从 Anti-Vibecoding 到混沌:“Ficha Monstra”的传奇
Source: Dev.to
引言
项目 Ficha Monstra 源于需求与冲动的混合:我在黑色星期五因为纯粹的消费主义买了一个 VPS,想写点东西并学习如何在软件开发中以生产性的方式使用人工智能,同时也厌倦了在健身房的训练卡盒子里丢失我的纸质卡片。
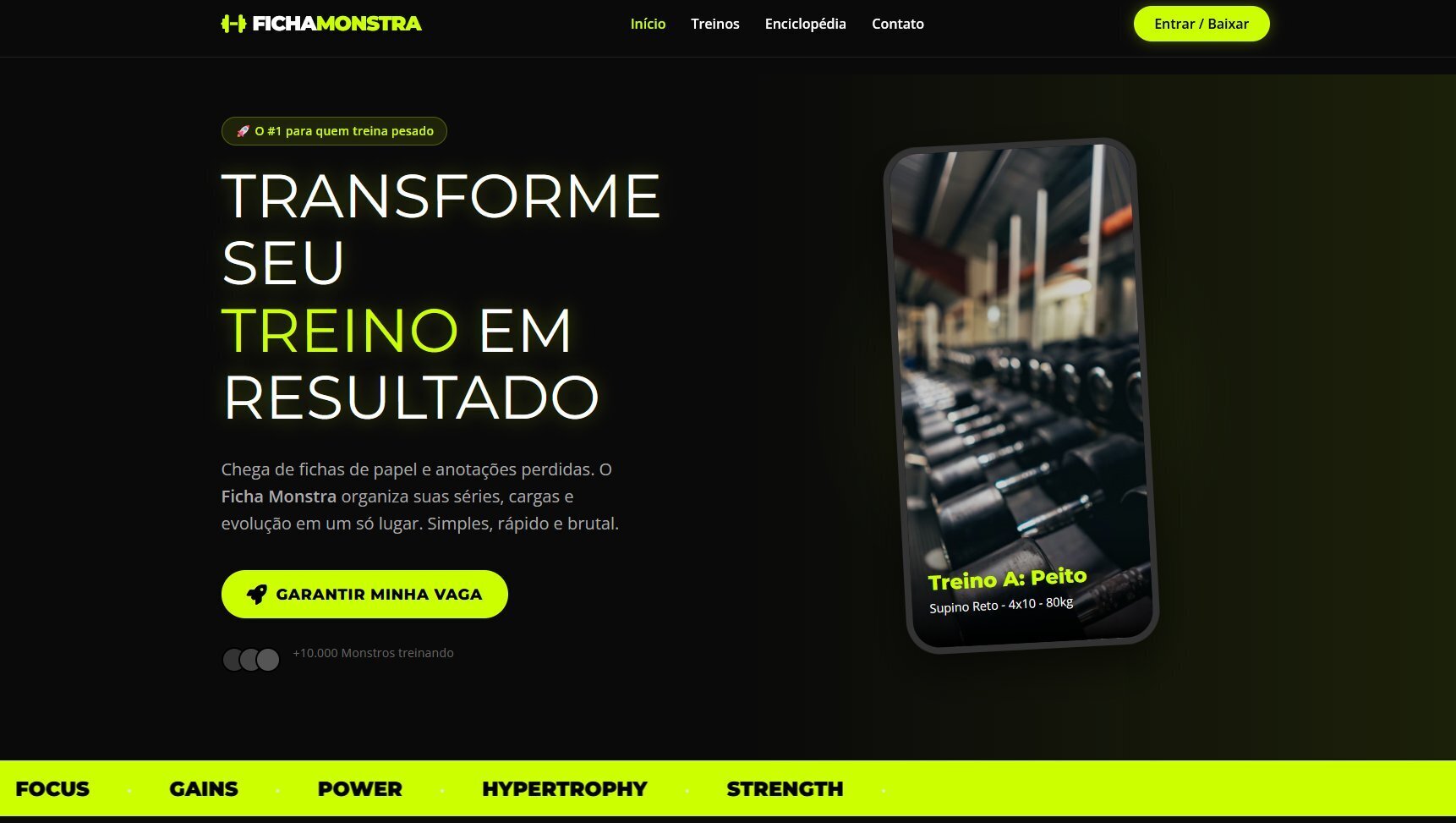
于是诞生了 Ficha Monstra,这个名字来自 Gemini。
