如何在 NVIDIA GPU 上使用 Unsloth 微调 LLM
Source: NVIDIA AI Blog
现代工作流展示了生成式和代理式 AI 在 PC 上的无限可能性。
示例包括调优聊天机器人以处理产品支持问题,或构建个人助理来管理日程安排。一个挑战仍然是让小型语言模型在专门的代理任务中始终保持高准确性。
这正是微调的用武之地。
Unsloth,全球使用最广泛的开源 LLM 微调框架之一,提供了一种易于上手的模型定制方式。它针对 NVIDIA GPU 进行了高效、低内存的训练优化——从 GeForce RTX 台式机和笔记本 到 RTX PRO 工作站 以及全球最小的 AI 超级计算机 DGX Spark,均可受益。
另一个强大的微调起点是刚刚发布的 NVIDIA Nemotron 3 系列开放模型、数据和库。Nemotron 3 引入了最高效的开放模型系列,极其适合代理式 AI 微调。
教授 AI 新技巧
微调就像为 AI 模型提供一次聚焦的训练课程。通过与特定主题或工作流相关的示例,模型通过学习新模式并适应当前任务来提升准确性。
选择微调方法取决于开发者希望调整原始模型的程度。根据目标,开发者可以使用以下三种主要微调方法之一:
参数高效微调(如 LoRA 或 QLoRA)
- 工作原理: 仅更新模型的一小部分参数,实现更快、更低成本的训练。
- 适用场景: 几乎所有传统全微调会使用的情形——添加领域知识、提升代码准确性、适配法律或科学任务、改进推理,或对齐语气和行为。
- 需求: 中小规模数据集(100–1,000 对提示‑样本)。
完全微调
- 工作原理: 更新模型的全部参数——适用于让模型遵循特定格式或风格的教学。
- 适用场景: 高级用例,如构建必须围绕特定主题提供帮助、遵守一定守则并以特定方式响应的 AI 代理和聊天机器人。
- 需求: 大规模数据集(1,000+ 对提示‑样本)。
强化学习
- 工作原理: 通过反馈或偏好信号调整模型行为。模型通过与环境交互学习,并利用反馈随时间改进自身。这一复杂的高级技术可以与参数高效或完全微调相结合。详情请参阅 Unsloth 的强化学习指南。
- 适用场景: 提升特定领域(如法律或医学)的准确性,或构建能够代表用户执行操作的自主代理。
- 需求: 包含动作模型、奖励模型以及模型学习环境的完整流程。
另一个需要考虑的因素是每种方法所需的显存。下表概述了在 Unsloth 上运行各类微调方法的显存需求。
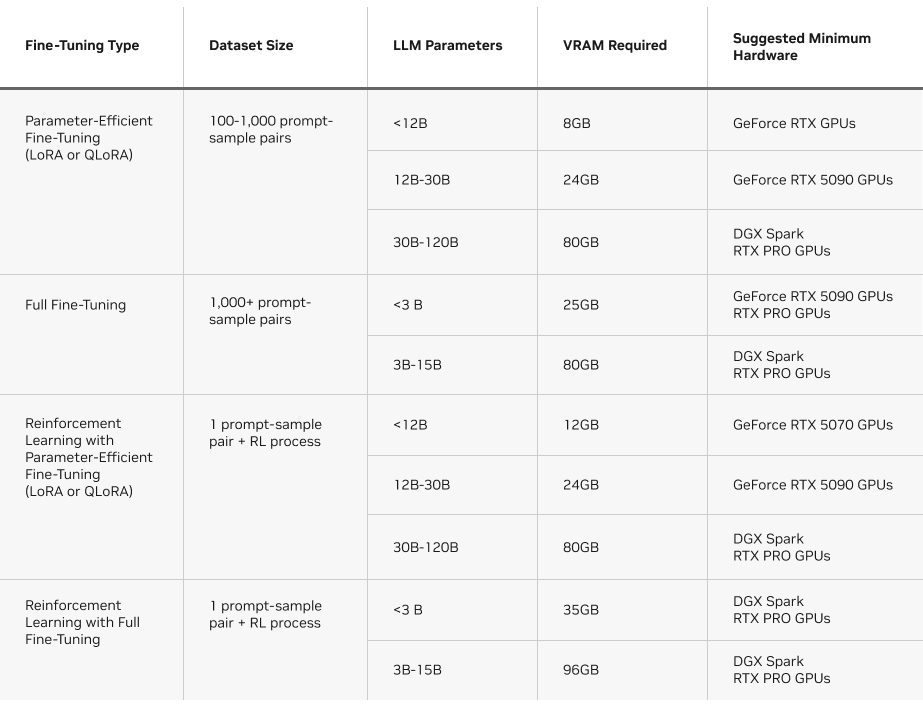
Unsloth:在 NVIDIA GPU 上快速微调的路径
LLM 微调是一项内存和计算密集型工作负载,需要在每个训练步骤中进行数十亿次矩阵乘法来更新模型权重。这种高并行度的工作负载需要 NVIDIA GPU 的强大算力才能快速高效完成。
Unsloth 将复杂的数学运算转化为高效的自定义 GPU 核心,以加速 AI 训练。它使 Hugging Face Transformers 库在 NVIDIA GPU 上的性能提升约 2.5 倍。这些针对 GPU 的专属优化,加上 Unsloth 的易用性,使微调对更广泛的 AI 爱好者和开发者社区变得可及。
