Apple 支持的全新 AI 模型可从无声视频中生成声音和语音
Source: 9to5Mac

VSSFlow – 统一音频生成模型
新模型 VSSFlow 采用新颖的架构,在单一统一系统中同时生成声音 和 语音,提供最先进的效果。
观看(并聆听)以下演示。
演示链接请放在此处(请将占位符替换为实际的视频 URL。)
问题
大多数视频转声音模型(即从无声视频生成音频的模型)难以产生逼真的语音。相反,大多数文本转语音系统因为设计目标不同,无法生成非语音声音。
以往统一这些任务的尝试通常假设联合训练会降低性能。因此,它们采用多阶段流水线,分别教授语音和声音,增加了不必要的复杂性。
研究人员的做法
三位 Apple 研究员联合中国人民大学的六位合作伙伴,推出了 VSSFlow——一个能够从无声视频生成音效 和 语音的单一 AI 模型。
架构的关键点:
- 联合训练:语音和声音的训练相互强化,而不是相互干扰。
- 统一流水线:消除对独立阶段的需求,简化工作流程。
- 双向收益:语音生成的提升会促进音效生成,反之亦然。
Source: …
解决方案
VSSFlow 利用多种生成式 AI 概念:
- 音素级标记化 – 将转录文本转换为音素标记序列。
- 流匹配 – 模型学习从噪声中重建声音,即它被训练为从随机噪声开始,最终得到期望的音频信号。(详细解释请参见此处。)
这些思路在 10 层架构 中结合,将视频和转录信息直接融合到音频生成管道中。最终得到一个能够同时生成音效和语音的单一系统。
关键洞见: 对语音和环境声音进行联合训练 提升了两项任务的性能,而不是相互竞争。
训练数据
| 数据集 | 内容 |
|---|---|
| V2S | 配有环境声音的静音视频 |
| VisualTTS | 配有转录文本的静音说话视频 |
| TTS | 标准文本转语音数据 |
模型在上述混合数据上端到端训练,学习同时生成音效 和 口语对白。
同时输出的微调
最初,VSSFlow 无法在单个输出中同时产生背景音 和 口语对白。为了解决这个问题,作者在大量 合成示例 上对预训练模型进行微调,这些示例将语音和环境声音混合在一起(合成数据管道请参见此处。)。该微调让模型学习两种模态的联合声学特性。
