Kiploks Robustness Score 击败大多数策略(这正是目的) 第2部分
Source: Dev.to
请提供您希望翻译的具体文本内容,我将为您翻译成简体中文。
第 2 部分 – 续篇
第 1 部分 – 为什么 90 % 的交易策略会失败:对分析护栏的深度探讨
在 第 1 部分 中,我们探讨了导致策略失败的 理论 “原因”。
在本篇文章中我们转向 战术层面——将这些分析护栏转化为 Kiploks 应用中的具体模块。
这些模块位于你的原始回测与 “Deploy”(部署)按钮之间。它们的职责是 在市场发现之前 为你的策略寻找 拒绝 的理由。
5 大支柱:稳健性
我们构建了五个分析模块,将“好得令人难以置信”的回测转化为现实的结论:
| 支柱 | 目的 |
|---|---|
| 基准指标 | 样本外(OOS)现实检验 |
| 参数稳健性与治理 | 敏感性和“脆弱性”测试 |
| 风险指标(OOS) | 在未见数据上衡量风险 |
| 最终结论汇总 | 最终的上线/不上线决定 |
| Kiploks 稳健性得分 | 用一个数字(0 – 100)统领全部 |
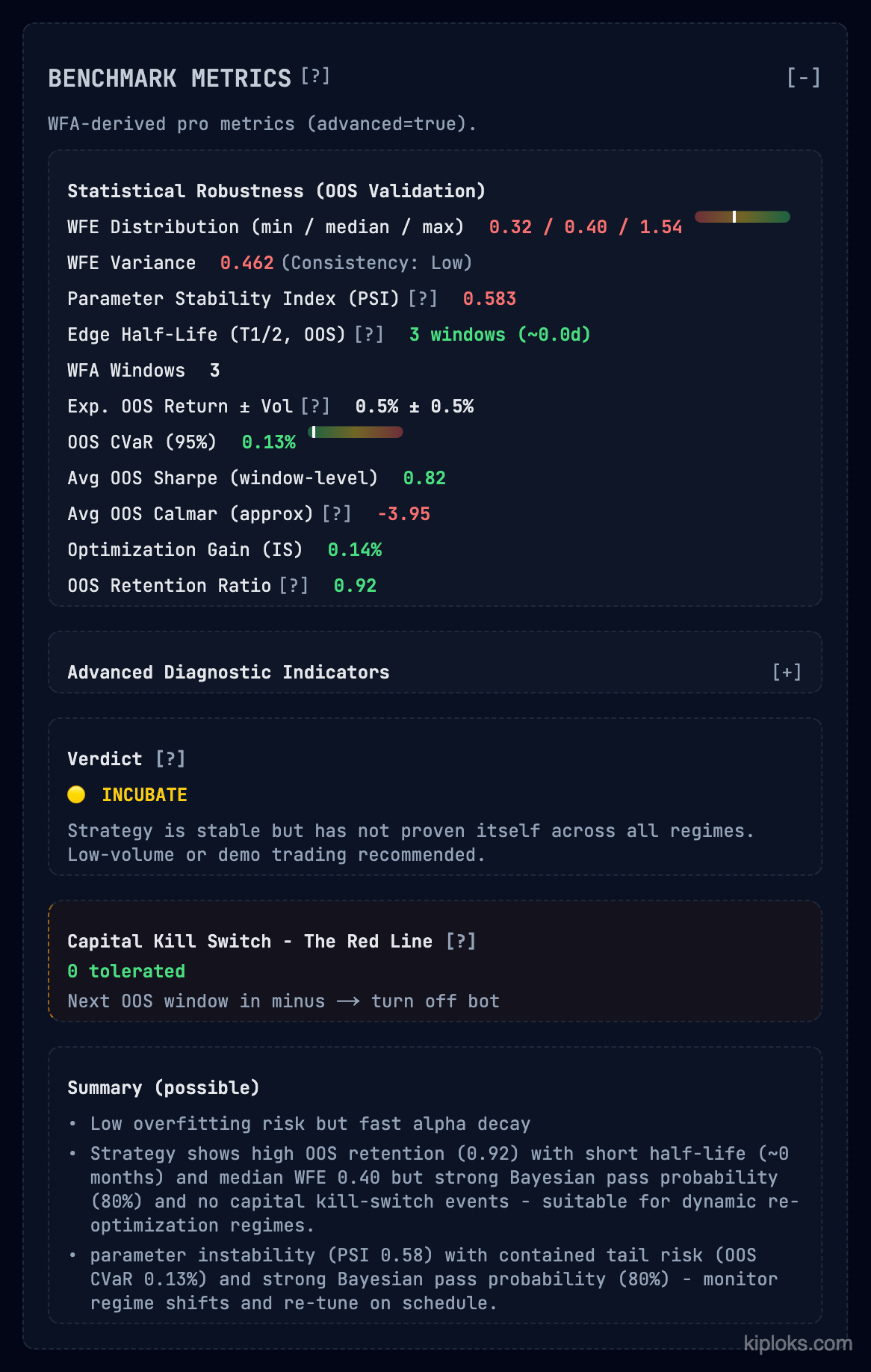
1. 基准指标 – OOS 现实检验
问题 – 回测几乎总是被过度优化。必须看看当策略面对未调校的数据时,仍能保留多少“优势”。
我们跟踪的内容
| 指标 | 描述 |
|---|---|
| WFE 分布 | 最小 / 中位 / 最大效率(例如 0.32 / 0.40 / 1.54) |
