SageMaker Unified Studio:您的一站式 AWS 分析平台
Source: Dev.to
Overview
SageMaker Unified Studio(后文中我们将使用 SUS 作为缩写)如果你来自传统的、单独的 AWS 分析服务,可能会感到有些混乱——因为它把你已经熟悉的所有服务都包装在一起:
| Service | Purpose |
|---|---|
| S3 | 存储 |
| Lake Formation | 细粒度权限的数据治理 |
| Glue | Spark 工作负载与数据目录管理 |
| Redshift | 数据仓库 |
| Athena | 即席 SQL 查询 |
| SageMaker Notebook | 运行 Python 脚本或连接到 Glue Interactive Sessions |
| Bedrock | 生成式与代理式 AI 组件 |
| Amazon Q | AI 辅助的代码生成(SQL 与 Python) |
| DataZone | 业务目录、项目管理、跨域数据共享 |
| EMR | 使用 Spark 的大数据处理 |
这些组件为数据、计算和安全带来了运营和治理开销,并且它们往往各自为政,形成孤岛。
为什么选择 Lakehouse 架构?
问题
你可能会想 我们为什么要讨论 lakehouse 架构。它解决了一个你可能已经遇到的巨大痛点。
我们都经历过的传统混乱
场景 1 – 数据湖方式
- 将所有数据倾倒到 S3(廉价存储 ✅)
- 需要进行分析…
- 性能糟糕 ❌
- 没有 ACID 事务 ❌
- 数据质量强制?祝你好运! ❌
结果: 将数据复制到 Redshift 进行实际分析。
场景 2 – 数据仓库方式
- 将所有数据加载到 Redshift(性能优秀 ✅)
- 存储成本飙升 💸
- 不能很好地处理半结构化数据 ❌
- 机器学习团队仍然需要 S3 中的原始数据 ❌
结果: 同时维护 S3 和 Redshift,产生数据重复。
真正的问题
| 问题 | 影响 |
|---|---|
| 数据重复 | 为相同的数据付费多次 |
| 复杂的 ETL 流程 | 在系统之间搬迁数据 |
| 多种权限模型 | 跨服务管理安全 |
| 数据不一致 | 信任问题 |
| 洞察速度慢 | 额外的延迟 |
| 高运营成本 | 基础设施重复 |
听起来很熟悉吗?这正是 SageMaker Unified Studio 提供统一平台来实现 lakehouse 架构 的原因。
解决方案:Lakehouse 架构
Lakehouse 架构 将两者的优势结合在一起:
Data Lake + Data Warehouse = Lakehouse
“Data lakehouse 是一种架构,它将数据湖的可扩展性和成本效益与数据仓库的性能和可靠性特征统一起来。这种方法消除了在存储多样化数据类型和保持分析工作负载查询性能之间的传统权衡。” — AWS 文档
关键优势
- ✅ 事务一致性 – ACID 合规,确保可靠的并发操作
- ✅ 模式管理 – 灵活的模式演进,不会破坏已有查询
- ✅ 计算‑存储分离 – 处理和存储资源可独立扩展
- ✅ 开放标准 – 与 Apache Iceberg 表格式兼容
- ✅ 单一真相来源 – 消除数据孤岛和冗余存储成本
- ✅ 实时与批处理 – 支持流式和历史分析
- ✅ 直接文件访问 – 同时支持 SQL 查询和编程式数据访问
- ✅ 统一治理 – 在所有数据类型上实现一致的安全与合规
