大多数停机是可预防的:为什么你的系统需要立即实现 Self-Healing
发布: (2025年12月3日 GMT+8 02:00)
4 分钟阅读
原文: Dev.to
Source: Dev.to
引言
自愈系统是指在出现问题时能够自动修复自身的计算机系统。它们不需要等到人为发现问题并手动干预(“被动灭火”),而是 主动 的。系统会持续监控自身,以捕捉细微的故障或性能下降迹象(轻微的性能下降或早期错误)。一旦检测到问题,它们会自动采取措施进行纠正——重启故障组件、回滚有问题的更新,或隔离出现异常的系统部分。
为什么自愈很重要?
- 在用户感知之前防止宕机 – 系统检测到退化(延迟、内存激增、健康检查失败)并在影响客户之前自行修复。
- 消除值班疲劳 – 让运维团队摆脱凌晨 3 点的 “重启 pod” 或 “扩容” 紧急演练。
- 提升可靠性与 SLO 合规性 – 自动纠正保持高可用性,无需等待人工介入。
- 稳定微服务生态 – 在分布式系统中,故障会级联;自愈能够阻止连锁反应。
- 更快的恢复 = 更好的用户体验 – 自动回滚 / 重启 / 重同步比人工调试更迅速。
自愈系统涉及的关键工具
健康检测(识别“伤口”)
系统如何知道出现了问题。
纠正 / 治愈
一旦识别出伤口,纠正机制即启动。
自愈步骤
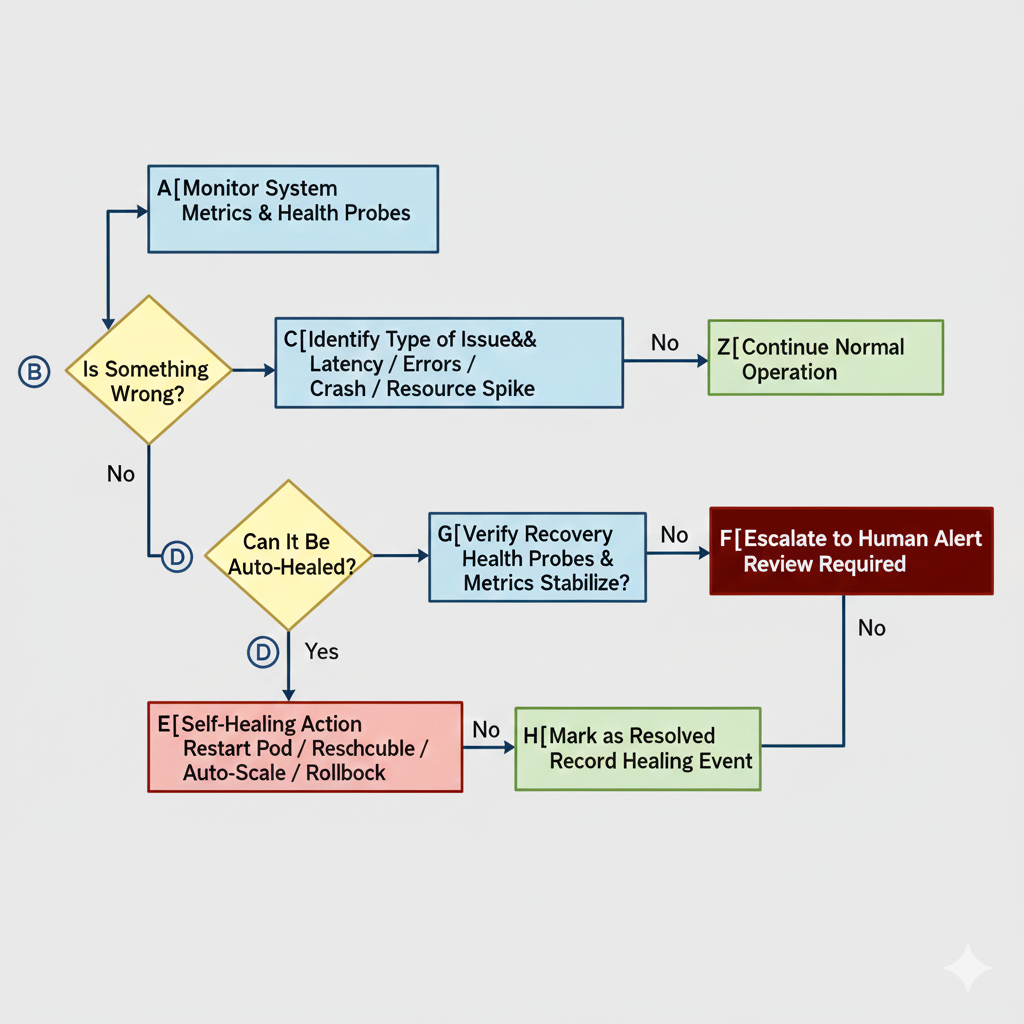
自愈期间及之后应做的事
为确保系统稳定,工程团队必须把自愈事件视为信号,而非噪音。
4.1 记录治愈事件
- 时间戳
- Pod/容器 ID
- 故障原因
- 指标快照
- 执行的治愈操作
- 成功/失败状态
这些信息日后进行根因分析(RCA)时价值巨大。
4.2 分析模式趋势
关注以下情况:
- Pod 频繁重启
- 内存或 CPU 使用的异常模式
- 部署后出现的延迟突发
- 自动扩容后持续出现的问题
- 节点特定的故障
4.3 持续进行根因分析
自愈只能解决表面症状。我们仍需根除根本原因:
- 内存泄漏
- 死锁
- 有缺陷的部署
- 基础设施故障
- 配置错误
- 资源匮乏
4.4 仅在必要时提醒人工
健康的模式:
- 每天 1–2 次自愈 → 正常
- 短时间内出现 3 次 → 触发告警
- 持续重启 → 严重告警
4.5 防止再次发生
自动化永久性修复:
- 添加限流 / 速率限制
- 添加带抖动的重试机制
- 添加熔断器
- 改进自动扩容阈值
- 强制资源限制
- 改进部署验证
- 应用 Helm 回滚策略
总结
自愈不仅仅是 “自动重启”。它是一个完整的生态系统:
检测 → 诊断 → 治愈 → 验证 → 学习 → 永久修复
Jai Chinjo!