Google Cloud AI Agents with Gemini 3:构建真正可用的多代理系统
Source: Dev.to
从将大型语言模型(LLM)作为简单聊天界面转变为自主 AI 代理,代表了企业软件自微服务时代以来最重大的变革。随着 Gemini 3 的发布,Google Cloud 提供了能够进行长上下文推理和低延迟决策的基础模型,从而满足复杂多代理系统(MAS)的需求。
然而,构建一个真正可用的代理——即可靠、可观测且能够处理边缘情况的代理——不仅仅需要一个提示和一个 API 密钥。它还需要一个稳健的架构框架、对工具使用的深入理解,以及对代理编排的结构化方法。
Source: …
现代 AI 代理的架构
在其核心,AI 代理是一个 循环。不同于标准的 LLM 调用(一次性的输入‑输出交互),代理利用模型的推理能力与其环境进行交互。在 Gemini 3 于 Google Cloud 的上下文中,这一环境由 Vertex AI Agent Builder 管理。
代理循环:感知、推理与行动
| 阶段 | 描述 |
|---|---|
| 感知 | 代理从用户获取目标,并从内部记忆或外部数据源获取上下文。 |
| 推理 | 利用 Gemini 3 的高级推理能力(例如 Chain‑of‑Thought 或 ReAct),代理将目标拆分为子任务。 |
| 行动 | 代理选择一个工具(函数调用、API 或搜索)来执行子任务。 |
| 观察 | 代理评估行动的输出,并决定是继续还是结束。 |
系统架构
为了构建多代理系统,我们摒弃单体设计,采用 模块化方法,让 管理器/编排器 将任务委派给专门的 工作者 代理。

在此架构中,管理器编排器 充当大脑。它利用 Gemini 3 的高推理阈值来确定哪个工作者代理最适合当前任务,从而防止工作者出现“令牌膨胀”,因为它们仅接收其领域所需的上下文。
为什么选择 Gemini 3 用于多代理系统?
Gemini 3 为代理工作流引入了若干关键优势,这些在之前的版本中不存在:
- 原生函数调用 – 经过微调,可生成结构化的 JSON 工具调用,准确率更高,减少 API 交互中的幻觉。
- 扩展上下文窗口 – 能够保留多回合、多代理对话的完整历史,无需为每一步进行向量数据库查找。
- 多模态推理 – 代理可以“看”和“听”,将 UI 截图、音频日志或其他模态作为推理循环的一部分进行处理。
特性比较:Gemini 1.5 与 Gemini 3(用于代理)
| Feature | Gemini 1.5 Pro | Gemini 3 (Agentic) |
|---|---|---|
| Tool Call Accuracy | ~85 % | > 98 % |
| Reasoning Latency | 中等 | 优化低延迟 |
| Native Memory Management | 有限 | 集成会话状态 |
| Multimodal Throughput | 标准 | 高速流处理 |
| Task Decomposition | 手动提示 | 原生代理推理 |
构建多代理系统:技术实现
以下是使用 Vertex AI Python SDK 的金融分析用例的逐步演练。
步骤 1 – 定义工具
工具是代理的“手”。在 Gemini 3 中,工具被定义为带有清晰文档字符串的 Python 函数,模型会利用这些信息来了解何时以及如何调用它们。
import vertexai
from vertexai.generative_models import GenerativeModel, Tool, FunctionDeclaration
# Initialize Vertex AI
vertexai.init(project="my-project-id", location="us-central1")
# Define a tool for fetching stock data
get_stock_price_declaration = FunctionDeclaration(
name="get_stock_price",
description="Fetch the current stock price for a given ticker symbol.",
parameters={
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "The stock ticker (e.g., GOOG)"
}
},
"required": ["ticker"]
},
)
stock_tool = Tool(
function_declarations=[get_stock_price_declaration],
)步骤 2 – 工作代理
工作代理是专门化的。下面的示例展示了使用股票价格工具的 数据代理。
model = GenerativeModel("gemini-3-pro")
chat = model.start_chat(tools=[stock_tool])
def run_data_agent(prompt: str) -> str:
"""Hand‑off logic for the data worker agent."""
response = chat.send_message(prompt)
# Detect a function‑call request
if (response.candidates
and response.candidates[0].content.parts
and response.candidates[0].content.parts[0].function_call):