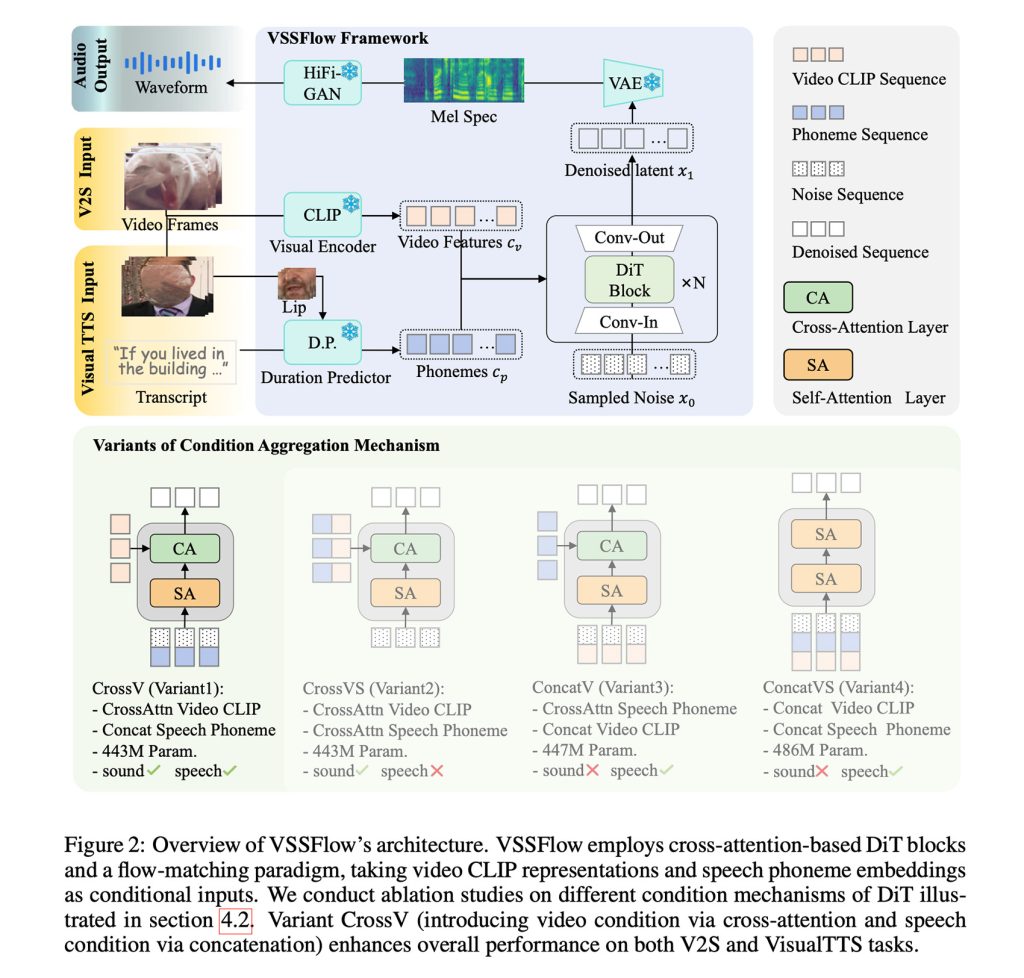
图:VSSFlow 架构
使用 VSSFlow
为了从无声视频中生成音效和语音,VSSFlow 从随机噪声开始,并利用以 10 fps 采样的视频视觉线索来塑造环境声音。同时,所说内容的文字稿为生成的语音提供了精确的指导。
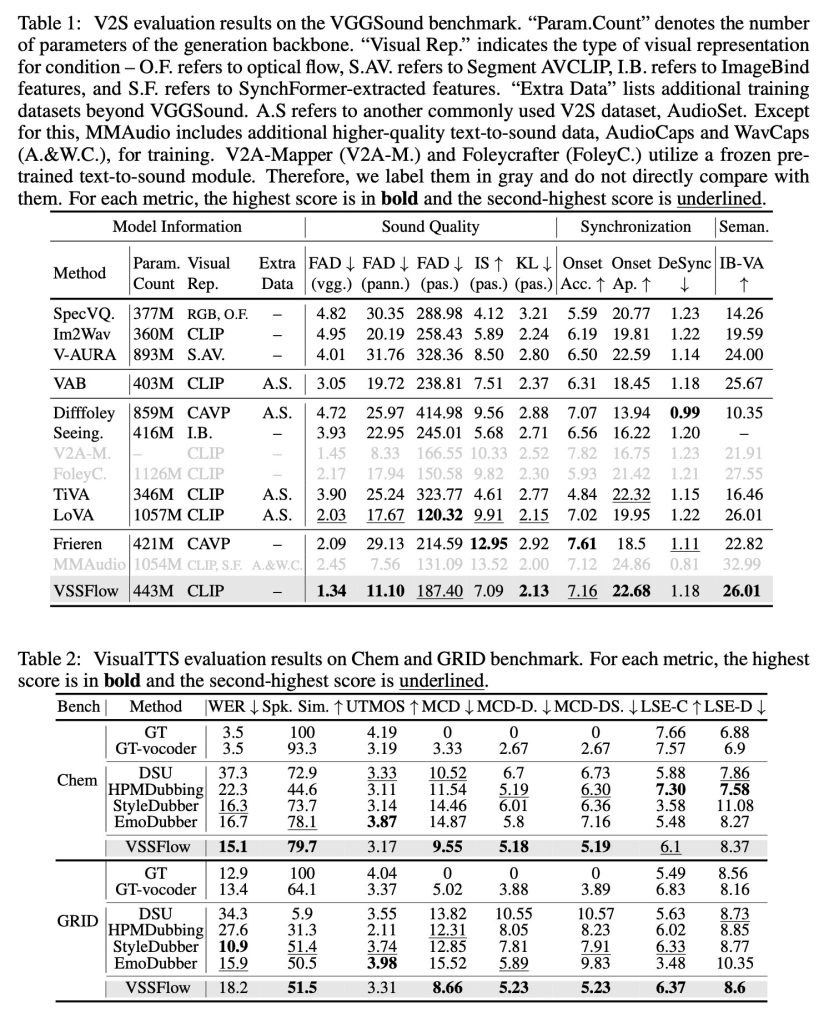
在与仅针对音效或仅针对语音构建的任务特定模型进行对比测试时,VSSFlow 在两项任务上均取得了竞争性的结果,尽管使用的是单一统一系统,但在多个关键指标上仍领先。
研究人员发布了多个关于音效、语音以及联合生成(来自 Veo3 视频)的演示,以及 VSSFlow 与若干替代模型的对比。您可以在下方观看部分结果,但务必前往 演示页面 查看全部内容。
注意: 研究人员已在 GitHub 上 开源 VSSFlow 的代码(github.com/vasflow1/vssflow),并正在努力发布模型权重及推理演示。
未来方向(作者原话)
“本工作提出了一种统一的流模型,整合了视频到声音 (V2S) 与视觉文本到语音 (VisualTTS) 任务,建立了视频条件化声音与语音生成的新范式。我们的框架展示了一种有效的条件聚合机制,将语音和视频条件引入 DiT 架构。此外,我们通过分析揭示了声音‑语音联合学习的相互促进效应,凸显了统一生成模型的价值。
对于未来研究,有几个方向值得进一步探索。首先,高质量视频‑语音‑声音数据的稀缺限制了统一生成模型的发展。此外,开发更好的声音和语音表示方法——既能保留语音细节又保持紧凑——是一个关键挑战。”
欲了解更多关于题为 “VSSFlow: Unifying Video‑conditioned Sound and Speech Generation via Joint Learning” 的研究,请 点击此链接。
亚马逊配件特惠
![]()
![]()
FTC:我们使用可产生收入的自动联盟链接。 了解更多