领先的推理提供商通过在 NVIDIA Blackwell 上使用开源模型将 AI 成本降低至最高 10 倍
Source: NVIDIA AI Blog
请提供您希望翻译的具体文本内容,我将为您翻译成简体中文并保持原有的格式、Markdown 语法和技术术语不变。
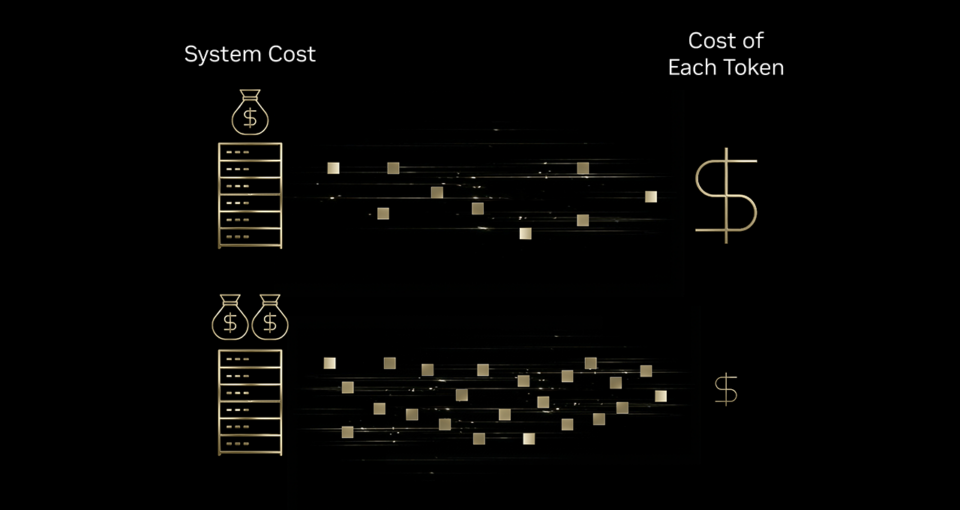
为什么代币成本重要
AI 驱动的交互——从医疗保健中的诊断洞察到游戏中的角色对话,再到自主客服代理——都建立在同一个智能单元上:一个 token。
随着 AI 交互规模的扩大,企业不得不问自己:我们能负担更多的代币吗?
答案在于更好的 代币经济学——即降低每个代币成本的实践。
最近的 MIT 研究 表明,基础设施和算法的进步正以 每年最高 10 倍 的速度降低前沿性能的推理成本。
基础设施效率 = 更佳 Tokenomics
-
如果印刷机能够在墨水、能源和机器成本仅略有增加的情况下,产出 10× 更多的页面,则每页成本会显著下降。
-
同样,对 AI 基础设施的投资能够远超成本增长地提升 token 产出,从而实现 显著降低每个 token 的成本。
谁在领跑?
领先的 inference 提供商已经在利用 NVIDIA Blackwell 平台 大幅降低 token 成本:
- Baseten
- DeepInfra
- Fireworks AI
- Together AI
这些提供商:
- 托管已达到前沿水平智能的先进 open‑source 模型。
- 将 open‑source 智能与 NVIDIA Blackwell 的极致硬件‑软件协同设计相结合。
- 部署自研的优化推理栈。
结果如何?相较于之前的 NVIDIA Hopper 平台,每个 token 的成本降低最高可达 10 倍,为各行各业的企业带来显著的成本节省。
要点
改进代币经济学不仅仅是技术上的微调——它是一个战略杠杆,使公司能够以可负担的方式扩展 AI 交互。通过采用如 NVIDIA Blackwell 这样的前沿基础设施,组织可以提供更丰富、更频繁的 AI 体验,同时保持成本在可控范围内。
医疗保健 – Baseten 与 Sully.ai
将 AI 推理成本降低 10 倍
在医疗领域,繁琐且耗时的任务(如医学编码、文档撰写和保险表单管理)会侵占医生可用于患者的时间。
Sully.ai 通过创建“AI 员工”来自动化医学编码和记录笔记等常规任务,以解决此问题。随着平台的扩展,其专有的闭源模型出现了三个主要瓶颈:
| 瓶颈 | 影响 |
|---|---|
| 不可预测的延迟 | 放慢实时临床工作流 |
| 推理成本上升 | 成本增长快于收入 |
| 模型控制受限 | 无法微调质量或进行更新 |
解决方案
Sully.ai 转而使用 Baseten 的 Model API,在 NVIDIA Blackwell GPU 上部署开源模型(例如 gpt‑oss‑120b)。技术栈包括:
- NVFP4 低精度数据格式,实现高效推理
- NVIDIA TensorRT‑LLM 库,用于优化执行
- NVIDIA Dynamo 推理框架,简化部署
Baseten 在观察到与之前基于 Hopper 的部署相比,Blackwell GPU 在每美元吞吐量上提升最高 2.5× 后,选择了该 GPU。
结果
| 指标 | 改进 |
|---|---|
| 推理成本 | ↓ 90 %(约 10 倍降低) |
| 响应时间 | ↑ 65 %(关键工作流更快,例如医学笔记生成) |
| 医生节省时间 | > 3000 万分钟恢复 |
链接
游戏 — DeepInfra 与 Latitude 将每标记成本降低 4 倍
Latitude 正在通过其 AI Dungeon 冒险故事游戏以及即将推出的 AI 驱动角色扮演平台 Voyage 构建 AI 原生游戏的未来,玩家可以在其中创建或探索世界,自由选择任何行动并自行编写故事。
挑战
- 每一次玩家操作都会触发对大型语言模型(LLM)的推理请求。
- 随着互动增加,成本会随之上升,但响应时间必须保持足够快,以确保体验流畅。
解决方案
