限流:概念、算法与分布式挑战
Source: Dev.to
请提供您希望翻译的正文内容,我将为您翻译成简体中文并保留原有的格式、Markdown 语法以及技术术语。谢谢!
介绍
如果你曾经构建过 API 或后端服务,你可能已经遇到过以下问题:
- 某个用户发送了过多请求
- 机器人滥用你的接口
- 流量突增导致服务崩溃
- 重试或定时任务意外地给系统带来过载
本文讨论的是 速率限制(rate limiting),这是一种简单却关键的技术,用于保护系统免受上述问题的影响。
在本篇文章中,我们将:
- 了解为何需要速率限制
- 学习常见的速率限制算法是如何工作的
- 看看速率限制在实际系统中的定位
你不需要事先了解速率限制的相关知识。如果你了解基本的 API 和请求,就能跟上本文的内容。
目录
Source: …
限流要解决的问题
当请求到达服务器时,它会消耗 CPU 时间、内存、数据库连接和网络带宽等资源。正常使用时这没问题,但当 大量请求同时到达 时,问题就会出现。
常见原因
- 单个用户在紧密循环中发送请求
- 机器人访问公开接口
- 没有适当退避的重试机制
- 发布或推广后流量突增
服务器把所有请求视为相同,它不知道哪个请求重要,哪个请求有害。
为什么会成为严重问题
如果请求量不断增长且没有限制:
- 响应时间上升
- 数据库开始变慢
- 超时增多
- 错误率激增
- 最终服务对所有人不可用
为什么不能仅仅“扩容服务器”
我们的常见反应是 “再加几台服务器”。扩容有帮助,但 并不能解决根本问题:
- 无限的请求最终会压垮任何系统
- 扩容会增加成本
- 数据库和第三方 API 可能无法同等扩容
如果一直只扩容,只是 延迟 失败的到来。
系统真正需要的
- 一种控制请求速率的方式
- 防止意外或恶意滥用的保护
- 公平性,防止单个用户抢占资源导致其他用户被饿死
这正是 限流(rate limiting) 所要解决的问题。
实际上速率限制的作用
从本质上讲,速率限制控制 在给定时间段内允许执行操作的频率。最常见的这种操作是 API 请求。
速率限制通常表现为:
- 每位用户每分钟允许 100 次请求
- 每个 IP 每秒允许 10 次请求
- 对敏感端点每秒允许 1 次请求