| 参数稳定性指数(PSI) | 衡量变量变化时逻辑是否仍然成立 |
| 优势半衰期 | 需要多少窗口 alpha 才会衰减(例如 3 窗口) |
| 资金紧急停机 | 硬性的“红线”规则——如果下一个 OOS 窗口为负,机器人会自动关闭 |
结论: 孵化(INCUBATE) – 该策略在 OOS 中保持了较高的保留率(0.92),但 alpha 半衰期较短。适合动态再优化,而非“一键部署、放任不管”。
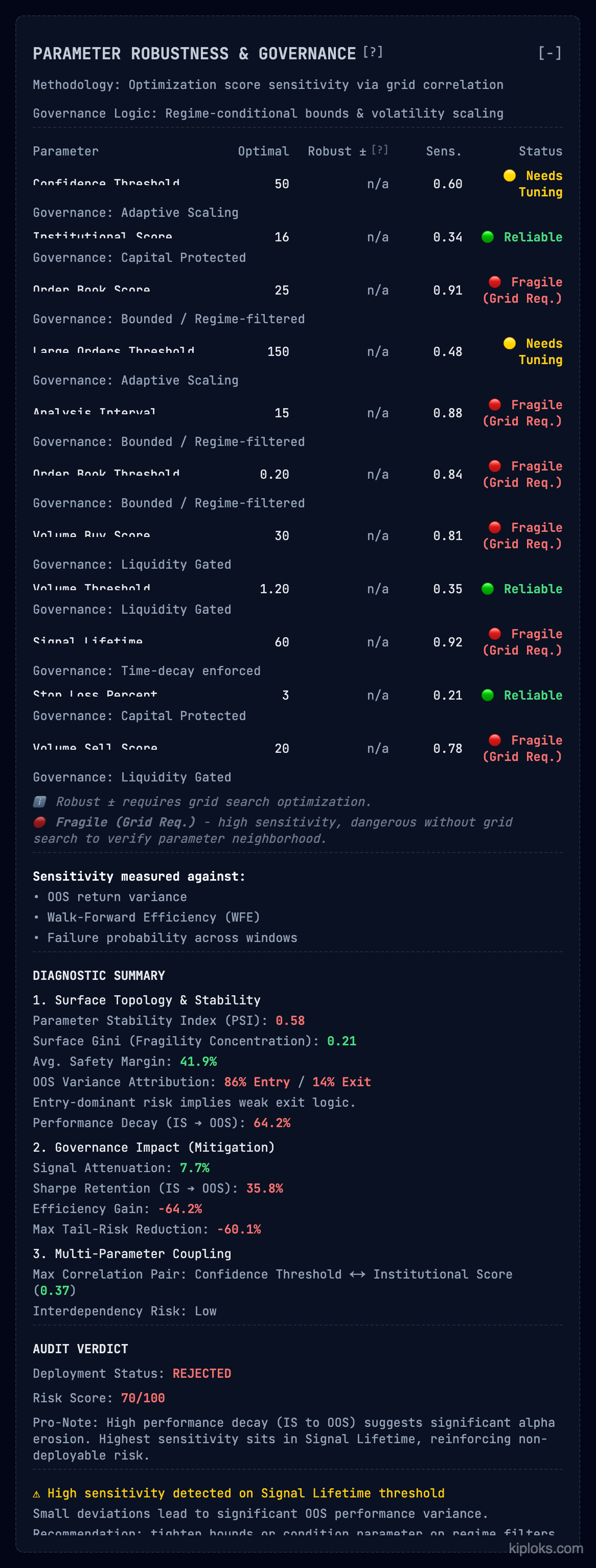
2. 参数稳健性与治理
问题 – 许多策略是“玻璃大炮”。把某个参数微调一点,优势就会消失。
我们展示的内容
对每个参数进行细粒度拆解——从 信号寿命 到 订单簿得分——并按以下维度分类:
- 敏感性 – 在没有网格搜索的情况下参数有多危险(例如
0.92表示“脆弱”)。 - 治理 – 所施加的安全护栏,如“流动性门控”或“时间衰减强制”。
- 敏感性 – 在没有网格搜索的情况下参数有多危险(例如
审计结论 提供 表面基尼系数(Surface Gini),用于显示脆弱性是否集中在某一点。示例中,从样本内到 OOS 的 高性能衰减(64.2 %) 导致硬性 拒绝(REJECTED) 状态。
3. 风险指标(样本外)
问题 – 在已优化数据上计算的标准风险指标(Sharpe、最大回撤)是谎言。它们代表“最佳情况”,而非“真实情况”。
解决方案 – 一个专门基于 OOS 数据构建的风险模块。
| 指标 | 数值 | 解读 |
|---|---|---|