前提是创建一个 “anti‑vibecoding” 的技术栈:我想要结构和控制。于是选择了 Blazor .NET Core、Identity、Entity Framework 和 Semantic Kernel(在 Azure 上)。
秩序阶段
我开始时很有纪律。只把 Gemini 用于头脑风暴和生成 HTML/CSS,但保持架构上的控制。我手动创建了 .NET 解决方案(以避免 AI 对旧库的依赖),并使用 Spec Kit 为项目制定了一份 “宪法”,对模型施加严格规则。
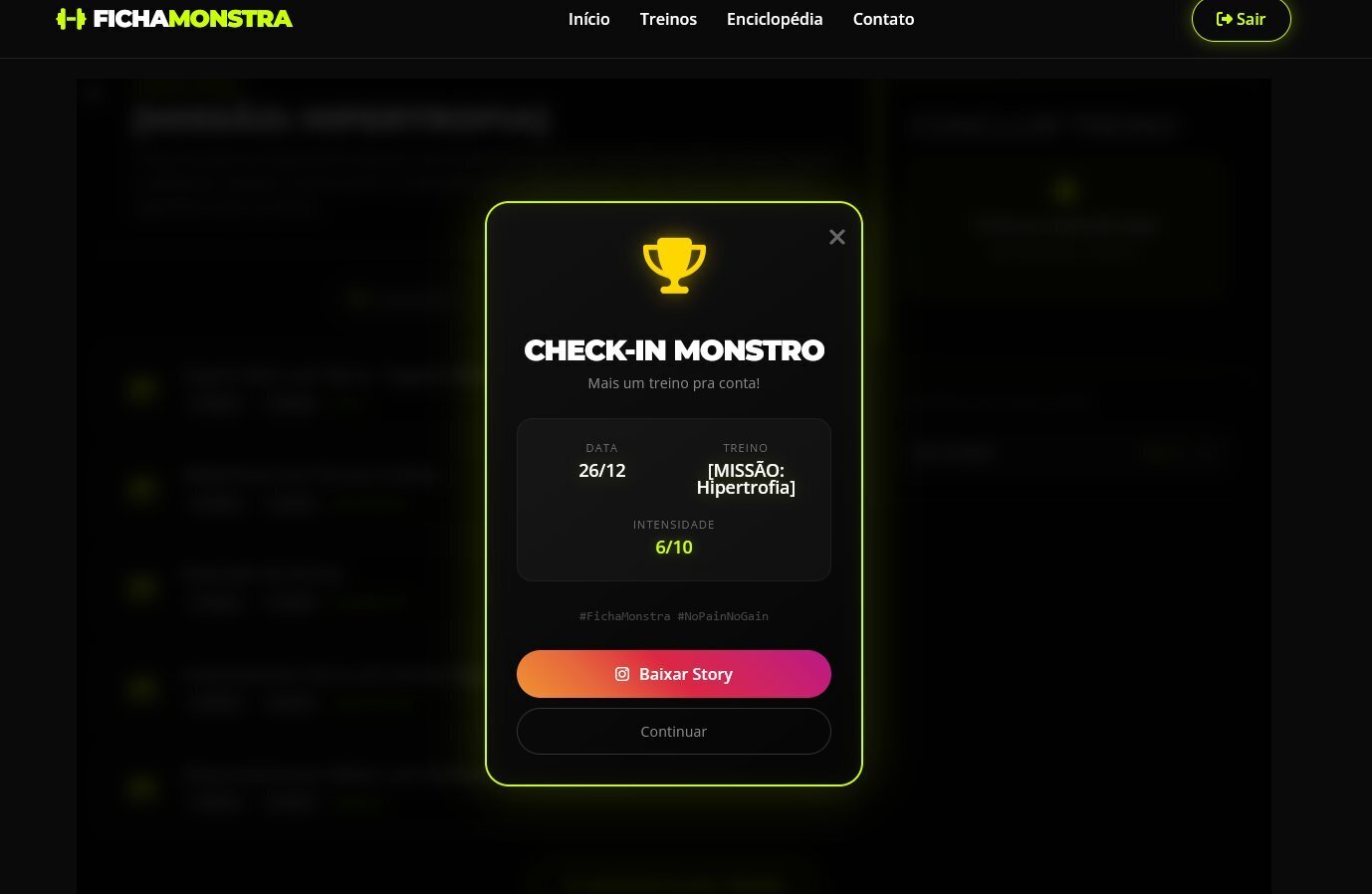
我开发了认证、创建、详情、列表和分页页面,集成了 Redis Cache,以及一个集成了 Semantic Kernel 插件的代理,能够分析数据库中的练习并根据用户提交的信息推荐训练计划。我还实现了验证、单元测试和集成测试——全部在一天内完成。
代码离理想的质量还有很大差距,这点是事实。
陷入 Vibecoding
快速看到一切运行的快感会让人膨胀。那种无敌的感觉让我放弃了最初的计划。突然之间,我开始即兴添加未计划的功能,如游戏化、多仪表盘和管理员后台。