这种架构方法正是 SageMaker Unified Studio 帮助您实现的,而无需通常的复杂性。
Source: …
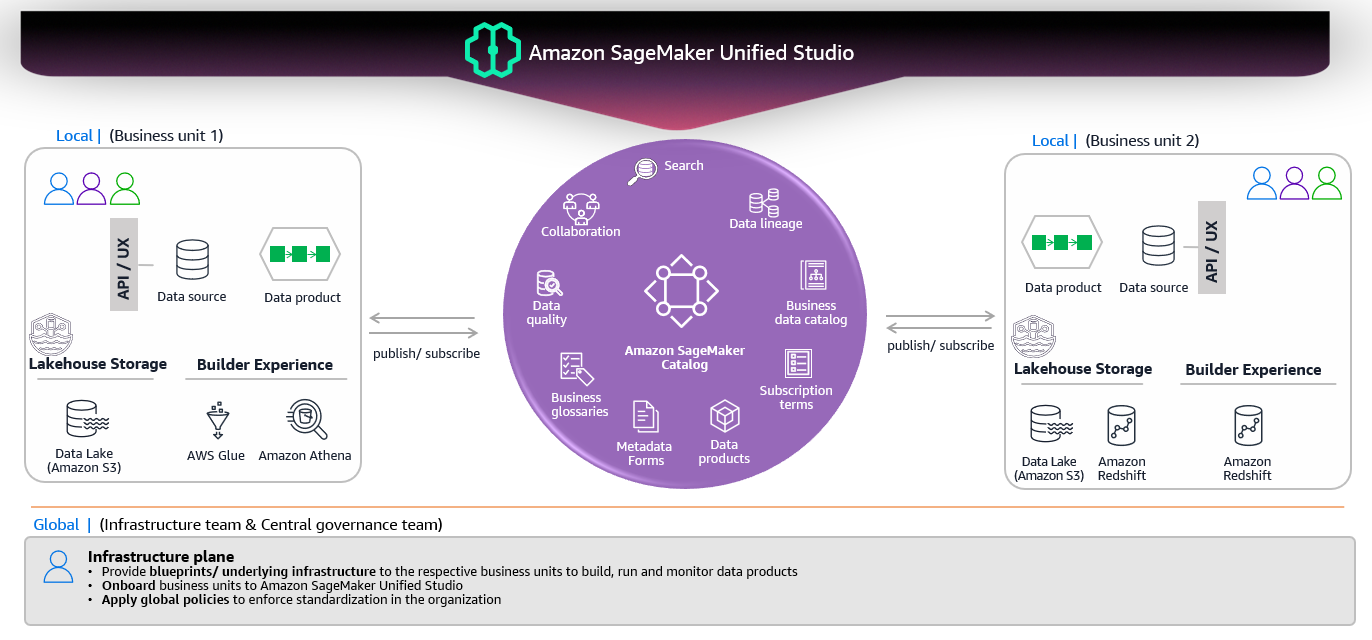
SageMaker Unified Studio 如何实现湖仓(Lakehouse)
根据 AWS 文档:
“Amazon SageMaker 的湖仓架构统一了 Amazon S3 数据湖和 Amazon Redshift 数据仓库中的数据,使您能够在同一个位置处理数据。”
1. 通过单一目录实现统一数据访问
不必为 S3、Redshift、Aurora、DynamoDB 等分别维护连接,您只需使用 一个统一的接口:
- AWS Glue Data Catalog – 用于发现和查询所有数据的单一目录。
- Apache Iceberg – 开放表格式,提供跨分析引擎的互操作性。
- 多个查询引擎(Athena、Redshift、EMR 上的 Spark)均可访问同一份数据,无需复制。
工作原理:
“当您运行查询时,AWS Lake Formation 会检查您的权限,而查询引擎则直接从原始存储位置(无论是 Amazon S3 还是 Amazon Redshift)读取数据。”
结果: 数据保持原位——没有不必要的移动或复制。
2. 两类数据访问
| 类型 | 描述 |
|---|---|
| 受管数据源 | • Amazon S3 数据湖 – 包括内置 Apache Iceberg 支持的 S3 表。 • Amazon Redshift – 直接查询 Redshift 表。 |
| 外部数据源 | • Amazon Aurora、DynamoDB、RDS 等 – 通过联邦查询或连接器访问,仍受 Lake Formation 管理。 |
受管和外部数据源均受 单一权限模型(Lake Formation)治理,简化了安全性和合规性。
3. 计算‑存储分离
- 存储 – 保持在 S3(或 Redshift)中,永不复制。
- 计算 – 您可以按需启动 Athena、EMR Spark、Redshift Serverless 或 SageMaker Processing 作业,实现与存储独立的弹性扩展。
4. 统一治理
- Lake Formation 在所有数据上执行细粒度访问控制,无论数据位于何处。
- DataZone 提供业务层面的目录和项目级权限,确保合适的团队看到合适的数据。
5. 端到端工作流(简化版)
- 摄取 原始数据到 S3(或流式写入 Delta/Iceberg 表)。
- 注册 表到 Glue Data Catalog(自动获取 Iceberg 元数据)。
- 设置 Lake Formation 权限,针对用户、组或角色。
- 查询 通过 Athena、Redshift 或 Spark——无需 ETL 移动数据。
- 消费 结果于 SageMaker 笔记本、SageMaker Studio 或下游机器学习流水线。
Source: …
要点
- SageMaker Unified Studio 消除了传统上迫使你维护独立数据湖和数据仓库的壁垒。
- 通过利用 Lake Formation、Glue Data Catalog 和 Apache Iceberg,SUS 为你提供了真正的 lakehouse——单一真相来源、符合 ACID 标准并统一治理。
- 其结果是 降低成本、简化运维、加快洞察速度,以及在所有分析工作负载中实现 一致的安全性。
