如何让LLMs在大量数据上工作
发布: (2026年1月17日 GMT+8 09:16)
6 分钟阅读
原文: Dev.to
Source: Dev.to
看起来您只提供了来源链接,但没有附上需要翻译的正文内容。请提供要翻译的文本,我会按照要求将其译成简体中文并保留原有的格式。
Source: …
文本转SQL 与 基于 LLM 的方法
文本转SQL 工具长期主导了在海量数据集上应用智能的市场。
随着大语言模型(LLMs)的兴起,格局已经转向包括各种新技术,例如:
- 检索增强生成(RAG)
- 编码/SQL 代理
- …以及其他混合解决方案
核心挑战
LLMs 无法直接看到原始数据。相反,它们只能获得抽象化的视图,例如:
- 摘要
- 示例行
- 模式描述
- 由其他系统生成的部分切片
当需要处理 大量行 时,将所有数据喂给 LLM 变得不切实际。
使用 Datatune 的解决思路
Datatune 提供了一种可扩展的方式,弥合海量数据表与 LLM 之间的鸿沟:
- 分块 & 抽样 – 将数据集拆分为可管理的块或选择具代表性的样本。
- 模式感知提示 – 包含简要的模式信息,使 LLM 理解列的含义。
- 迭代检索 – 使用类似 RAG 的循环,仅在模型请求更多上下文时获取额外行。
- 结果聚合 – 将 LLM 的部分输出合并为最终的连贯答案或 SQL 查询。
快速开始
# Install Datatune
pip install datatune
# Example: Generate a query for a large table
datatune generate \
--table my_large_table.csv \
--prompt "Find the top 5 customers by total purchase amount" \
--max-chunk-size 5000上述命令:
- 将表格按 5 000 行的块加载。
- 将模式 + 抽样数据发送给 LLM。
- 返回一个可直接运行的 SQL 语句(或 Python 代码),能够覆盖完整数据集。
🎵 Datatune


![]()

可扩展的数据转换,具备行级智能。
Datatune 不仅仅是另一个 Text‑to‑SQL 工具。使用 Datatune,LLM 和代理能够完整、以编程方式访问您的数据,并对每条记录应用语义智能。
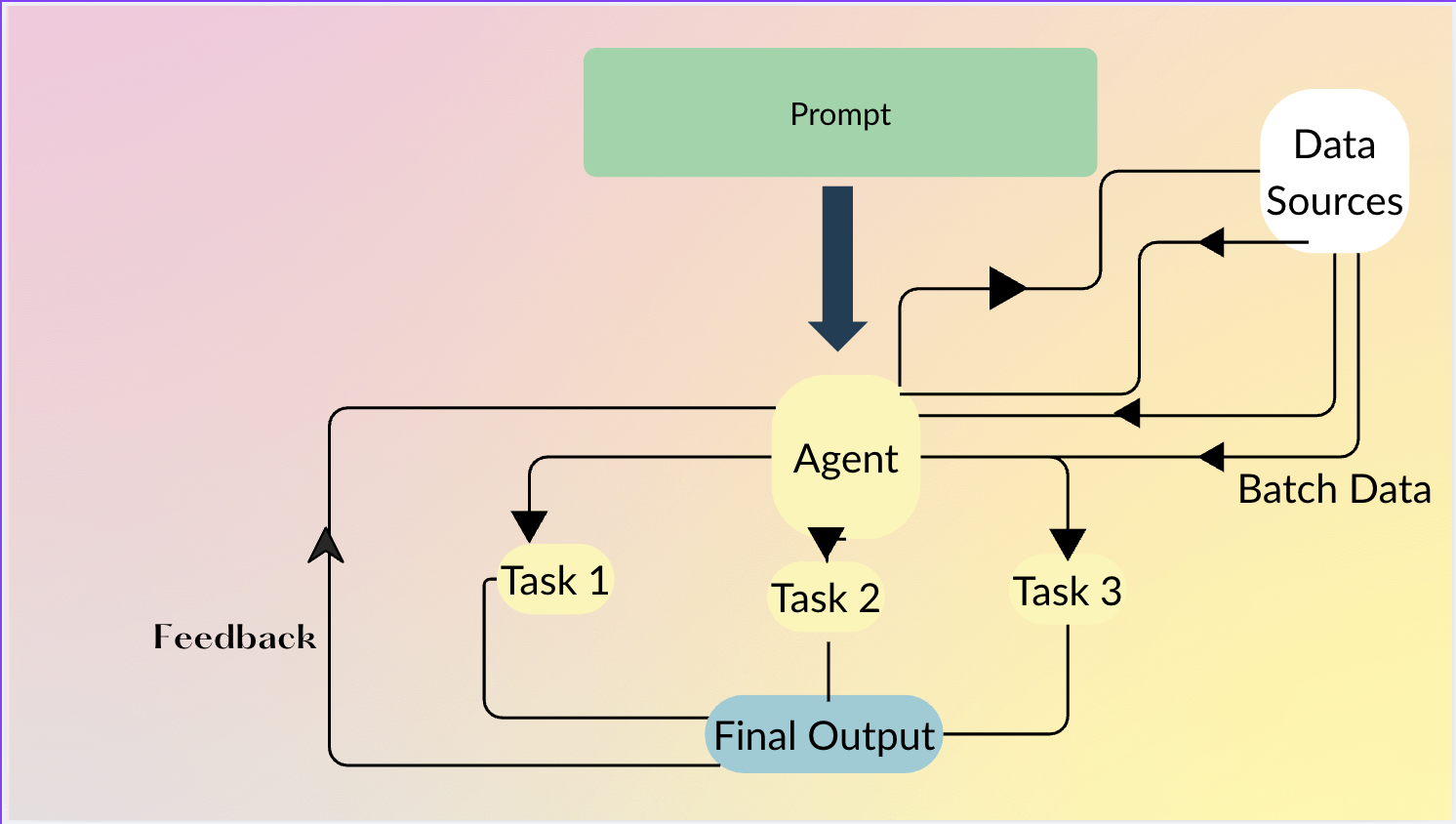
工作原理
安装
pip install datatune快速开始(Python API)
import datatune as dt
from datatune.llm.llm import OpenAI
import dask.dataframe as dd
llm = OpenAI(model_name="gpt-3.5-turbo")
df = dd.read_csv("products.csv")
# Extract categories using natural language
mapped = dt.map(
prompt="Extract categories from the description and name of product.",
