掌握 Serverless 数据管道:AWS Step Functions 2026 年最佳实践
Source: Dev.to
AWS Step Functions – 生产级无服务器数据管道
AWS Step Functions 已从一个简单的状态机编排器演变为现代无服务器数据工程的核心支柱。随着组织从脆弱的单体脚本转向事件驱动架构,Step Functions 为复杂的 ETL(抽取、转换、加载)流程和数据工作流提供了所需的可靠性、可观测性和可扩展性。
然而,构建一个 “可运行” 的管道与构建一个 “生产级” 的管道是不同的。在本指南中,我们将探讨业界标准的最佳实践,帮助构建健壮的无服务器数据管道,重点关注性能、成本效率和可维护性。
1️⃣ 选择正确的工作流类型:Standard vs. Express
在构建数据管道时,首要且最关键的决定是选择合适的工作流类型。选择错误可能导致巨额不必要的成本,或无法跟踪长期运行的流程。
对比
| 特性 | Standard Workflows | Express Workflows |
|---|---|---|
| 最大持续时间 | 最长 1 年 | 最长 5 分钟 |
| 执行模型 | Exactly‑once(一次性执行) | At‑least‑once(至少一次执行) |
| 定价 | 每次状态转换(≈ $25 每 百万次) | 按持续时间和内存使用计费 |
| 使用场景 | 长时间运行的 ETL、人工参与 | 大规模 IoT 数据摄取、流处理 |
最佳实践
- Standard Workflows – 用于高价值、长时间运行的数据作业,审计性和一次性执行至关重要。
- Express Workflows – 用于高频、短暂任务(例如处理单个 SQS 消息或 API 转换),以节省成本。
2️⃣ 实现 “Claim Check” 模式以处理大负载
Step Functions 对在状态之间传递的输入和输出负载施加 256 KB 的限制。在数据管道中,如果直接传递原始数据片段或大型数组,JSON 元数据很容易超过此限制。
❌ 不良实践 – 直接传递原始数据
将大型 Base64 编码字符串或庞大的 JSON 数组直接放入状态输出,最终会导致执行因 States.DataLimitExceeded 错误而失败。
✅ 良好实践 – 使用 S3 指针
将数据写入 S3 存储桶,并在状态之间传递 S3 URI(指针)。这就是经典的 Claim Check 模式。
示例(ASL 定义)
// BAD: Passing raw data results in a failure
{
"StartAt": "ProcessData",
"States": {
"ProcessData": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ProcessBigData",
"End": true
}
}
}// GOOD: Passing an S3 reference
{
"StartAt": "ProcessData",
"States": {
"ProcessData": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ProcessBigData",
"Parameters": {
"s3Bucket": "my-data-pipeline-bucket",
