Power BI 中的模式与数据建模
Source: Dev.to
数据建模是对表进行结构化并定义关系的过程,以便 Power BI 能够:
- 正确聚合数据
- 高效过滤数据
- 生成准确的度量值
- 即使在大型数据集下也能快速运行
把它想象成在用可视化装饰报告之前先设计报告的蓝图。
星形模式概述
星形模式是一种成熟的建模方法,被关系型数据仓库广泛采用。
它要求建模者将模型表分类为 维度 或 事实。
维度表
维度表描述业务实体——即你建模的事物。
实体可以包括产品、人员、地点、概念,甚至时间本身。
- 维度表包含一个 键列(或多个键列),作为唯一标识符,并附加用于过滤和分组的其他列。
- 在星形模式中最一致的表是 日期维度 表。
事实表
事实表存储观察或事件(例如,销售订单、库存余额、汇率、温度)。
- 事实表包含指向维度表的 维度键列 和 数值度量列。
- 维度键列决定事实表的 维度性,而键 值 决定其 粒度。
示例 – 一个存储销售目标的事实表有两个维度键列:
Date和ProductKey。
- 该表有两个维度(日期和产品)。
- 如果
Date列存储每月的第一天,则粒度为 月‑产品级别。
通常,维度表的行数相对较少,而事实表的行数可以非常多,并且会随时间持续增长。

图 1.1 – 星形模式布局
规范化 vs. 反规范化
要理解星型模式的概念,首先需要了解两个术语:
规范化 – 通过减少重复来存储数据。
示例:一个产品表使用唯一的ProductKey并包含描述性列(名称、类别、颜色、尺寸)。销售表只存储ProductKey,这就是规范化的做法。
图 1.2 – 规范化的销售表(仅包含 ProductKey)反规范化 – 为了便利或性能而存储冗余数据。
示例:一个销售表同时包含产品名称、类别等信息。
图 1.3 – 反规范化的销售表(ProductKey + 产品属性)
当您从导出文件或数据提取中获取数据时,通常已经是反规范化的。使用 Power Query 将源数据转换并塑形为多个规范化表。
注意: 虽然应当力求事实表和维度表保持规范化,但有时会有意将雪花维度进行反规范化,以生成单一的模型表。
Source: …
星形模式与 Power BI 语义模型的相关性
星形模式设计以及上述概念与构建既高性能又易于使用的 Power BI 模型密切相关。
- 每个 Power BI 可视化都会针对语义模型生成一个查询。