该框架专为 NVIDIA 硬件构建和优化——从 GeForce RTX 笔记本到 RTX PRO 工作站再到 DGX Spark——在提供峰值性能的同时降低显存消耗。Unsloth 还提供了实用指南、示例 Notebook 和一步步的工作流。
实用指南
- Fine‑Tuning LLMs With NVIDIA RTX 50 Series GPUs and Unsloth
- Fine‑Tuning LLMs With NVIDIA DGX Spark and Unsloth
- Install Unsloth on NVIDIA DGX Spark
- NVIDIA technical blog: Train an LLM on a NVIDIA Blackwell desktop with Unsloth and scale it
想要动手本地微调的完整演示,请观看 Matthew Berman 在 NVIDIA GeForce RTX 5090 上使用 Unsloth 演示强化学习的影片(原文中已提供视频链接)。
现已发布:NVIDIA Nemotron 3 开放模型系列
全新 Nemotron 3 系列——Nano、Super 与 Ultra 规格——基于混合潜在专家混合模型(Mixture‑of‑Experts,MoE)架构,提供了效率最高的开放模型阵容,具备领先的准确性,特别适合代理式 AI 应用。
- Nemotron 3 Nano 30B‑A3B(现已发布)是计算效率最高的模型,针对软件调试、内容摘要、AI 助手工作流和信息检索进行优化,推理成本低。其混合 MoE 设计带来:
- 推理时最多可减少 60 % 的推理 token,显著降低成本。
- 1 百万 token 的上下文窗口,能够在长时间、多步骤任务中保留更多信息。
- Nemotron 3 Super 是面向多代理应用的高准确度推理模型。
- Nemotron 3 Ultra 面向复杂 AI 应用。两者预计将在 2026 年上半年推出。
NVIDIA 还发布了一套开放的训练数据集和最前沿的强化学习库。Nemotron 3 Nano 的微调已在 Unsloth 上可用。
- 从 Hugging Face 下载 Nemotron 3 Nano
- 通过 Llama.cpp 与 LM Studio 进行实验
DGX Spark:紧凑型 AI 动力源
DGX Spark 支持本地微调,并在紧凑的桌面超级计算机中提供惊人的 AI 性能,让开发者拥有比普通 PC 更多的内存。
DGX Spark 基于 NVIDIA Grace Blackwell 架构,提供高达每秒一次千兆次的 FP4 AI 性能,并配备 128 GB 统一的 CPU‑GPU 内存,为本地运行更大模型、更长上下文窗口以及更高要求的训练工作负载提供了充足的余量。
在微调方面,DGX Spark 使以下成为可能:
- 更大的模型规模: 参数量超过 300 亿的模型往往超出消费级 GPU 的显存容量,但在 DGX Spark 的统一内存中可以轻松容纳。
- 更高级的技术: 由于拥有充裕的内存和计算资源,完整微调和强化学习工作流变得可行。