| 尾部风险画像 – 峰度 | 6.49 | 表明存在肥尾行为 |
| ES/VaR 比率 | 1.29× | 突出尾部风险的严重程度 |
| 时序稳定性 – Durbin‑Watson | (检验结果) | 检查残差的自相关;低值暗示优势可能是一次幸运的连胜 |
建议 – 可部署,但需采用较小的初始规模。监控 优势稳定性;若跌破 1.50,则重新评估。

4. 最终结论汇总 – 真相时刻
问题 – 定量报告往往过于密集。需要一个明确的答案:上线、观望 还是 放弃?
部署门 提供了一个二元检查清单,列出哪些通过、哪些未通过:
| 标准 | 实测值 | 要求值 | 结果 |
|---|---|---|---|
| 统计显著性 | 0.46 | 1.96 | 未通过 |
| 执行缓冲 | ‑4.4 bps | 15 bps | 未通过 |
| 稳定性(WFE) | 0.75 | 0.5 | 通过 |
尽管逻辑稳定,但 执行缓冲 未达标,整体结论为 未通过 — 执行受限。该策略仅“喂养交易所”,因为成本侵蚀了所有优势。

Source: …
rho8kn3vx8z0ja44.png)
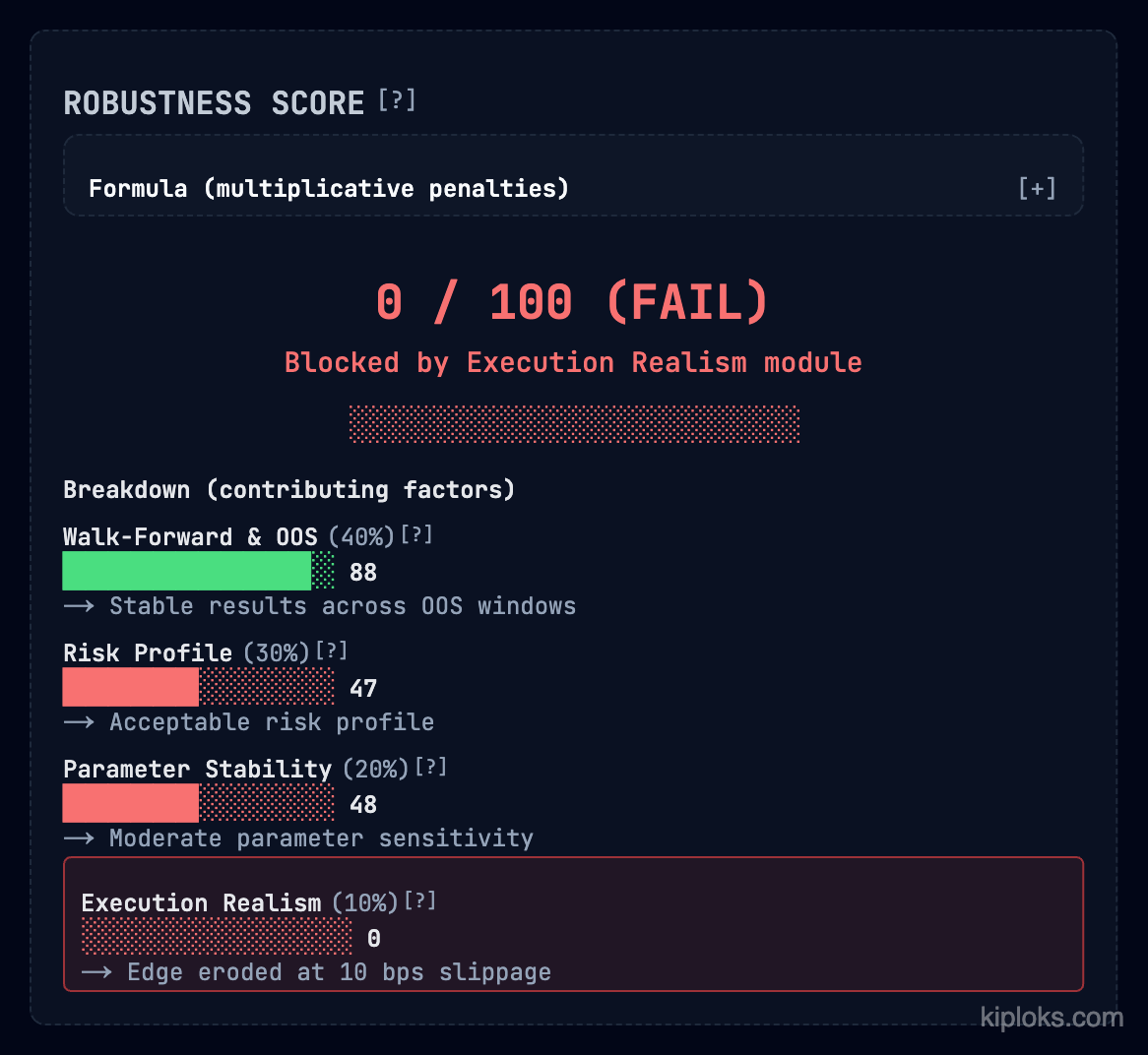
5. Kiploks 稳健性评分(0 – 100)
框架: 乘法惩罚逻辑 – 如果任一支柱(验证、风险、稳定性、执行)得分为零,则整个策略得分为零。
| 支柱 | 权重 | 分数(示例) |
|---|---|---|
| 前向回测 & OOS | 40 % | 88(稳定) |