Latitude 在 DeepInfra 的推理平台上运行大型开源模型,该平台由 NVIDIA Blackwell GPU 和 TensorRT‑LLM 提供支持。
针对大规模 mixture‑of‑experts (MoE) 模型,DeepInfra 将每 百万标记的成本降低为:
| 平台 | 每 1 M 标记成本 |
|---|---|
| NVIDIA Hopper(基线) | $0.20 |
| Blackwell(FP16) | $0.10 |
| Blackwell(NVFP4,低精度) | $0.05 |
结果: 在保持客户期望的准确性的前提下,每标记成本降低了 4×。
对 Latitude 的收益
- 即使在流量高峰期间也能提供快速、可靠的响应。
- 能够部署更强大的模型而不影响玩家体验。
- 随着玩家互动增长,实现成本效益的扩展。

Latitude 的基于文本的冒险游戏 “AI Dungeon” 在玩家探索动态故事时实时生成叙事文本和图像。
Source: …
Agentic Chat — Fireworks AI 与 Sentient Foundation 将 AI 成本降低最高 50 %
Sentient Labs 将 AI 开发者聚集在一起,构建强大的 开源推理 AI 系统。他们的使命是通过以下研究,加速在更难推理问题上的 AI 进展:
- 安全自治
- 代理架构
- 持续学习
Sentient Chat
Sentient Chat 是 Sentient Labs 的首个应用。它:
- 编排复杂的多代理工作流
- 集成社区贡献的 十余个专用 AI 代理
由于单个用户查询可能触发一连串自主交互,该服务 对计算资源需求极大,会产生高昂的基础设施开销。
成本节约是如何实现的
Sentient Labs 迁移至 Fireworks AI 的推理平台,使用 NVIDIA Blackwell GPU。针对 Blackwell 优化的推理栈相比之前基于 Hopper 的部署,提供了 25‑50 % 更佳的成本效率。
关键成果
- 每块 GPU 的吞吐量更高 → 在相同成本下支持更多并发用户
- 可扩展平台支撑了 24 小时内 180 万等待名单用户的病毒式增长
- 在保持低延迟的同时,单周处理 560 万次查询
“凭借 Fireworks 的 Blackwell 优化推理栈,Sentient 相比之前基于 Hopper 的部署实现了 25‑50 % 更佳的成本效率。” – Sentient Labs
可视化概览
了解更多
- 阅读 Fireworks AI 上的完整案例。
客户服务 — Together AI 与 Decagon 将成本降低 6 倍
使用语音 AI 的客服通话常常以挫败感收场:即使是轻微的延迟也会导致用户抢话、挂断或失去信任。
Decagon 为企业客户支持构建 AI 代理,语音是其最苛刻的渠道。公司需要能够在不可预测的流量负载下提供 亚秒级响应,同时保持 24/7 语音部署的 token 经济可行的基础设施。
解决方案
Together AI 在 NVIDIA Blackwell GPU 上为 Decagon 的多模型语音堆栈运行 生产推理。两家公司在以下关键优化上展开合作:
| 优化 | 描述 |
|---|---|
| Speculative decoding | 较小的“草稿”模型快速生成响应;更大的模型在后台验证准确性。 |
| Conversation caching | 将经常重复的对话元素缓存,以加速响应生成。 |
| Automatic scaling | 动态扩展在流量激增时处理请求而不降低性能。 |
结果
- 响应时间: 大幅降低,实现无缝语音交互。
- 每 token 成本: 相比之前基于 Hopper 的部署降低了 6×。
NVIDIA 在整个堆栈——包括计算、网络和软件——的极致协同设计,以及其合作伙伴生态系统,正在实现规模化下每 token 成本的巨大下降。这一势头将在 NVIDIA Rubin 平台 上继续,该平台将六颗新芯片集成到单一 AI 超级计算机中,提供 10× 性能 和 10× 更低的 token 成本,相较于 Blackwell。
了解更多
探索 NVIDIA 的全栈推理平台,了解它如何为 AI 推理提供更佳的 token 经济性: