如何设计实时聊天应用
Source: Dev.to
请提供您希望翻译的文章正文(除代码块和 URL 之外的内容),我将按照要求保持原有的 Markdown 格式和技术术语,将其翻译成简体中文。
介绍
设计一个实时聊天应用程序的复杂程度远远超过构建 URL 缩短器或通知服务等系统。
主要挑战
- Real‑time bidirectional communication
- Handling millions of concurrent connections
- Ensuring low latency
- Managing message persistence and offline delivery
与简单的 request‑response 系统不同,聊天应用需要持久连接并在大规模下实现即时投递。
功能需求
- 1‑对‑1 消息
- 群组消息
- 消息持久化
- 离线消息投递(当用户上线时应投递消息)
非功能性需求
- 可扩展至数百万用户
- 低延迟(< 500 ms)
- 容错
- 高可用
- 持久存储
选择正确的通信协议
因为我们的延迟要求是 < 500 ms,传统的短轮询或长轮询并不理想——它们会引入不必要的延迟和开销。
服务器发送事件(SSE)也不适用,因为它们仅支持单向通信(服务器 → 客户端),而聊天系统需要双向通信。
因此我们使用 WebSockets,它提供:
- 持久连接
- 双向通信
- 低延迟
- 减少网络开销
像 WhatsApp 这样的现代消息平台使用持久连接来实现实时通信。
高级架构
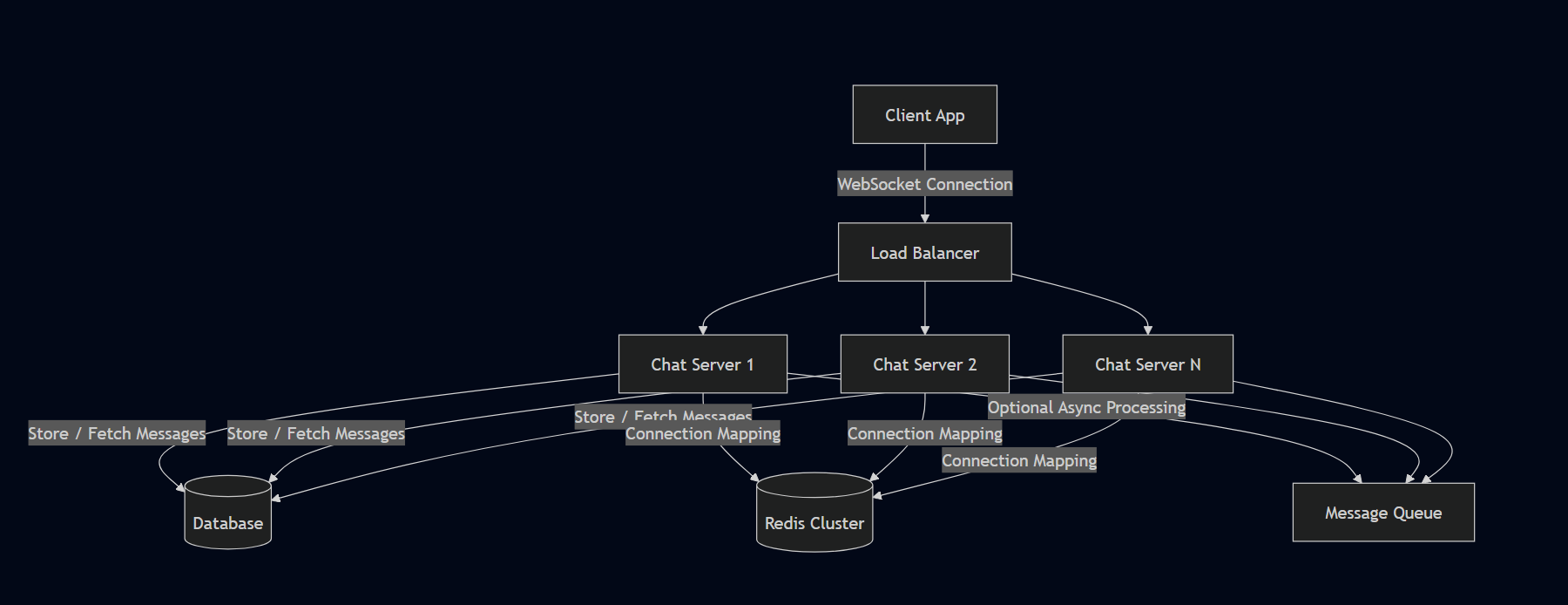
我们的系统由以下组件组成:
1. 客户端
维护与服务器的 WebSocket 连接,用于发送和接收消息。
2. 负载均衡器
在多个聊天服务器之间分配进入的 WebSocket 连接,以确保可扩展性和高可用性。
3. 聊天服务器
处理核心业务逻辑:
- 管理 WebSocket 连接
- 验证消息
- 将消息存储到数据库
- 将消息投递给接收方
4. Redis
由于负载均衡器不知道用户连接到哪台聊天服务器,我们在 Redis 中存储连接映射,例如:
userId → serverId / connectionId这使得任何服务器都能判断用户是否在线以及消息应路由到哪里。
5. 数据库
我们使用可扩展的 NoSQL 数据库(如 Amazon DynamoDB 或任何键值存储),原因如下:
- 需要高写入吞吐量
- 严格的 ACID 保证并非必需
- 横向扩展更为容易
消息流
1 对 1 消息流
- 发送方通过 WebSocket 发送消息。
- 聊天服务器验证并将消息存入数据库(用于持久化)。
- 服务器查询 Redis 以判断接收方是否在线。
- 如果在线: 立即通过 WebSocket 投递。
- 如果离线: 保持消息存储,待用户重新连接时投递。
群聊消息流
- 用户向群组发送消息。
- 消息连同群组 ID 一起存入数据库。
- 服务器获取群成员列表。
- 对每个成员,检查 Redis 中的连接状态:
- 如果在线 → 通过 WebSocket 投递。
- 如果离线 → 待其重新连接时投递。
挑战
设计架构只是开始。真正的复杂性在于大规模处理以下挑战。
扩展到数百万个 WebSocket 连接
- 每个活跃用户都会保持一个持久的 WebSocket 连接。
