分布式任务队列系统
Source: Dev.to
问题描述
你正在运行一个处理成千上万张图片的数据管道。工作节点正常运行,一切顺利。突然,协调服务器崩溃了。
- 任务消失。
- 两个工作节点开始处理同一张图片。
- 你的管道停滞不前。
这就是分布式系统的真实写照。机器会失效,网络会分区。如果没有为故障做好设计,故障会演变成灾难。
我想了解生产系统是如何处理这些情况的,于是从零实现了一个分布式任务队列。没有使用 Redis,而是自行实现了基于 Raft 共识算法的协调层。结果是:一个可以在多个工作节点上执行 Python 代码的系统,当 broker 崩溃时,其他节点能够无缝继续,且不会丢失数据。
架构
系统由三个组件组成:

- Broker 集群 – 在三台节点上运行 Raft 共识协议。它们选举出一个 leader,所有任务状态都会复制到每个节点。如果有一个 broker 崩溃,剩余的两个仍然可以继续工作。
- Workers – 无状态。它们向 leader 轮询任务,在沙箱子进程中执行代码,并上报结果。Worker 可以水平扩展。
- Clients – 提交任务并轮询结果。Worker 与 client 都会自动发现当前的 leader。
一个重要的区别是:Raft 集群保证 broker 故障不会导致数据丢失。Worker 故障会被检测到,但处理方式不同(见后文)。
任务结构
任务封装了要远程执行的 Python 代码:
{
"task_id": "uuid-1234",
"task_type": "python_exec",
"payload": {
"code": "def count_words(text): return len(text.split())",
"function": "count_words",
"args": ["hello world"]
},
"status": "pending"
}生命周期很简单:pending → processing → completed。Broker 负责跟踪每一次状态转换,Raft 确保所有 broker 对当前状态达成一致。
Raft 共识
核心问题:三个 broker 必须保持完全相同的任务状态。直接广播会导致消息乱序、丢包以及视图分歧。Raft 通过 leader 选举和日志复制来解决这些问题。
Leader 选举
每个节点最初都是 follower,等待 leader 的心跳。如果 follower 在随机超时时间(1.5–3 秒)内没有收到心跳,它会转为 candidate 并向同伴请求投票。
def _on_election_timeout(self):
self.state = RaftState.CANDIDATE