- 查询通常会 过滤、分组 和 汇总 数据。
因此,一个设计良好的模型应提供:
- 用于过滤和分组的 维度表。
- 用于汇总的 事实表。
目前没有显式属性可以将表标记为“维度”或“事实”。表的角色是通过 模型关系 推断的:
- 关系的 基数(一对多或多对一)决定表的类型。
- “一”端 始终是 维度表;“多”端 始终是 事实表。

图 1.4 – 一对多关系(维度 → 事实)
Source: …
雪花维度
雪花维度是一组规范化表,用于表示单个业务实体。
例如,在 Adventure Works 数据仓库中,产品按 类别 和 子类别 进行分类:
- 一个产品属于一个子类别。
- 一个子类别属于一个类别。
因此,产品维度存储在三个相关的规范化表中。
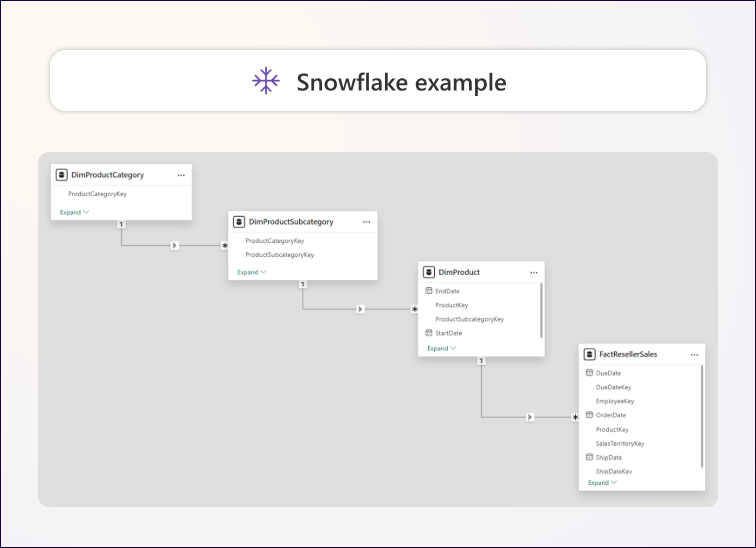
图 1.5 – 产品维度的规范化表。
如果你把这些规范化表想象成从事实表向外辐射的结构,就可以看到经典的“雪花”形状。
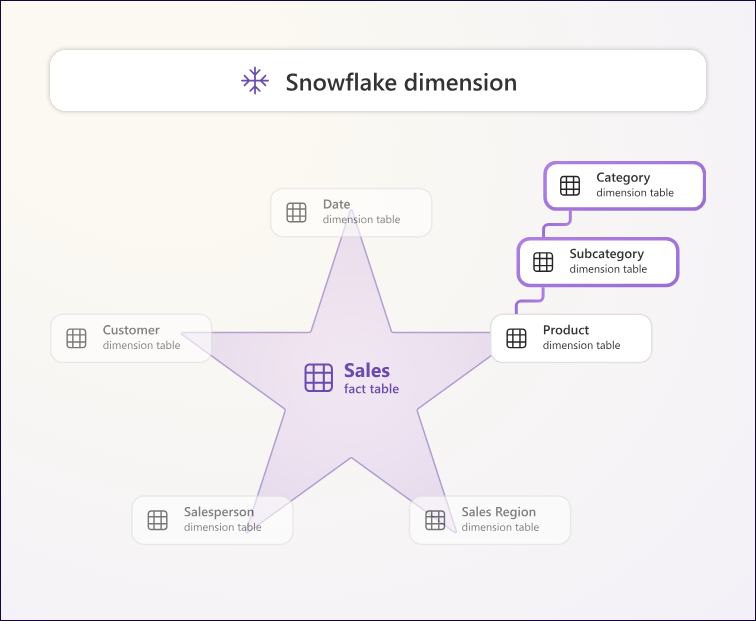
图 1.6 – 雪花设计示意图。
Power BI Desktop 中的雪花 vs. 反规范化设计
在 Power BI Desktop 中,你可以:
- 模拟雪花维度设计(通常因为源数据已经是规范化的),或
- 将源表合并为单个反规范化的模型表。
一般来说,单个模型表能提供更多好处,但最佳选择取决于数据量和可用性需求。
当你模拟雪花维度设计时
- 存储与性能: 加载的表更多,效率可能较低。每个表必须包含支持关系的列,导致模型体积增大。
- 过滤传播: 必须遍历更长的关系链,可能降低过滤效率。
- 用户体验: 数据窗格中会显示许多表,容易让人困惑——尤其是雪花表只包含一两列时。
- 层次结构: 不能创建跨多个表列的层次结构。
当你将数据整合到单个模型表时
- 层次结构: 可以定义覆盖维度完整粒度(从最高层到最低层)的层次结构。
- 存储影响: 冗余的反规范化数据可能会增加模型大小,尤其是对于大型维度表。
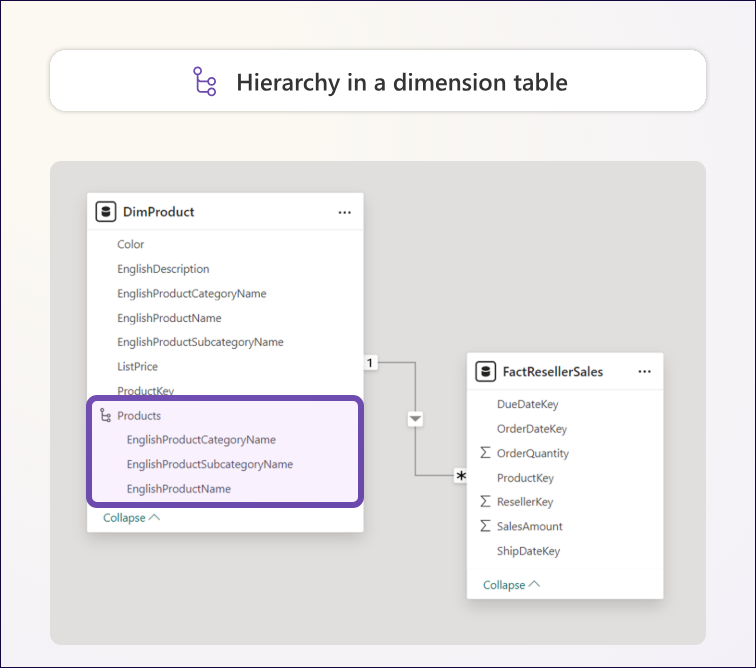
图 1.7 – Power BI 中雪花设计与反规范化设计的比较。
关键要点
为您的具体场景选择在性能、存储和用户体验之间取得平衡的设计。当源数据已经规范化时,Snowflake 设计可能有用,但精心设计的非规范化模型通常能提供更好的性能和更直观的报表体验。