- 每个连接都会占用内存;单台服务器只能处理有限数量的并发连接。
- 突发流量(例如高峰时段)可能会使服务器不堪重负。
解决方案
- 使用水平扩展(多台聊天服务器)。
- 保持服务器无状态;将连接元数据存储在集中式存储(如 Redis)中。
- 使用负载均衡器均匀分配流量。
群聊中的 Fan‑Out 问题
当用户向拥有 10 000 名成员的群组发送消息时,系统必须将该消息投递给所有成员,导致巨大的投递开销。
两种常见做法
| 方法 | 描述 | 权衡 |
|---|---|---|
| 写时 Fan‑out | 立即将消息分发给所有成员。 | 读取更快,写入放大严重。 |
| 读时 Fan‑out | 只存储一份副本;在用户获取/重新连接时再投递。 | 减少写入负载,增加读取复杂度。 |
像 Slack 这样的大规模系统通常会根据群组规模采用混合方案。
消息顺序
- 由于网络延迟,消息可能会乱序到达。
- 多台服务器处理请求会导致竞争条件。
解决方案
- 为每个会话分配序列号。
- 保存时间戳。
- 让客户端根据序列 ID 重新排序消息。
处理离线用户
用户可能会意外断线(网络问题、应用崩溃、设备关机)。系统必须:
- 安全地存储未投递的消息。
- 检测用户何时重新连接。
- 可靠地投递待处理的消息。
这需要持久化存储(例如 DynamoDB)。
投递保证
消息应以何种方式投递:
- 至多一次?
- 至少一次?
- 恰好一次?
恰好一次投递在分布式系统中极其困难。大多数聊天系统选择 至少一次 投递:
- 为每条消息分配唯一 ID。
- 客户端在必要时进行去重。
摘要
构建实时聊天系统不仅仅是接入 WebSockets,还需要仔细考虑以下方面:
- 可扩展的连接处理
- 高效的分发策略
- 一致的消息顺序
- 可靠的离线存储与投递
- 合适的投递保证
通过结合 WebSockets、无状态服务器层、用于连接映射的 Redis,以及高吞吐量的 NoSQL 数据库,我们能够满足现代大规模聊天应用的功能性和非功能性需求。
故障容错
如果出现以下情况会怎样:
- 聊天服务器崩溃?
- Redis 宕机?
- 数据库节点失效?
解决方案:
- 复制数据库。
- Redis 集群。
- 健康检查和自动重启。
- 多可用区部署。
像 WhatsApp 这样的大型消息系统在每一层都设计了冗余,以避免消息丢失。
数据存储与热点分区
如果许多用户在同一个热门群组中聊天,所有写入可能会命中同一个数据库分区。这会导致:
- 热点键
- 延迟增加
- 限流
解决方案:
- 按 conversation ID + time bucket 进行分区。
- 使用分片策略。
- 在节点之间均匀分配负载。
结论
设计一个实时聊天应用远不止于在用户之间发送消息。它需要解决诸如以下的复杂分布式系统问题:
- 扩展到数百万的持久连接
- 确保低延迟
- 处理离线用户
- 维护消息顺序
- 保证容错性
通过使用 WebSockets 实现双向通信、水平可扩展的聊天服务器、使用 Redis 进行集中式连接映射,以及使用 Amazon DynamoDB 等持久存储解决方案,我们可以构建一个能够高效支持数百万用户的系统。
真正的挑战不仅在于构建架构——更在于理解可扩展性、一致性和可靠性之间的权衡。
一个设计良好的聊天系统是分布式系统原理在实际应用中如何落地的典型案例。