技术严谨性消失了。我不再批评生成的代码,结果不言而喻:项目从原本还算 “可爱”,迅速退化。
学到的经验
尽管最终代码混乱,却有技术亮点:我把 Playwright 与 Gemini 通过 MCP 结合。看到模型“观察”界面并自行运行测试的过程令人印象深刻。
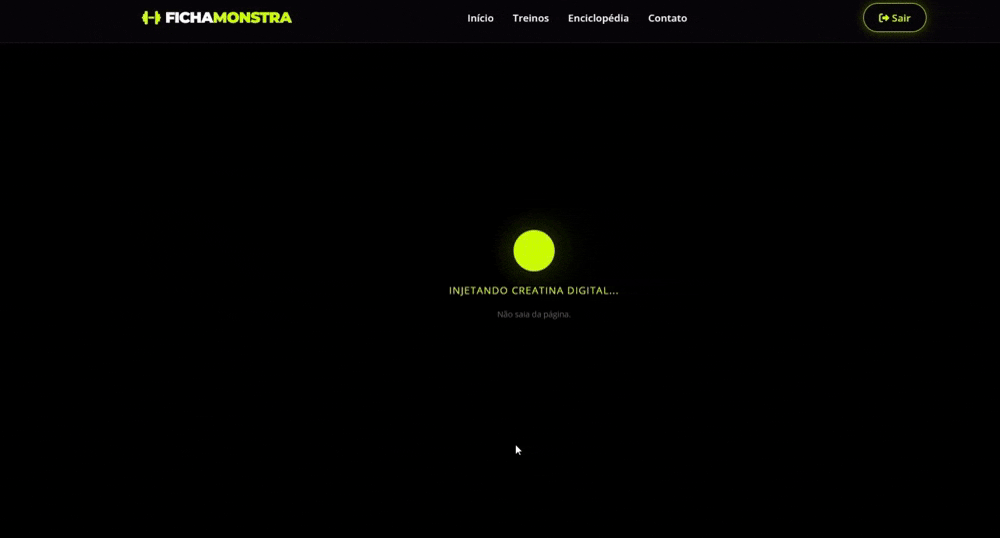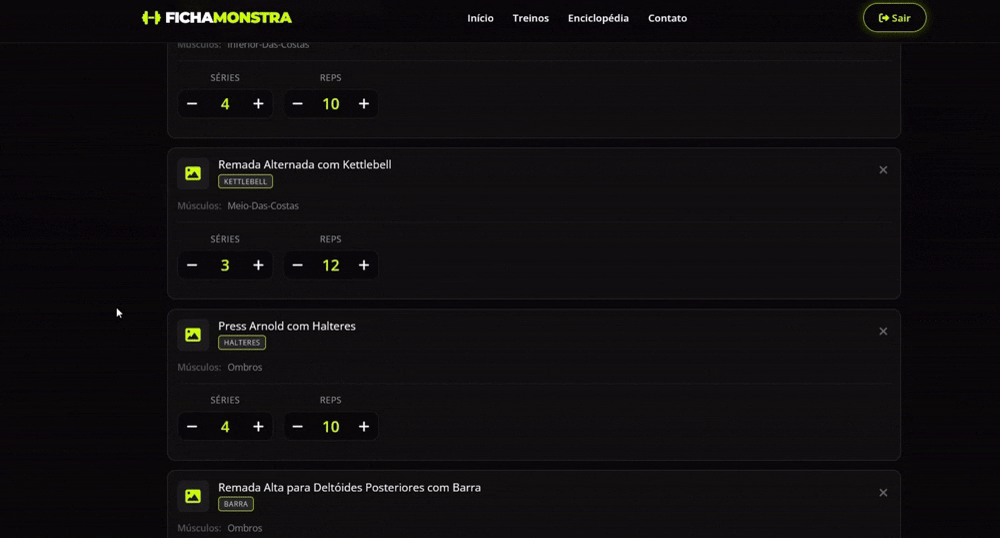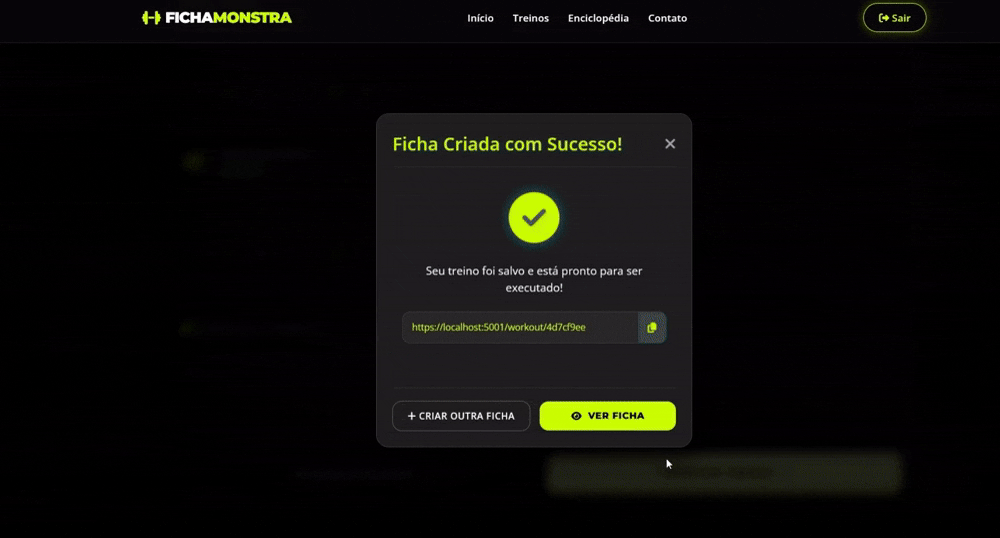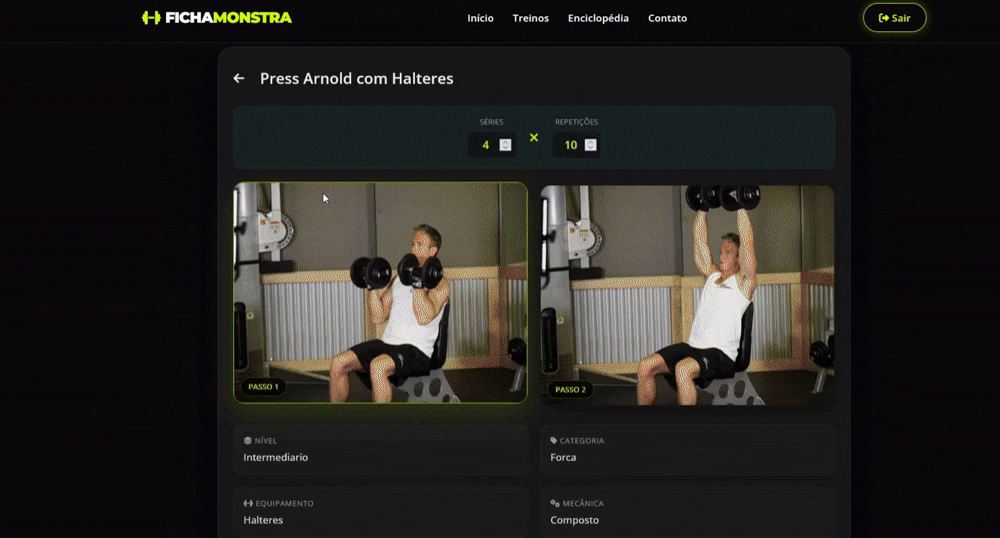
Spec Kit 让人惊喜;虽然有点难以理解,但它真的在创建功能时提供了帮助和控制。
有时比起再写一个提示词并等待答案,亲自下手写代码、解决问题更有效。必须学会辨别模型何时在 “滑冰”,因为真正滑倒的往往是你,而不是模型。
最终,Ficha Monstra 教会我:AI 能加速构建,但如果放松警惕,也会加速技术债务的产生。生成的代码可能丑陋且糟糕,必须成为审查者而不是单纯的编码者。掌握软件工程的基础会产生巨大的差异。
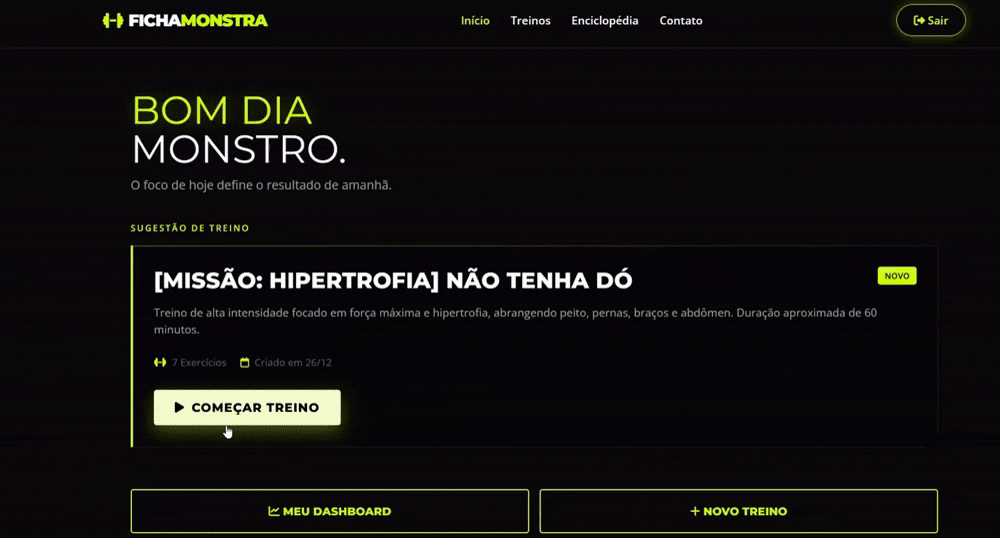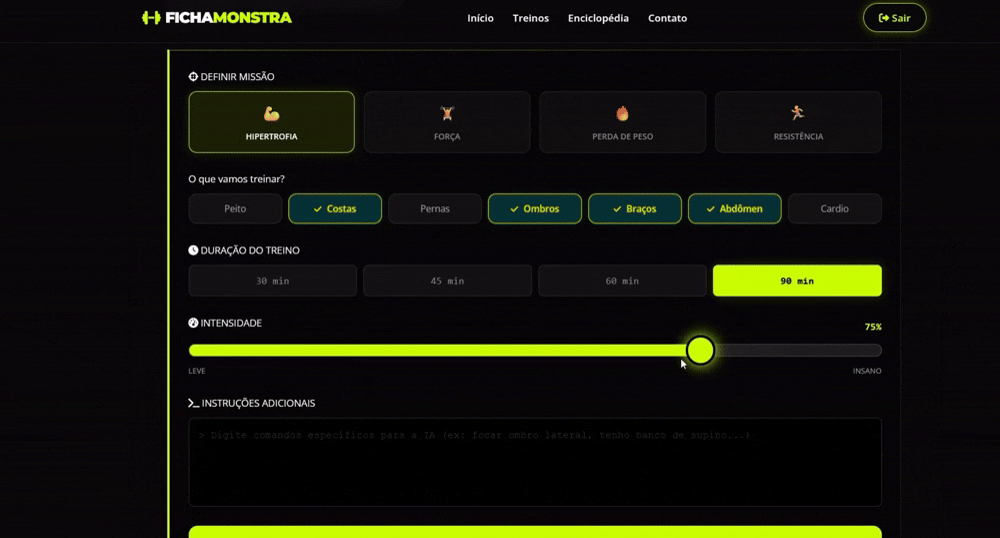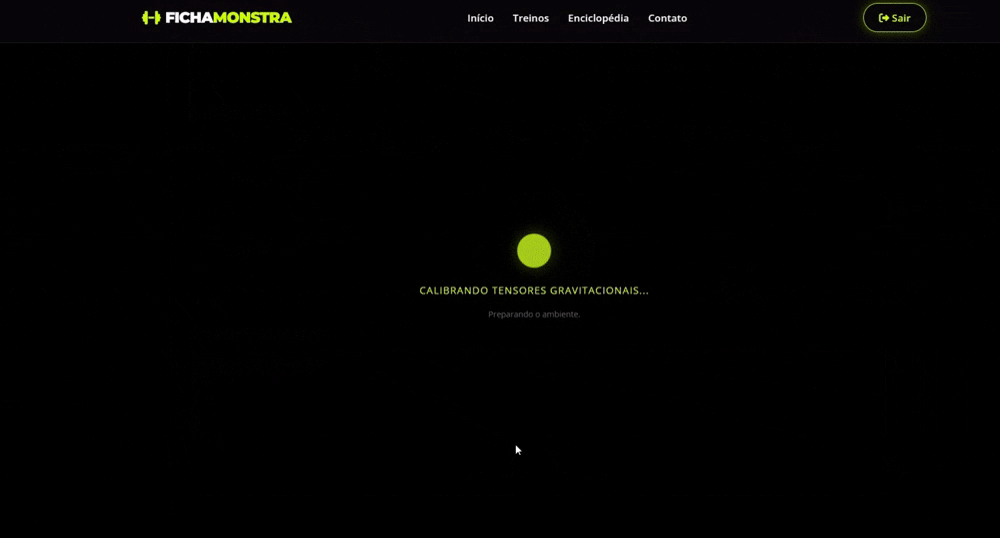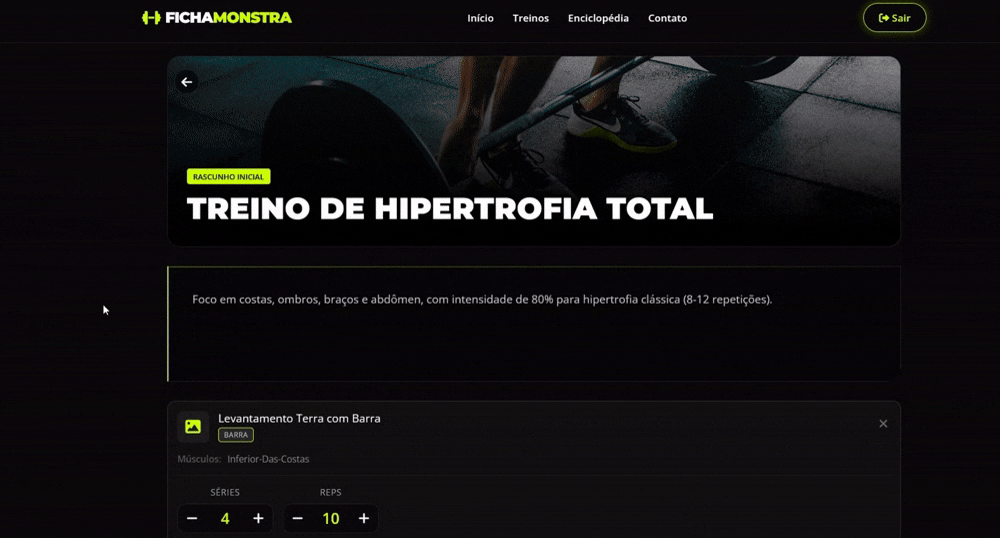
它也让我对 2026 年产生了一种奇怪的预感——一切都不会再像以前那样,真的。