当达到限制时,系统 不会 处理进一步的请求,直至足够的时间过去。
超出限制时会发生什么
- 请求被拒绝
- 服务器立即响应
- 为其他用户保留资源
在基于 HTTP 的系统中,这通常以 429 Too Many Requests 响应返回。提前拒绝可以避免不必要的工作,如数据库查询或外部 API 调用。
速率限制能够保证的内容
- 公平使用 – 单个用户不能消耗本该供所有人共享的资源
- 可预测的性能 – 即使在负载下系统仍保持响应
- 受控的突发 – 某些算法允许短时间的突发,同时强制长期限制
- 系统保护 – 及早遏制意外的错误或行为异常的客户端
速率限制 不 能做到的事情
- 认证(它不验证用户身份)
- 完整的安全解决方案
- 替代适当的输入验证
它是一种 流量控制机制,而不是安全闸门。
常见限流算法
不同系统根据需求使用不同的限流算法。没有一种算法是普遍“最佳”的;每种算法在简洁性、准确性和灵活性之间都有不同的取舍。
固定窗口计数器
最简单的限流形式。
工作原理
- 将时间划分为固定窗口(例如 1 分钟、1 小时)。
- 对每个用户,系统为 当前窗口 保持一个计数器。
- 每个进入的请求都会使该计数器递增。
- 当计数器达到上限时,后续请求被拒绝。
- 窗口结束时,计数器重置为零。
示例
- 上限: 每分钟 5 次请求
- 窗口: 12:00 – 12:01
用户在 12:00:59 发送 5 次请求 → 全部被允许。
计数器在 12:01:00 重置 → 再发送 5 次请求也被允许。
这意味着用户实际上在 1 秒内发出了 10 次请求。


为什么固定窗口会失效
- 用户可以利用窗口边界进行攻击。
- 流量会变得非常突发。
- 后端服务可能突然收到巨大的流量峰值。
- 系统在高负载下会变得不公平。
固定窗口何时可以接受
- 极低流量的系统。
- 内部工具。
- 原型或演示。
- 正确性不如简洁性重要的场景。
在大多数生产环境的 API 中,通常会避免使用固定窗口。
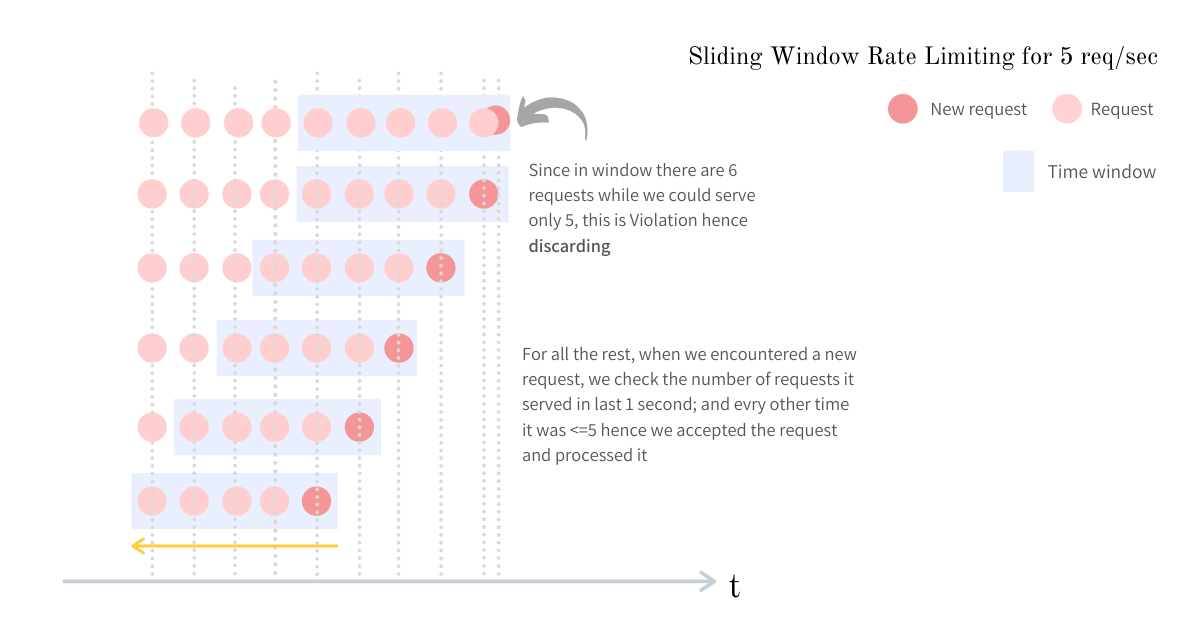
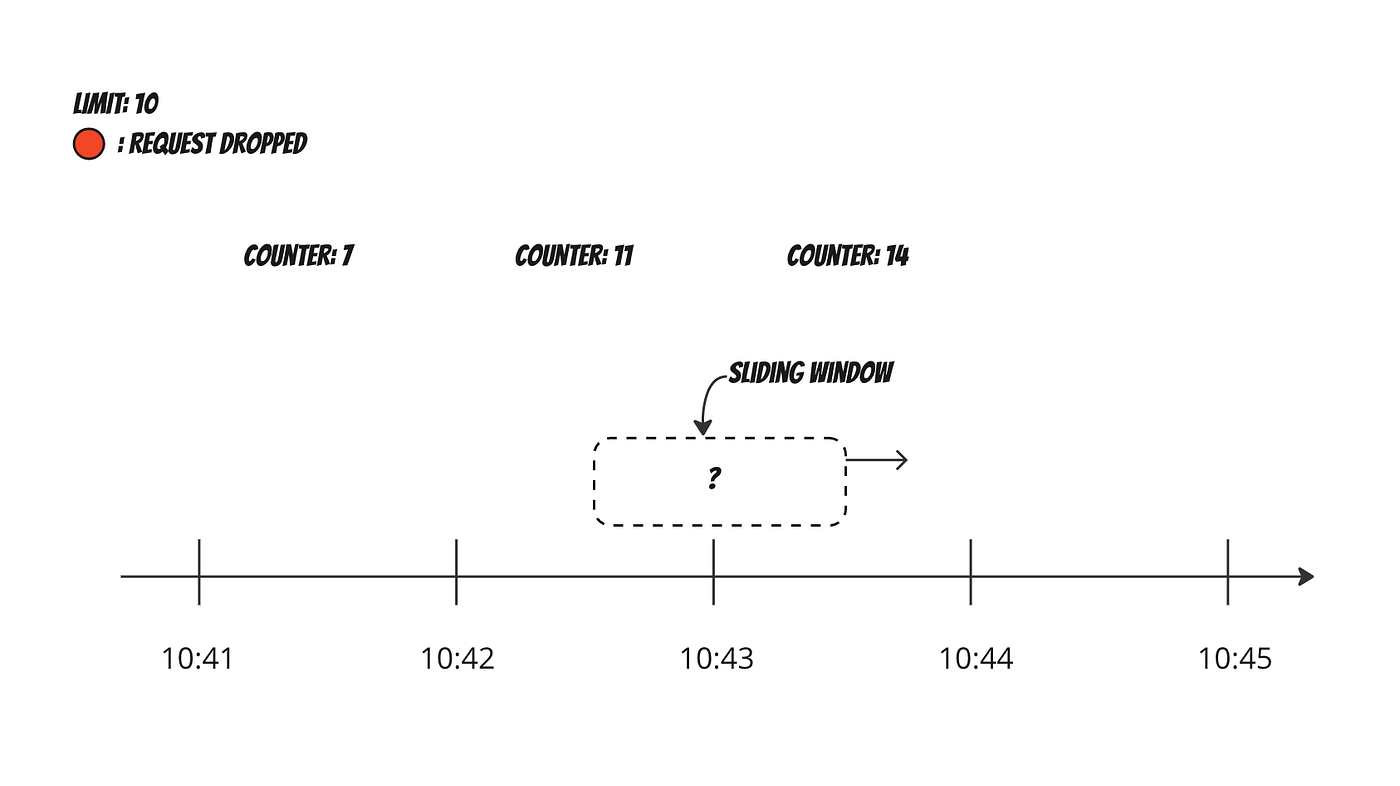
滑动窗口
