GPU Flight — 系统架构
Source: Dev.to
系统图
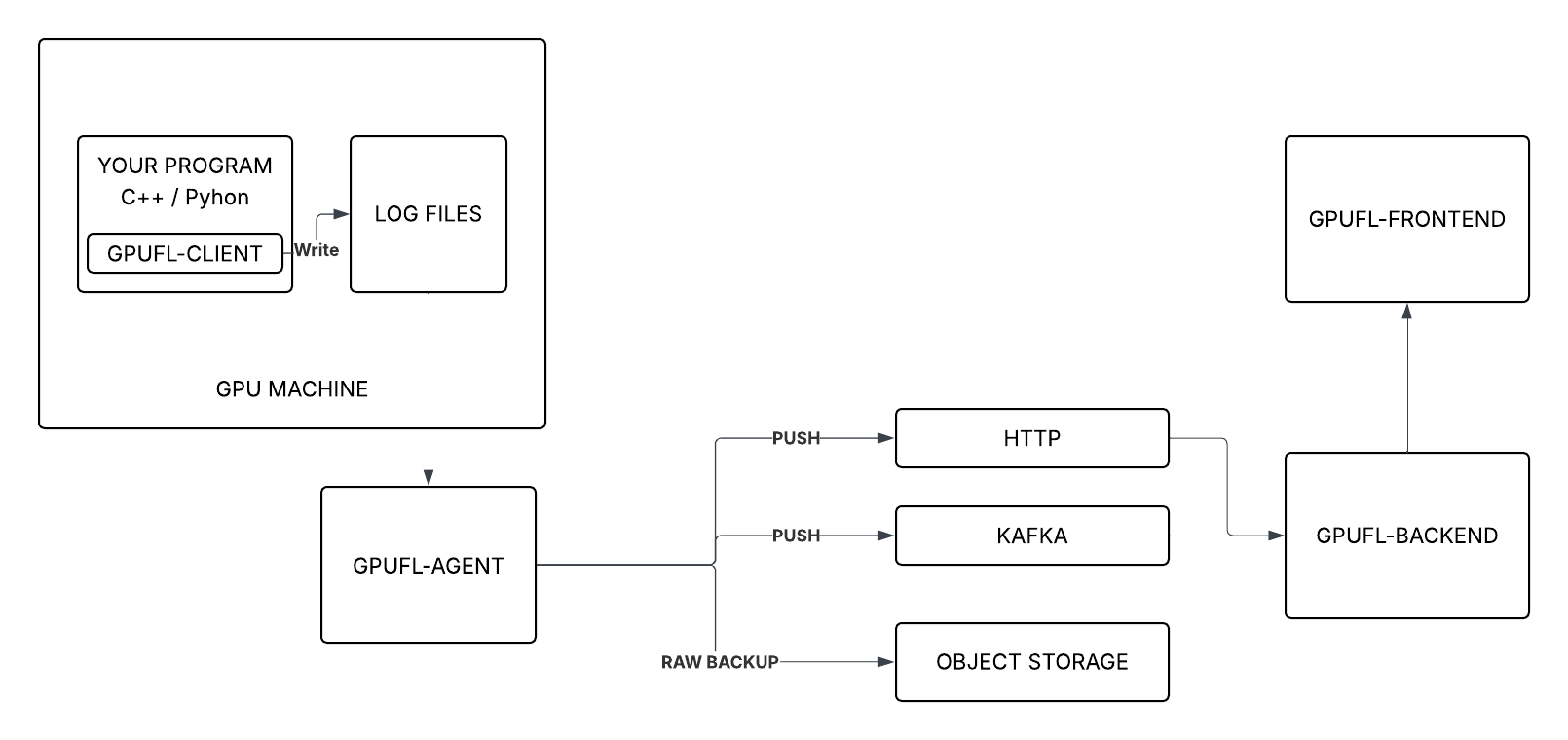
简要概述
| 组件 | 角色 |
|---|---|
| gpufl‑client | 在 GPU 机器上运行,挂钩 CUDA 活动,并写入结构化日志。 |
| gpufl‑agent | 监视日志并通过 HTTP 或 Kafka 将事件转发到后端。 |
| gpufl‑backend | 接收事件,存储它们,并提供查询 API。 |
| gpufl‑front | 用于浏览会话和检查 GPU 行为的 React UI。 |
客户端
实现为 C++ 库(或 gpufl Python 包)。
- 链接 该库到你的应用程序。
- 在程序启动时调用
gpufl::init()—— GPU Flight 将自动收集 GPU 相关事件。
客户端可以捕获的内容
- 内核启动 – 名称、网格/块维度、寄存器数量、共享内存、占用率、计时。
- 内存拷贝 – 方向、大小、持续时间、吞吐量。
- SASS 指标 – warp 级别的每指令计数器(当 SassMetrics 引擎启用时)。
- PC 采样 – warp 停顿原因分布(当 PcSampling 引擎启用时)。
- 系统指标 – 定期的 NVML 快照(GPU 利用率、显存使用、温度、功耗、风扇转速)。
日志文件
客户端会写入三个 JSONL 文件(日志轮转自动进行):
.device.log # kernel launches, memory copies, timing
.scope.log # GFL_SCOPE blocks with optional SASS/PC data
.system.log # periodic NVML snapshots代理 会跟踪文件偏移量,因此在轮转期间事件不会被重复发送。
Source: …
代理
代理是一个 独立进程,负责跟踪日志文件并将事件转发到后端。
由于它与客户端解耦,能够在 任何 能访问日志文件夹的地方运行(同一机器、NFS 共享、独立主机等)。
┌──────────────────────────────┐
│ GPU Machine │
│ │
│ gpufl-client → .log files │
│ │ │
│ gpufl-agent │ ← 最简单:代理运行在同一机器上
└────────────────────┼───────────┘
│ (或 NFS / 共享卷)
▼
gpufl-agent ← 或:代理运行在独立机器上为什么要拆分?
