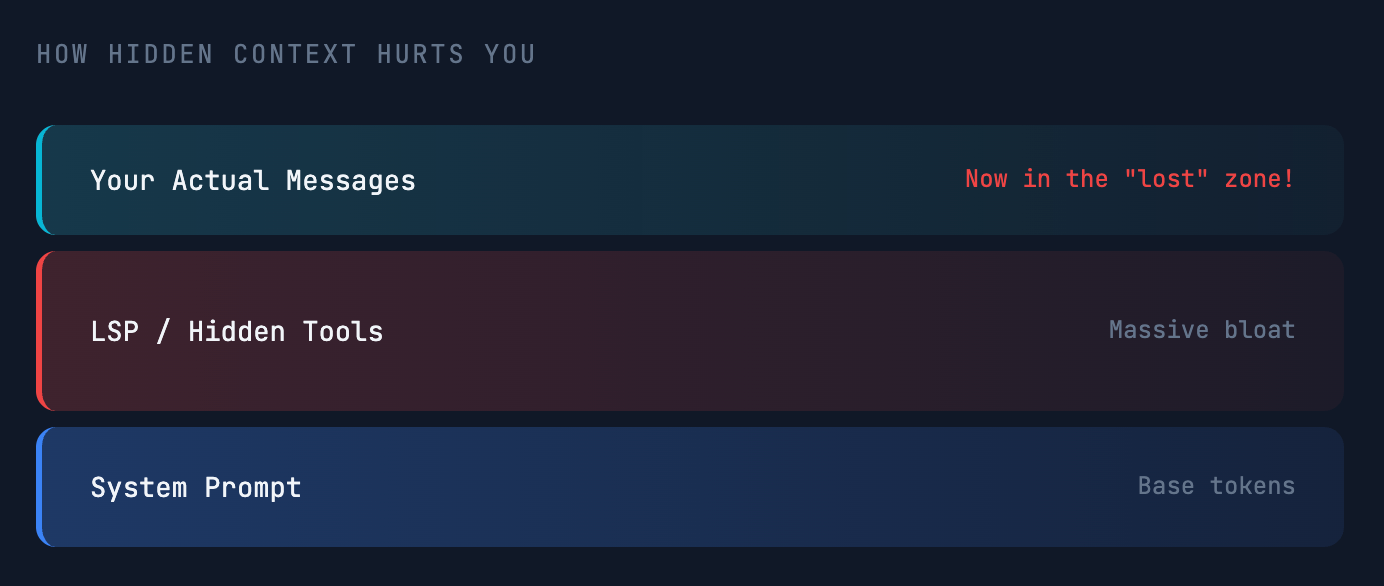
当隐藏工具占用了大部分上下文时,你的实际信息就会落入 中部丢失 区域,而模型在该区域的注意力最少。
关键要点
- 上下文窗口是模型的全部记忆(输入 + 输出)。 随着对话的增长,它会很快被填满,性能会受到影响。
- 所有模型都有硬编码的限制,并且会受到中间丢失注意力衰减的影响。 即使是百万标记的窗口也无法免疫此问题。
- 更简洁、更聚焦的上下文始终能带来更好的性能。 早期清晰,频繁清晰。
新思维模式
对你的上下文保持适度的警惕。使用 clear 和 compact 等工具主动管理它。这项技能能够将令人沮丧的交互与与 AI 的高效合作区分开来。
掌握上下文窗口是取得卓越成果的关键。