| 风险概况 | 30 % | 47(可接受) |
| 参数稳定性 | 20 % | 48(中等) |
| 执行现实性 | 10 % | 0(边际被侵蚀) |
最终得分: 0 / 100 – 因为策略无法承受 10 bps 的滑点,被 执行现实性 模块阻断。
 (如有需要,请替换为正确的图片 URL)
(如有需要,请替换为正确的图片 URL)
要点: 五支柱框架为您提供了一种系统、数据驱动的方式,在策略进入市场之前 拒绝 弱策略,从而节省资本和时间。将 Kiploks 稳健性评分 用作快速健康检查,但始终深入各个支柱以获取可操作的洞见。
摘要:连接点
流程是一个过滤器:
- Benchmark Metrics – 测试优势。
- Parameter Governance – 测试逻辑。
- Risk Metrics – 测试下行风险。
- Verdict and Score – 最终决定。
这些模块共同将回测转化为专业的交易计划。
它们迫使你面对 What‑If Analysis——准确展示当频率下降或滑点上升时会发生什么——在投入真实资本之前。
您接下来可以做什么
- 运行报告: 将您当前的策略通过这五个过滤器。
- 审计参数: 确定哪些设置是 脆弱 的,并需要更严格的治理。
- 深入请求: 您想让我更深入探讨第 3 部分中稳健性评分公式背后的具体数学吗? 请在评论中告诉我!
我叫 Radiks Alijevs,是 Kiploks 的首席开发者。我正在构建这些工具,以将机构级的严谨性带入零售算法交易。关注我,查看第 3 部分,我将在其中展示最终的稳健性评分。