其他功能
- Redshift 仓库表 – 通过 Redshift Spectrum 以 Iceberg 表的形式访问
- Zero‑ETL 目标 – 从以下来源进行近实时数据复制:
- SaaS 源(Salesforce、SAP、Zendesk)
- 运营数据库(Amazon Aurora、Amazon RDS for MySQL)
- NoSQL 数据库(Amazon DynamoDB)
联邦数据源(在原地查询,无需移动数据)
- 运营数据库(PostgreSQL、MySQL、Microsoft SQL Server)
- AWS 托管数据库(Amazon Aurora、Amazon RDS、Amazon DynamoDB、Amazon DocumentDB)
- 第三方数据仓库(Snowflake、Google BigQuery)
在 SUS 中连接联邦源时,AWS 会自动配置所需的基础设施组件(AWS Glue 连接、Lambda 函数),这些组件充当查询引擎与联邦数据源之间的桥梁。
使用 Lake Formation 实现集中治理
单一权限模型(AWS Lake Formation),在以下所有资源上统一执行访问控制:
- S3 数据湖
- Redshift 数据仓库
- 联邦源
- 所有查询引擎(Athena、Redshift Query Editor v2、EMR、Glue)
细粒度控制 可在表、列、行和单元格层面进行——一次定义,处处生效。
使用 DataZone 实现基于项目的组织
Amazon DataZone 为 SUS 提供项目和域的管理功能:
- 业务目录 – 数据发现与数据产品发布
- 项目边界 – 协作与权限管理
- 跨域数据共享 – 在团队之间实现受治理的数据访问
- 域管理 – 组织多个项目
架构组件
| 组件 | 描述 |
|---|---|
| Lakehouse Architecture | 架构模式/方法(不是产品) |
| SageMaker Unified Studio | 实现湖仓架构的统一平台 |
| Athena, Redshift, Spark (EMR) | 处理查询的查询/计算引擎 |
| Glue Data Catalog | 统一元数据目录(元数据的单一真相来源) |
| Lake Formation | 提供细粒度权限的治理层 |
| DataZone | 业务目录和项目管理层 |
| Apache Iceberg | 开放表格式,实现跨引擎互操作性 |
既然您已经了解 SUS 如何实现湖仓架构,接下来让我们看看它是如何组织您的工作流的。
Source: …
SUS 的三个核心部分
随着湖仓架构提供统一的数据访问,SUS 将您的工作流组织为三个直观的部分:
A. 发现
您进行数据探索的起点:
- Data Catalog(由 AWS Glue Data Catalog 提供)——发现湖泊、仓库和联邦源中所有可用数据
- Business Catalog(由 DataZone 提供)——查找已发布的数据产品和跨域共享的数据集
- Bedrock Playground——实验生成式 AI 模型和提示
这里是您探索所有来源中可用数据的地方——所有数据通过单一目录统一。
B. 构建
行动发生的地方。SUS 提供对多种分析和机器学习工具的访问:
查询编辑器
- Amazon Athena Query Editor——在 S3 和联邦源上进行无服务器 SQL 查询