output_fields=["Category", "Subcategory"],
input_fields=["Description", "Name"]
)(llm, df)
# Filter with simple criteria
filtered = dt.filter(
prompt="Keep only electronics products",
input_fields=["Name"]
)(llm, mapped)上下文长度问题
LLMs 正在变得越来越大,尤其是在上下文长度能力方面。即使是乐观的 1 亿 token 窗口,典型的企业数据集也会很快超出单次请求可处理的范围。
示例:一家中型企业
| 项目 | 数量 |
|---|---|
| 事务表中的行数 | 10 000 000 |
| 每行的列数 | 20 |
| 每列的平均字符数 | 50 |
10 000 000 rows × 20 columns × 50 characters
= 10 000 000 000 characters
≈ 2.5 billion tokens (≈ 4 characters per token)一个 1 亿 token 的上下文窗口只能容纳 1/25 的数据。
解决大规模数据处理的 Datatune
Datatune 通过以 批次 处理行,为 LLM 提供对海量数据集的完整访问:
- 使用自然语言提示转换每一行。
- 将行分组为批次并发送给 LLM。
- Dask 的并行执行将数据拆分为分区,允许同时处理多个批次。
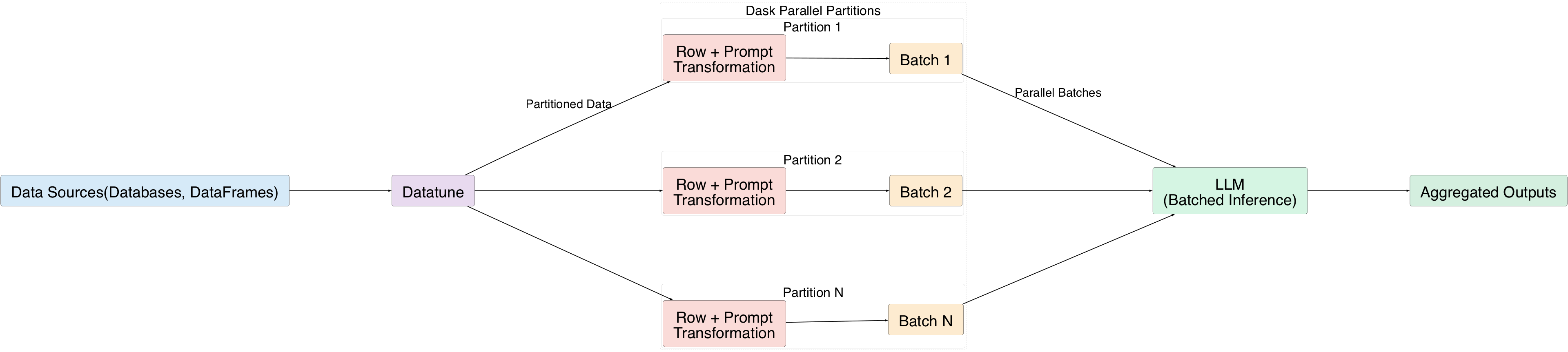
理解数据转换操作
Datatune 提供四个一阶原语(也称为 primitives):
| Primitive | Description |
|---|---|
| MAP | 将每行转换为新字段。 |
| FILTER | 保留满足条件的行。 |
| EXPAND | 添加从现有行派生的新行。 |
| REDUCE | 将行聚合为汇总统计。 |
所有原语都可以通过自然语言提示驱动。
MAP 示例
mapped = dt.map(
prompt="Extract categories from the description and name of the product.",
output_fields=["Category", "Subcategory"],
input_fields=["Description", "Name"]
)(llm, df)链接 MAP 和 FILTER
# 1️⃣ 从每条评论中提取情感和主题 (MAP)
mapped = dt.map(
prompt="Classify the sentiment and extract key topics from the review text.",
input_fields=["review_text"],
output_fields=["sentiment", "topics"]
)(llm, df)
# 2️⃣ 仅保留负面评论 (FILTER)
filtered = dt.filter(
prompt="Keep only rows where sentiment is negative."