将分析逻辑隔离,使得仪器库更易维护且可在不同环境间移植。更换传输方式(HTTP ↔ Kafka ↔ S3)时无需重新编译客户端。
代理职责
- 并发 实时读取 三个日志流。
- 通过 游标文件 持久化文件位置(可跨重启保存)。
- 自动处理日志轮转。
- 通过 HTTP 或 Kafka 发布事件。
- 可选 将压缩的原始日志归档到兼容 S3 的存储。
原始
.log文件包含完整的事件流。归档它们可以实现长期保留、审计以及使用更新的分析逻辑重新处理。
配置示例
# HTTP — 最简单,适合开发或小规模部署
gpufl-agent \
--folder=/var/log/gpuflight \
--type=http \
--url=http://backend:8080/api/v1/events/# Kafka — 生产环境推荐
gpufl-agent \
--folder=/var/log/gpuflight \
--type=kafka \
--brokers=kafka:9092# Kafka + S3 归档
gpufl-agent \
--folder=/var/log/gpuflight \
--type=kafka \
--brokers=kafka:9092 \
--archiver-endpoint=https://s3.amazonaws.com \
--archiver-bucket=gpu-traces \
--archiver-access-key=KEY \
--archiver-secret-key=SECRETHTTP 与 Kafka 的比较
当多台 GPU 机器同时发送数据时,直接通过 HTTP 将数据发布到后端会把生产者速率与后端处理速度耦合在一起。如果后端变慢、重启或暂时宕机,事件会堆积甚至丢失。
GPU node 1 ──┐
GPU node 2 ──┼── gpufl-agent ──► Kafka ──► gpufl-backend
GPU node 3 ──┘使用消息队列(Kafka)的优势:
- 缓冲 – 在后端重启或延迟时暂存事件。
- 突发处理 – 吸收 GPU 工作负载常见的尖峰事件率。
- 多消费者 – 其他服务可以读取同一主题(告警、分析、归档等)。
对于单机或开发环境,HTTP 仍然更简单且足够使用。代理通过一个标志即可支持两种模式。
后端
实现为一个 Spring Boot REST 服务,具有两个主要职责:
摄取 –
POST /api/v1/events/{eventType},其中eventType为device、scope或system。
在 Kafka 部署中,消费者桥接从主题读取并在内部调用相同的端点。查询 API – 提供:
- 会话列表
- 随时间变化的系统指标
- 每个会话的内核事件
- 每个作用域的分析采样
前端仅使用此公共 API;不存在隐藏的内部接口。
事件类型
| 类型 | 内容 |
|---|---|
| device | 内核启动、内存拷贝、精确计时(CUPTI)。 |
| scope | GFL_SCOPE 计时块,可选地加入 SASS 指标和 PC 采样。 |
| system | 定期的 NVML 快照(GPU 利用率%、显存、温度、功耗、风扇转速)。 |
认证
所有后端端点均受 Bearer 令牌 保护。
前端
A React application that visualises:
- 会话及其时间线
- 每个内核的性能细节
- 系统级指标(GPU 利用率、温度等)
- 范围级分析数据(SASS 计数器、PC 采样)
It talks exclusively to the backend’s REST API, making the UI completely decoupled from the data‑collection pipeline.
Recap
- Client → 编写结构化的 JSONL 日志。
- Agent → 监听日志,转发事件(HTTP/Kafka),可选地归档原始日志。
- Backend → 接收事件,存储,并提供查询 API(使用 Bearer token 进行保护)。
- Frontend → 基于公共 API 构建的 React UI。
这种模块化设计使您能够替换传输机制,独立扩展摄取能力,并保持分析逻辑轻量且可移植。
GPU Flight 概览
- Ingestion – 从代理直接进行 HTTP 接收;API 密钥用于前端或外部工具的编程访问。
- Data retention – 可配置的清理策略限制磁盘使用。旧会话在超过设定的保留窗口后会自动被裁剪。
- Frontend – 使用暗色主题的 React + TypeScript 单页应用(SPA),连接后端 REST API。
主仪表板
主视图是一个针对单个分析会话的三标签仪表板:
┌────────────────────────────────────────────────────┐
│ Session: my_training_run [host: gpu-node-01] │
├──────────────┬─────────────┬───────────────────────┤
│ Kernels │ Scopes │ System │
└──────────────┴─────────────┴───────────────────────┘Kernels 标签
- kernel 启动时间线。
- 点击 kernel 可打开 Inspector,显示:
- 占用率、寄存器数量、共享内存、网格和块的维度。
- 触发启动的 CPU 调用栈。
Scopes 标签
GFL_SCOPE块的层级树,包含时间分解。- 对于使用 SASS Metrics 引擎的会话,每个 scope 还会显示来自上一次发布的分歧数据。
System 标签
- 以下指标的时间序列图:
- GPU 利用率 %
- 显存使用量
- 温度
- 功耗
- 风扇转速
会话选择器
选择器可按 host 和 application name 浏览,便于在不同机器或不同时间比较运行结果。
Source: …
下一篇:本地设置指南
将提供一个 Docker Compose 文件,用于在单台机器上启动完整的堆栈——客户端示例、代理、后端和前端。这样您就可以在无需任何手动配置的情况下尝试 GPU Flight。
接下来有什么?
- 云演示 – 正在进行实时部署。一旦可用,将发布链接,您可以在 UI 中直接浏览真实的 GPU 性能分析数据,无需自行搭建环境。
开源
GPU Flight 是开源的。