如何在 Azure Synapse 的 Apache Spark 池中安装 Python 包
发布: (2026年1月7日 GMT+8 05:58)
3 分钟阅读
原文: Dev.to
Source: Dev.to

高效地在 Azure Synapse Analytics 中安装 Python 包
在 Azure Synapse 笔记本中,你可以在代码单元里使用 %pip 命令(例如 %pip install pandas)来安装包。但这种方式是临时的:该包仅在当前笔记本会话中可用,每次会话启动时都必须重新安装。频繁的重新安装会导致笔记本执行出现显著延迟,效率低下。
更持久且高效的做法是直接在 Apache Spark 池上安装包。这样可以确保库预先安装,并在每个附加到该池的会话中自动可用。
在 Spark 池级别安装包的方法
此方法需要上传一个 requirements.txt 文件,文件中列出所需的包及其版本。
- 在 Azure 门户中进入你的 Azure Synapse 工作区。
- 在左侧导航栏中选择 Manage(管理)页面。
- 在 Analytics pools(分析池)下点击 Apache Spark pools(Apache Spark 池)。
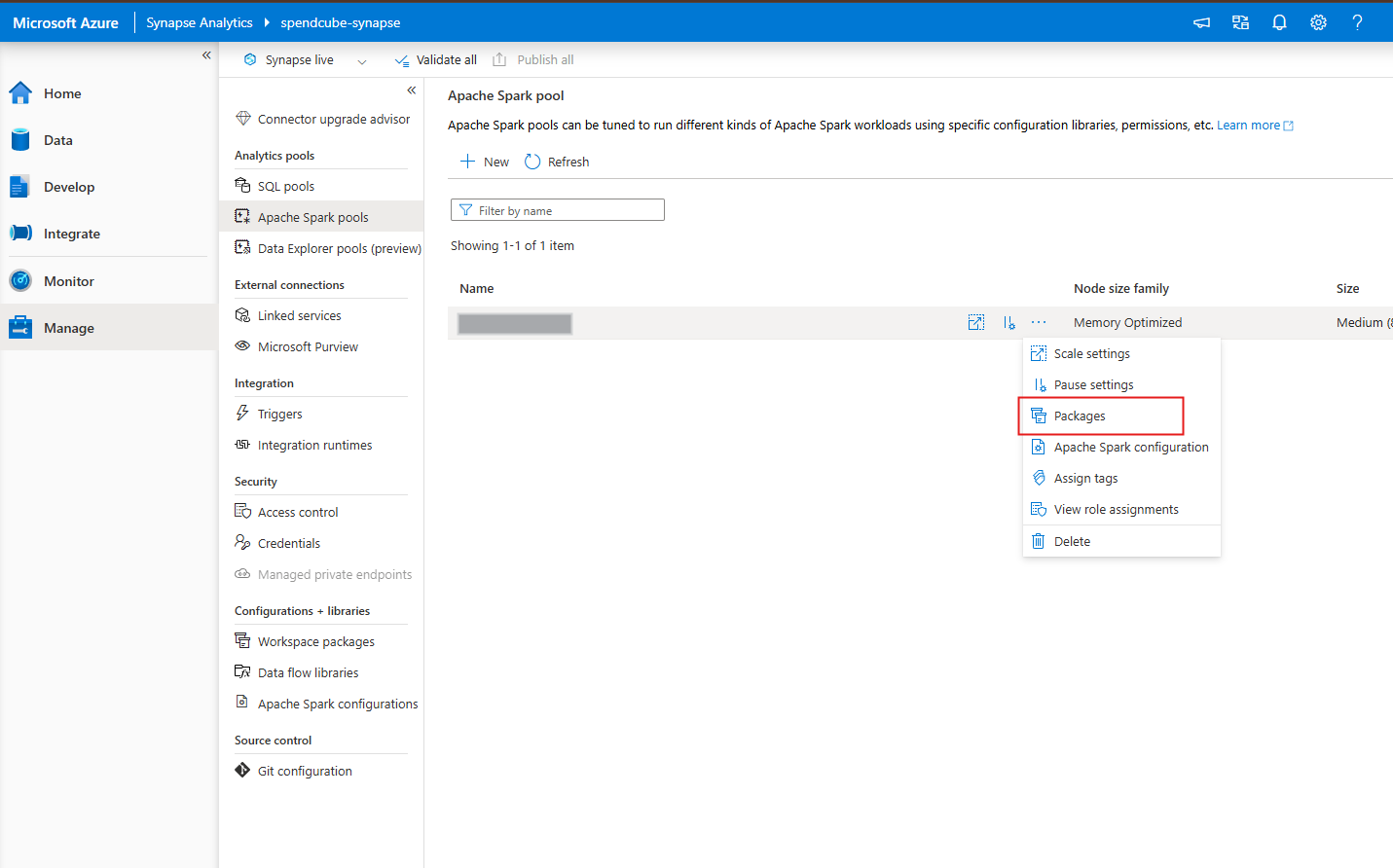
- 选中你想要安装包的 Spark 池。
- 在该 Spark 池右侧点击三个点的图标,选择 Packages(包)。
- 上传包含所需包列表的
requirements.txt文件。 - 点击 Apply(应用)保存更改。
Spark 池会更新并自动安装指定的包,过程可能需要几分钟。完成后,所有附加到该池的笔记本默认即可使用这些库。
如何生成 requirements.txt 文件
requirements.txt 是一个简单的文本文件,列出要安装的包。你可以在本地 Python 环境中轻松生成该文件。
pip freeze > requirements.txt该命令会把当前环境中所有包及其精确版本写入名为 requirements.txt 的文件。将此文件上传到 Synapse,即可确保在 Synapse 环境中安装完全相同的包版本,从而保持一致性并避免依赖冲突。