Spinlocks vs. Mutexes:何时自旋,何时休眠
发布: (2025年12月8日 GMT+8 08:38)
4 分钟阅读
原文: Hacker News
Source: Hacker News
引言
你正盯着 perf top,看到 60 % 的 CPU 时间花在 pthread_mutex_lock 上。延迟糟透了。有人建议“直接用自旋锁”,结果你的 16 核服务器瞬间 100 % 占用,却什么也没干。这就是同步原语的陷阱:工程师常因为不了解各自的适用场景而选错原语。
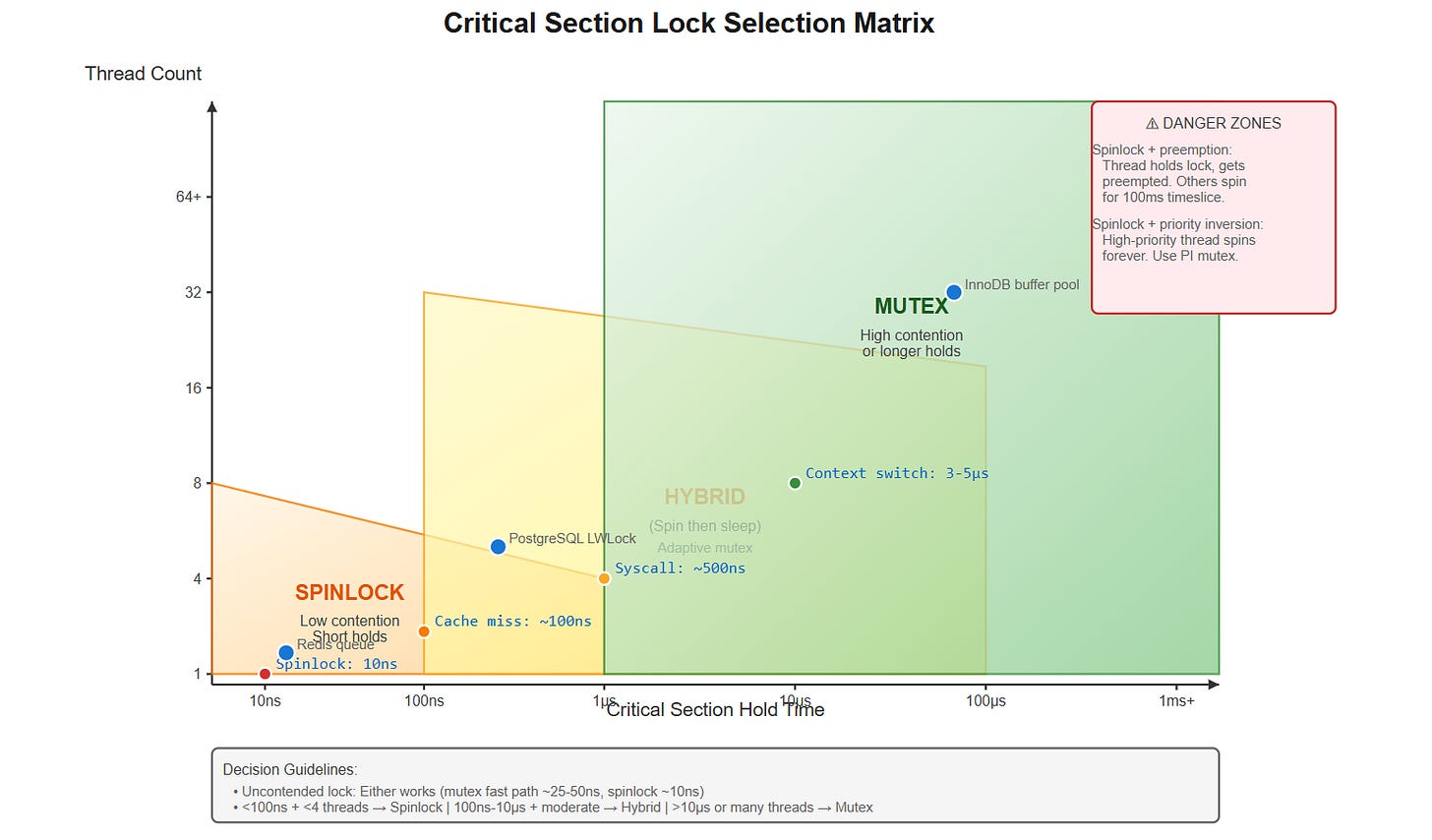
自旋锁 vs. 互斥锁
| 属性 | 互斥锁 | 自旋锁 |
|---|---|---|
| 行为 | 发生争用时会睡眠。 | 在用户态忙等(自旋)。 |
| 无争用时的开销 | 25–50 ns(快速路径) | 一次原子 LOCK CMPXCHG(≈40–80 ns)。 |
| 有争用时的开销 | 系统调用 (futex(FUTEX_WAIT)) ≈ 500 ns + 上下文切换(3–5 µs)。 | 循环时占用 100 % CPU;每次失败的尝试都会在核心之间来回抖动缓存行。 |
| 可抢占的上下文 | 安全——线程可以被调度下去。 | 危险——如果持锁者被抢占,其他线程会浪费整整一个时间片。 |
| 优先级反转 | 可通过优先级继承(PI)互斥锁解决。 | 无法解决;高优先级线程可能永远自旋,而低优先级持锁者根本得不到运行机会。 |
| 伪共享 | 同样的问题——每次原子操作都会使缓存行失效。 | 同样的问题——需要额外注意对齐锁结构。 |
何时使用哪种原语
| 临界区持续时间 | 争用程度 | 推荐原语 |
|---|---|---|
| ** 10 µs** 或 高争用 | 高 | 常规互斥锁——让调度器处理睡眠/唤醒。 |
| 实时需求 | 任意 | 在 PREEMPT_RT 内核上使用优先级继承互斥锁。 |
性能分析技巧
CPU 与上下文切换 – 运行:
perf stat -e context-switches,cache-misses- 高上下文切换计数且 CPU 使用率低 → 互斥锁开销可能占主导。
- 高缓存未命中且 CPU 100 % → 锁争用 / 伪共享。
系统调用计数 – 使用
strace -c统计futex()调用。每秒数百万次表明该锁争用激烈,可能需要分片或无锁技术。自愿 vs. 非自愿切换 – 查看
/proc/<pid>/status。在持自旋锁期间出现非自愿切换,说明存在抢占问题。
实际案例
Redis – 为其小型任务队列使用自旋锁(临界区)。
#include <pthread.h> #include <stdatomic.h> #define NUM_THREADS 4 #define ITERATIONS 1000000 #define HOLD_TIME_NS 100 // 模拟工作 typedef struct { atomic_int lock; long counter; } spinlock_t; static void spinlock_acquire(spinlock_t *s) { int expected; do { expected = 0; } while (!atomic_compare_exchange_weak(&s->lock, &expected, 1)); } static void spinlock_release(spinlock_t *s) { atomic_store(&s->lock, 0); } static void *worker_thread(void *arg) { spinlock_t *s = (spinlock_t *)arg; for (long i = 0; i < ITERATIONS; i++) { spinlock_acquire(s); s->counter++; /* 模拟约 100 ns 的工作 */ for (volatile int j = 0; j < HOLD_TIME_NS; j++) { // busy‑wait } spinlock_release(s); } return NULL; }
插图