"s3Key": "input/raw_file.json"
},
"ResultPath": "$.s3OutputPointer",
"End": true
}
}
}重要性说明: 管道只处理元数据,而不处理实际数据,因此即使数据量增长 100 倍,系统仍能保持稳定。
3️⃣ 高级错误处理与重试
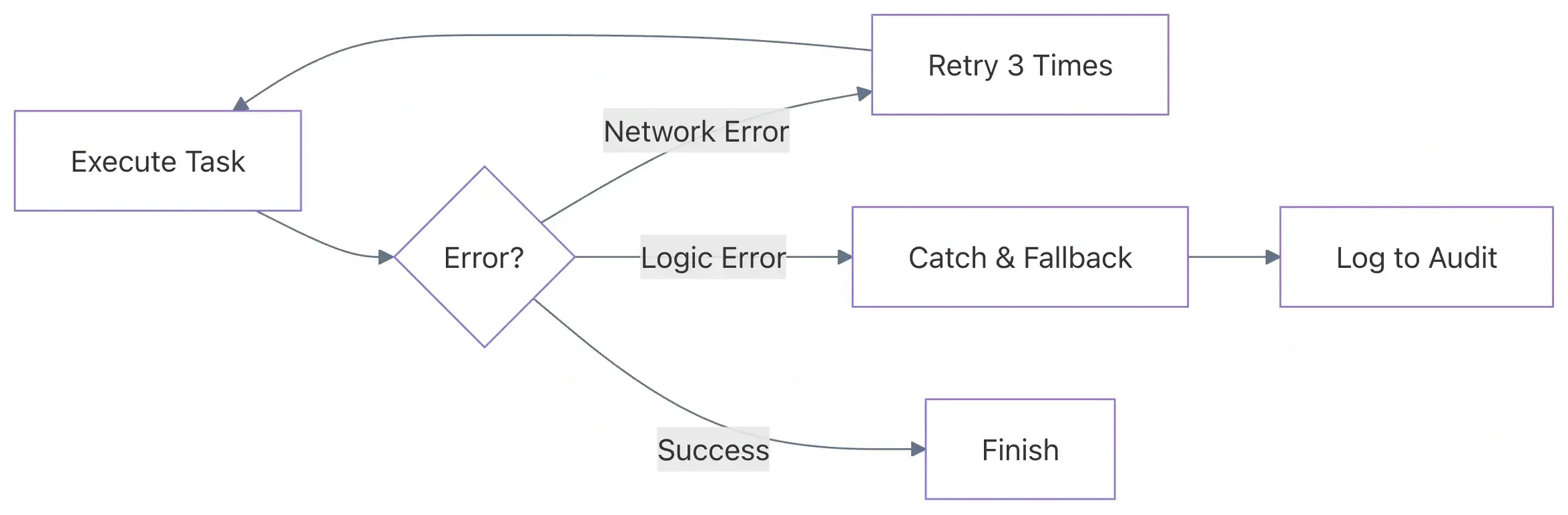
瞬态错误(网络超时、服务限流、Lambda 冷启动)在分布式系统中是不可避免的。一个健壮的数据管道应该具备自我修复能力。
❌ 陷阱 – 通用捕获
对所有错误使用单一的 Catch 块——或者更糟的是根本不使用重试——会导致需要人工干预并可能产生数据丢失。
✅ 最佳实践 – 针对性重试并使用指数退避
为不同类型的错误配置有针对性的重试策略。例如,AWS 服务限流应与自定义业务逻辑错误采用不同的处理方式。
好的示例(带抖动的重试)
"Retry": [
{
"ErrorEquals": [
"Lambda.TooManyRequestsException",
"Lambda.ServiceException"
],
"IntervalSeconds": 2,
"MaxAttempts": 5,
"BackoffRate": 2.0,
"JitterStrategy": "FULL"
},
{
"ErrorEquals": ["CustomDataValidationError"],
"MaxAttempts": 0
}
]为什么重要: 指数退避可以防止下游资源(例如 RDS、DynamoDB)出现“惊群”问题。加入抖动可以确保 100 个同时失败的并发执行不会在同一毫秒全部重试。
4️⃣ 利用内置函数减少 Lambda 使用
许多开发者会为字符串拼接、时间戳生成或简单算术等琐碎任务调用 Lambda 函数。每一次 Lambda 调用都会增加延迟和成本。
❌ 不良实践 – “辅助” Lambda
仅仅为了合并两个字符串或检查某个值是否为 null 而调用 Lambda 函数。
✅ 良好实践 – ASL 内置函数
Step Functions 提供了内置函数,能够直接在状态机定义中完成这些任务。
示例:生成唯一 ID
{
"Parameters": {
"TransactionId.$": "States.UUID()",
"Timestamp.$": "States.Format('yyyy-MM-dd\'T\'HH:mm:ss.SSSZ', $$.Execution.StartTime)"
}
}为什么重要: 消除不必要的 Lambda 调用既能降低延迟和成本,又能让工作流定义更简洁、更易维护。
📌 要点
| 区域 | 生产级别建议 |
|---|---|
| 工作流类型 | 为长期运行且可审计的作业选择 Standard;为高频、短暂的任务选择 Express。 |
| 负载大小 | 使用 Claim Check 模式——将大数据存储在 S3 中,仅传递 URI。 |
| 错误处理 | 实施细粒度的 Retry 策略,使用指数退避和抖动;避免捕获所有错误的做法。 |
| Lambda 使用 | 对于简单转换,优先使用 ASL 内置函数。 |
| 成本与性能 | 最小化状态转换,避免不必要的 Lambda 调用,并选择合适的工作流类型。 |
通过应用这些最佳实践,您将构建 可靠、可观测、成本效益高 且 已准备好投入生产 的无服务器数据管道。祝编排愉快!