滑动窗口算法通过查看 当前时间往前的 N 秒 来解决固定窗口的突发问题。
工作原理
- 系统始终查看当前时间往前的
N秒。 - 每个请求都在这个滚动窗口内进行评估。
- 系统统计过去
N秒内发生了多少请求。 - 如果计数超过上限,请求被拒绝。
示例
Limit: 100 requests per 60 seconds- 在任意时刻,系统检查过去 60 秒内有多少请求。
- 这可以防止因窗口重置而导致的突发流量,因为请求会更均匀地分布在时间轴上。
优点
- 请求分配更公平。
- 流量峰值自然得到抑制。
- 没有窗口边界的突发问题。
缺点
- 系统需要存储请求的时间戳。
- 随着流量增加,内存使用会提升。
- 每个请求的计算量更大。
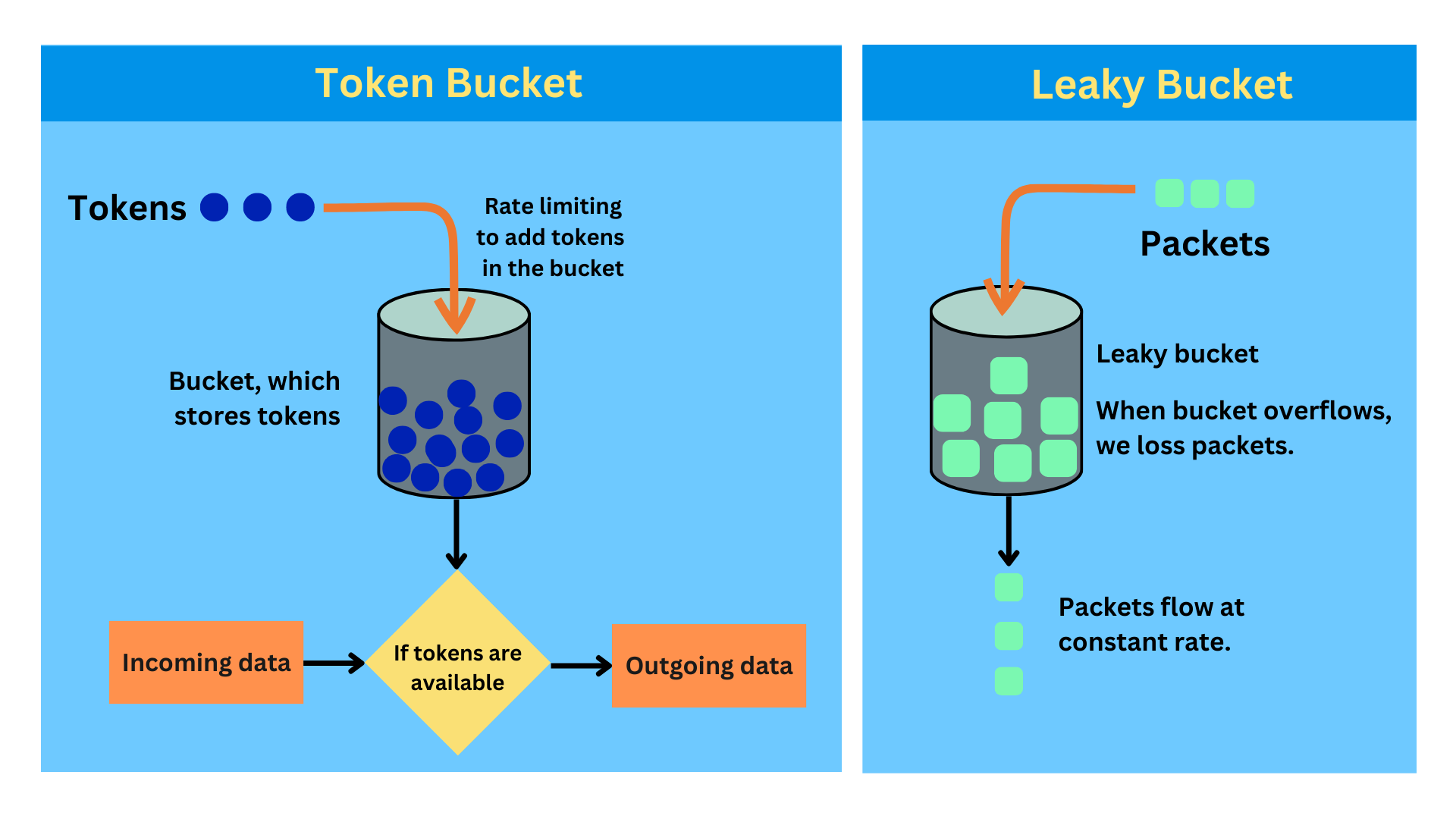
令牌桶
在生产环境中最常用的算法之一,因为它在严格限制和良好用户体验之间取得了平衡。
工作原理
- 每个用户都有一个装有令牌的桶。
- 令牌以固定速率加入桶中。
- 每个请求消耗一个令牌。
- 如果没有令牌可用,请求被拒绝。
- 桶有最大容量,令牌数量不会无限增长。
示例
Bucket size: 10 tokens
Refill rate: 1 token per second| 场景 | 结果 |
|---|---|
| 用户空闲 → 桶填满至 10 个令牌 | 可进行一次突发请求 |
| 用户瞬间发送 10 次请求 | 全部被允许 |
| 第 11 次请求 | 被拒绝 |
| 1 秒后,加入 1 个令牌 | 允许 1 次请求 |
Source: ds.s3.amazonaws.com/uploads/articles/umlnz48uisqgwkyl5e9o.jpg)
为什么它表现良好
- 允许短时间的突发请求而不会破坏系统。
- 强制执行长期的速率限制。
- 提供更好的用户体验。
- 实现简单且高效。
正因为这些特性,Token Bucket 通常是 API 的 默认选择。
漏桶(Leaky Bucket)
侧重于产生 平滑且稳定的输出速率。
工作原理
- 进入的请求被放入队列(即桶)中。
- 请求以恒定、固定的速率从队列中离开。