function_call = response.candidates[0].content.parts[0].function_call
# In a real scenario you would execute the function here,
# then send the result back to the model.
return f"Agent wants to call: {function_call.name}"
return response.text步骤 3 – 编排流程
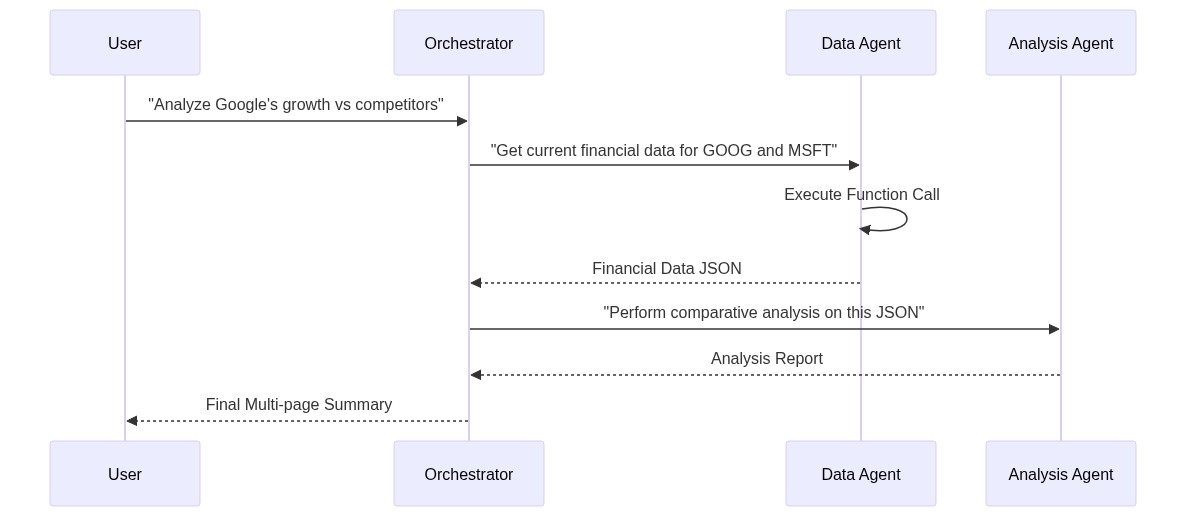
在复杂系统中,需要管理数据流,以确保 Agent A 的输出正确传递给 Agent B。下面是可视化此交互的时序图。

编排器接收高级请求(例如,“生成季度财务报告”),决定需要哪些工作代理(数据代理 → 分析代理 → 展示代理),并相应地路由中间结果。
回顾
- 定义明确、带类型的工具,模型可以调用这些工具。
- 构建专注的工作代理,每个代理专注于单一领域的专长。
- 实现管理者/编排器,利用 Gemini 3 的推理能力来路由任务、维护会话状态并最小化 token 膨胀。
通过这种模式,您可以利用 Gemini 3 的长上下文、多模态和低延迟能力,在 Google Cloud 上构建可靠、可观测且可投产的多代理系统。
[](https://media2.dev.to/dynamic/image/width=800,height=,fit=scale-down,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fv4u62qhdt2kantaop0zv.png)高级模式:状态管理与记忆
在多代理系统中,最大的挑战之一是 state drift(状态漂移),即代理在长时间交互过程中失去对原始目标的跟踪。Gemini 3 通过 Vertex AI 中的原生会话状态管理来解决此问题。
与其来回传递完整的对话历史(这会增加成本和延迟),我们可以使用 Context Caching(上下文缓存)。这使得模型能够“冻结”初始指令和背景数据,仅处理对话中的新增部分(增量)。
代码示例:上下文缓存以提升效率
from vertexai.preview import generative_models
# Large technical manual context
long_context = "... thousands of lines of documentation ..."
# Create a cache (valid for a specific TTL)
cache = generative_models.Caching.create(
model_name="gemini-3-pro",
content=long_context,
ttl_seconds=3600,
)
# Initialize agent with the cached context
agent = generative_models.GenerativeModel(model_name="gemini-3-pro")
# The agent now has 'memory' of the documentation without re‑sending it多智能体系统的挑战
构建这些系统并非没有障碍。以下是三大最常见的技术挑战以及对应的解决方案:
1. “无限循环”问题
智能体有时会陷入循环,不断调用同一工具或提出相同的问题。
解决方案: 在 Python 控制器中实现 max_iterations 计数器,并使用 Observer 模式,让独立的模型监控智能体循环中的冗余情况。
2. 工具输出歧义
如果工具返回错误或意外的 JSON,智能体可能会产生幻觉式的解决方案。
解决方案: 使用严格的 Pydantic 模型来定义函数输出,并将验证错误反馈回智能体的上下文,使其能够自我纠正。
3. 上下文溢出
尽管 Gemini 3 具备大窗口,但多智能体系统仍可能产生海量日志。
解决方案: 采用 Information Bottleneck 策略。编排器应在将每个工作者的输出传递给下一个智能体之前进行摘要,只保留高信号数据继续向前流动。
测试与评估(LLM‑as‑Judge)
传统的单元测试不足以评估代理。您必须评估 推理路径。Google Cloud 的 Vertex AI Rapid Evaluation 让您可以使用 Gemini 3 作为评审,根据以下标准对代理表现进行评分:
- 帮助性: 代理是否满足了意图?
- 工具效率: 是否使用了最少次数的工具调用?
- 安全性: 是否遵循了定义的系统指令?
评估指标表
| 指标 | 描述 | 目标分数 |
|---|---|---|
| 忠实性 | 代理对检索到的数据的遵循程度 | > 0.90 |
| 任务完成度 | 复杂多步骤目标的成功率 | > 0.85 |
| 每步延迟 | 单次推理循环所需的时间 | < 2.0 s |
结论
Gemini 3 和 Vertex AI Agent Builder 从根本上降低了构建智能自主系统的门槛。通过:
- 使用模块化的多代理架构,
- 利用原生函数调用,
- 实施严格的评估循环,
开发者可以从原型阶段迈向生产就绪的 AI 解决方案。
成功的关键不在于提示的长度,而在于编排的优雅以及提供给代理的工具的可靠性。随着我们进入代理软件时代,开发者的角色从编写逻辑转变为设计生态系统,使代理能够有效协作。