- Amazon Redshift Query Editor v2——对仓库数据进行高性能查询
笔记本与开发
- JupyterLab Notebooks——数据科学、机器学习开发以及编程式数据访问
- SageMaker Training——构建和训练机器学习模型
- SageMaker Inference——部署模型
数据处理
- AWS Glue Visual ETL——无代码/低代码数据转换
- Amazon EMR——使用 Apache Spark 进行大数据处理
编排
- Amazon MWAA (Airflow)——工作流编排与调度
AI 助手
- Amazon Q Developer——AI 辅助的 SQL 与 Python 代码生成
所有这些工具都通过不同的查询引擎无缝访问您的统一数据,无需数据移动。
C. 治理
使您策划的有价值数据可供其他消费者使用:
- 将数据产品发布到 Business Catalog
- 跨项目和域共享数据集
- 通过 Lake Formation 一致地强制执行权限
- 跟踪数据血缘和使用情况
- 管理数据质量和合规性
Lake Formation 确保在所有访问模式和查询引擎中保持一致的权限,而 DataZone 管理业务元数据和共享工作流。
理解架构

不同的 绿色框 代表 SageMaker Unified Studio 的概念以及它们之间的相互连接:
| 来源 | 目标 | 关系 | 基数 | 含义 |
|---|---|---|---|---|
| Domain | Domain units | 包含 | 1 : M | 组织结构 |
| Domain | Projects | 由…组成 | 1 : M | 项目属于某个域 |
| Projects | Users | 包含成员 | M : M | 用户在项目中工作 |
| Projects | Data | 封装 | 1 : M | 项目访问数据源 |
| Users | Assets | 通过…治理数据 | M : M | 用户创建/管理资产 |
| Data | Assets | 发布到 | M : M | 数据被整理为资产 |
这些绿色框共同构成了由 DataZone 驱动的组织框架,提供:
- ✅ 结构 – Domain、Domain units
- ✅ 协作 – Projects、Users
- ✅ 数据管理 – Data、Assets
- ✅ 治理 – 权限贯穿所有六个要素
这就是在 SageMaker Unified Studio 中实现湖仓架构的基础!
摘要
SUS 提供实现湖仓架构的平台层,统一目录位于中心,多个查询引擎可访问来自湖泊、数据仓库和联邦来源的数据——所有这些都通过 Lake Formation 统一治理,并通过 DataZone 进行组织。
🚀 动手尝试
想要亲身体验吗?AWS 提供了一个实用的研讨会,涵盖了本文讨论的所有内容:
👉 SageMaker Unified Studio Workshop
本研讨会从不同数据专业人员的视角模拟真实业务场景,帮助他们解决实际业务挑战。您将完整演练从初始数据分析到部署基于生成式 AI 的、定制化学生参与解决方案的全流程。
阅读研讨会并参照截图,了解 SUS 以及研讨会的实现方式。
## 💬 欢迎反馈
**您觉得如何?**
- ✅ 有帮助的部分吗?
- 🤔 有困惑的地方吗?
- 💡 下篇想讨论的主题?
**您尝试过 SageMaker Unified Studio 吗?** 在评论中分享您的体验!