)(llm, mapped)Datatune Agents
Agents 让用户可以用自然语言描述 想要做什么;Agent 决定 如何 链接原语(MAP、FILTER 等),在不需要行级智能时甚至可以生成 Python 代码。
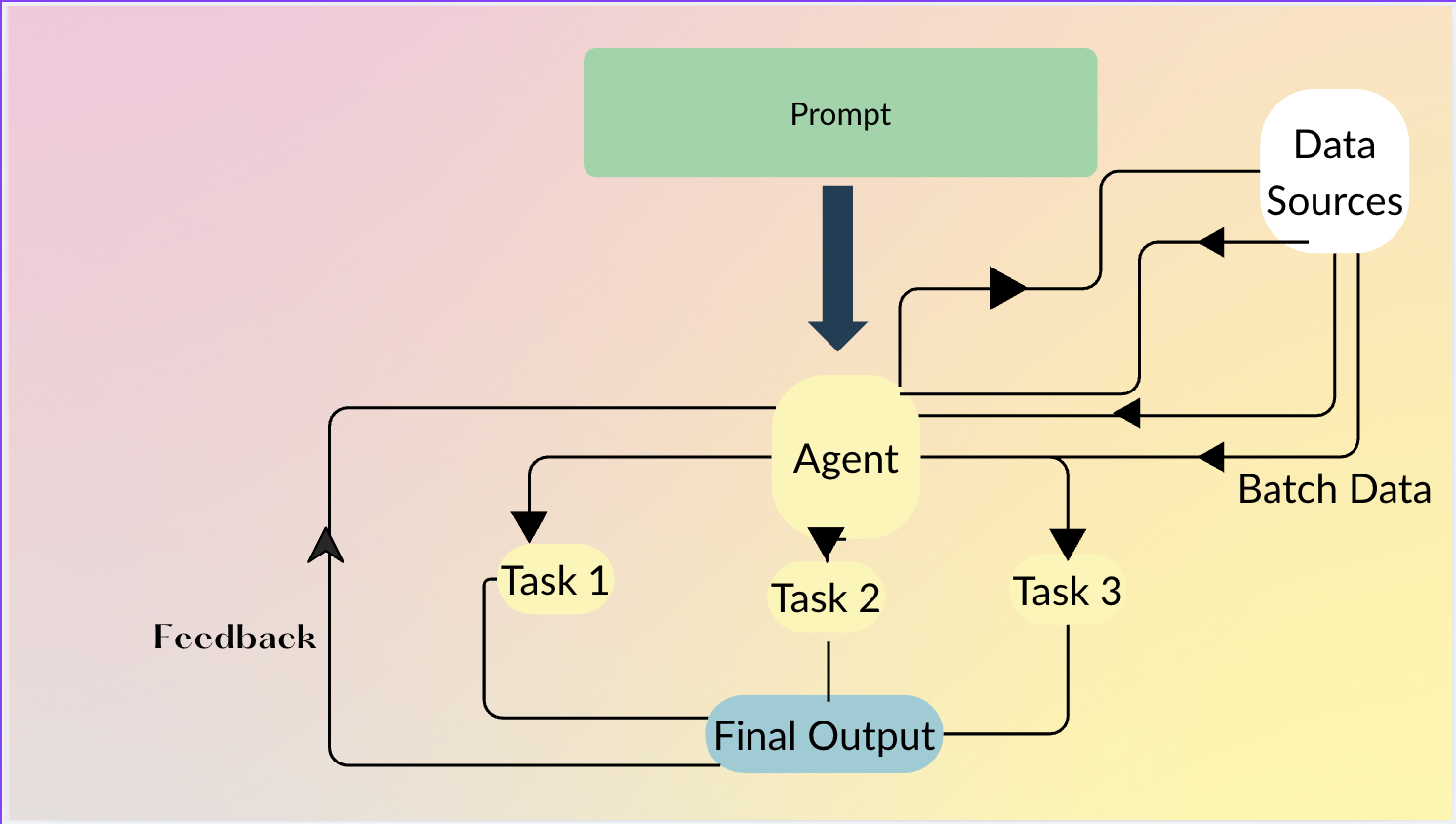
Agent 示例
df = agent.do(
"""
From product name and description, extract Category and Subcategory.
Then keep only products that belong to the Electronics category
and have a price greater than 100.
""",
df
)Agent 会自动:
- 将产品名称/描述映射为
Category、Subcategory。 - 过滤出
Category == "Electronics"且price > 100的行。
数据来源
Datatune 支持多种数据后端:
- DataFrames – Pandas、Dask、Polars 等。
- Databases – 通过 Ibis 集成(DuckDB、PostgreSQL、MySQL,…)。
贡献
Datatune 是开源的,我们欢迎贡献!
🔗 Repository: https://github.com/vitalops/datatune