- 如果队列已满,新的请求将被丢弃。
示例
- 大量请求一次性到达。
- 系统以稳定的速度处理请求。
- 当队列满时,多余的请求被丢弃。
优点
- 能很好地保护下游系统。
- 确保可预测的处理速度。
- 防止突发流量冲击。
对面向用户的 API 的缺点
- 突发请求会被延迟或丢弃。
- 负载下延迟会增加。
- 用户体验可能受影响。
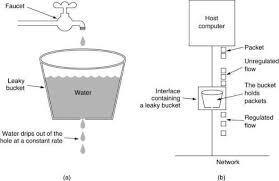
漏桶更适合用于后台任务和流水线,而不是交互式 API。
Comparing the Algorithms
The goal here is to understand which algorithm fits which situation.
High‑level Comparison
| Algorithm | Burst handling | Fairness | Complexity | Common usage |
|---|---|---|---|---|
| Fixed Window | 差 | 低 | 非常低 | 简单或低流量系统 |
| Sliding Window | 好 | 高 | 高 | 需要精确的系统 |
| Token Bucket | 优秀 | 高 | 中等 | 大多数公共 API 的默认选择 |
| Leaky Bucket | 优秀(输出) | 中等 | 中等 | 后台任务、流水线 |
Rate‑Limiting Algorithms Overview
| Algorithm | Accuracy | Burst Capacity | Complexity | Typical Use‑case |
|---|---|---|---|---|
| Token Bucket | 非常好 | 高 | 中等 | 大多数 API |
| Leaky Bucket | 差 | 中等 | 中等 | 后台任务 |
选择最符合你的流量模式、公平性要求和运营约束的算法。
分布式系统中的挑战
到目前为止,我们讨论的所有内容都假设只有一台服务器。在实际应用中,情况很少是这样——大多数系统都在 多台服务器 上运行,并通过负载均衡器进行调度。这会带来若干重要的挑战。