内置函数示例
{
"Id.$": "States.UUID()",
"Message.$": "States.Format('Processing item {} at {}', $.itemId, States.FormatDateTime(States.Now(), 'yyyy-MM-dd'))"
}常用内置函数
| 函数 | 描述 |
|---|---|
States.Array | 将多个值合并为数组。 |
States.JsonToString | 将 JSON 对象转换为字符串,以用于日志记录或 SQS 消息。 |
States.MathAdd | 执行基本算术运算。 |
States.StringToJson | 将字符串解析回 JSON。 |
为什么重要: 内置函数由 Step Functions 服务执行,无需为每次执行额外付费(除状态转换费用外),且相较于 Lambda 函数的冷启动潜在延迟,执行延迟为零。
Source: …
5. 高性能并行与分布式 Map
对于大规模数据处理任务(例如,在 S3 中处理数百万行 CSV),传统的 Map 状态已不够用。AWS 推出了 Distributed Map,它可以实现最高 10,000 并行执行。
最佳实践:项目批处理
使用 Distributed Map 时,如果记录很小,避免每次执行只处理一条记录。应使用 ItemBatching。
为什么?
如果有 100 万行并逐条处理,你需要为 100 万次状态转换付费。将它们批量为 1 000 条一组后,费用仅为 1 000 次转换。
示例配置
{
"MapState": {
"Type": "Map",
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
}
},
"ItemBatcher": {
"MaxItemsPerBatch": 1000
},
"MaxConcurrency": 1000,
"Iterator": {
// Processing logic here
}
}
}6. 安全性与可观测性
最小权限 IAM 角色
绝不要为状态机使用单一的 “God‑mode” IAM 角色。每个状态机都应拥有唯一的 IAM 角色,并且仅授予其与之交互的资源(特定的 S3 存储桶、特定的 Lambda 函数)的权限。
日志记录和 X‑Ray
为 Step Functions 启用 AWS X‑Ray 跟踪。这可以让你可视化跨多个 AWS 服务的完整请求路径,轻松发现瓶颈。
日志配置最佳实践:
- 在生产环境中将日志级别设置为
ERROR。 - 仅在开发或调试时使用
ALL,因为记录每个状态的输入/输出会在高并发流水线中显著增加 CloudWatch 成本。
摘要表:该做与不该做
| 实践 | 做 | 不做 |
|---|---|---|
| Payloads | 使用 S3 URI 指针来处理大数据。 | 直接传递大型 JSON 对象。 |
| Logic | 使用内置函数(Intrinsic Functions)完成基本任务。 | 为简单的字符串操作触发 Lambda 函数。 |
| Retries | 使用指数退避和抖动。 | 对所有错误使用固定间隔。 |
| Parallelism | 对大型 S3 数据集使用分布式映射(Distributed Map)。 | 对数百万项使用标准映射(Map)。 |
| Costs | 对高吞吐量逻辑使用 Express 工作流。 | 对简单的高频任务使用标准工作流。 |
常见陷阱需避免
- 忽视历史限制: 标准 Step Functions 的历史记录上限为 25 000 条事件。对于运行数千次的循环,请使用 Distributed Map 或 Child Workflows 以避免触及此上限。
- 硬编码资源 ARN: 使用环境变量或 CloudFormation/Terraform 引用将 ARN 注入到你的 ASL 定义中。硬编码会导致无法管理 Dev/Staging/Prod 环境。
- 状态耦合过紧: 避免让状态过度依赖前一个状态的具体 JSON 结构。使用
InputPath、OutputPath和ResultSelector仅映射必要的数据。
结论
AWS Step Functions 是将无服务器数据管道粘合在一起的“胶水”。通过实现模块化、对大负载使用 Claim‑Check 模式以及利用内置函数,您可以构建不仅可扩展且具成本效益且易于调试的管道。
首先优化清晰度和弹性。 一个易于监控且能够自动从故障中恢复的管道,比一个稍快但需要在凌晨 3:00 手动重启的管道更有价值。
您是否在数据管道中使用 Step Functions?如果您发现其他对团队有效的模式,请在评论中告诉我们!