self.current_term += 1
self.voted_for = self.node_id
# Request votes from all peers...随机超时可以防止死锁:如果所有节点同时超时,它们都会给自己投票,导致无人获胜。随机化保证通常只有一个节点会先发起选举。
日志复制
leader 将命令追加到自己的日志并发送给 follower。只有当多数节点拥有该条目时,条目才被视为 已提交。
def _try_commit(self):
for n in range(len(self.log) - 1, self.commit_index, -1):
# Count how many nodes have this entry
count = 1 # Leader has it
for peer in self.peers:
if self.match_index.get(peer, -1) >= n:
count += 1
# Commit requires majority (2 of 3 nodes)
if count >= majority:
self.commit_index = n
self._apply_committed()
break多数节点的要求正是 Raft 能容错的关键。如果 leader 在只复制到一个 follower 后崩溃,该条目尚未提交。存活的节点会选举出新 leader,未提交的条目会被回滚,从而保持一致性。
持久化说明
我的实现把所有数据都保存在内存中。生产环境的 Raft 必须在确认消息之前将 currentTerm、votedFor 以及日志写入磁盘。没有持久化的话,崩溃后节点可能以空状态重启,在同一任期内再次投票,从而违反 Raft 的安全性。这里的实现仅用于学习,不能直接用于生产。
故障场景
分布式系统的真正考验在于出现故障时的表现。下面列出几个关键场景。
场景 1:Leader Broker 死亡
这是 Raft 设计要处理的情形。
初始状态: Broker 1 为 leader,Broker 2、3 为 follower。两个 worker 正在处理任务。
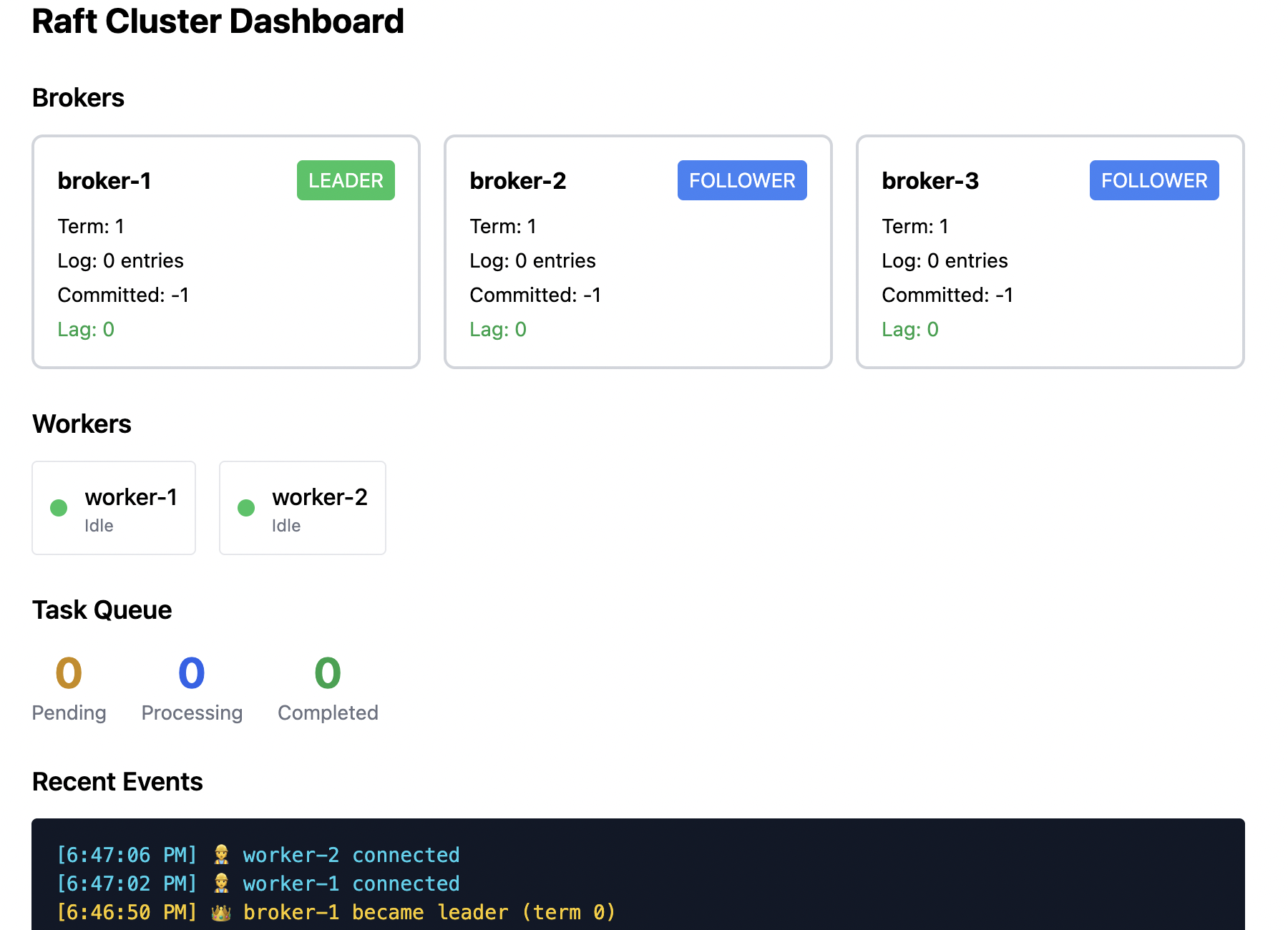
故障发生: Broker 1 崩溃(或被网络分区)。
后续过程:
- Broker 2、3 收不到来自 Broker 1 的心跳。
- 它们的选举计时器在 1.5–3 秒内超时。
- 其中一个(例如 Broker 2)先超时,变为 candidate 并请求投票。
- Broker 3 将投票给它(Broker 1 已不可达)。
- Broker 2 成为新 leader 并开始发送心跳。
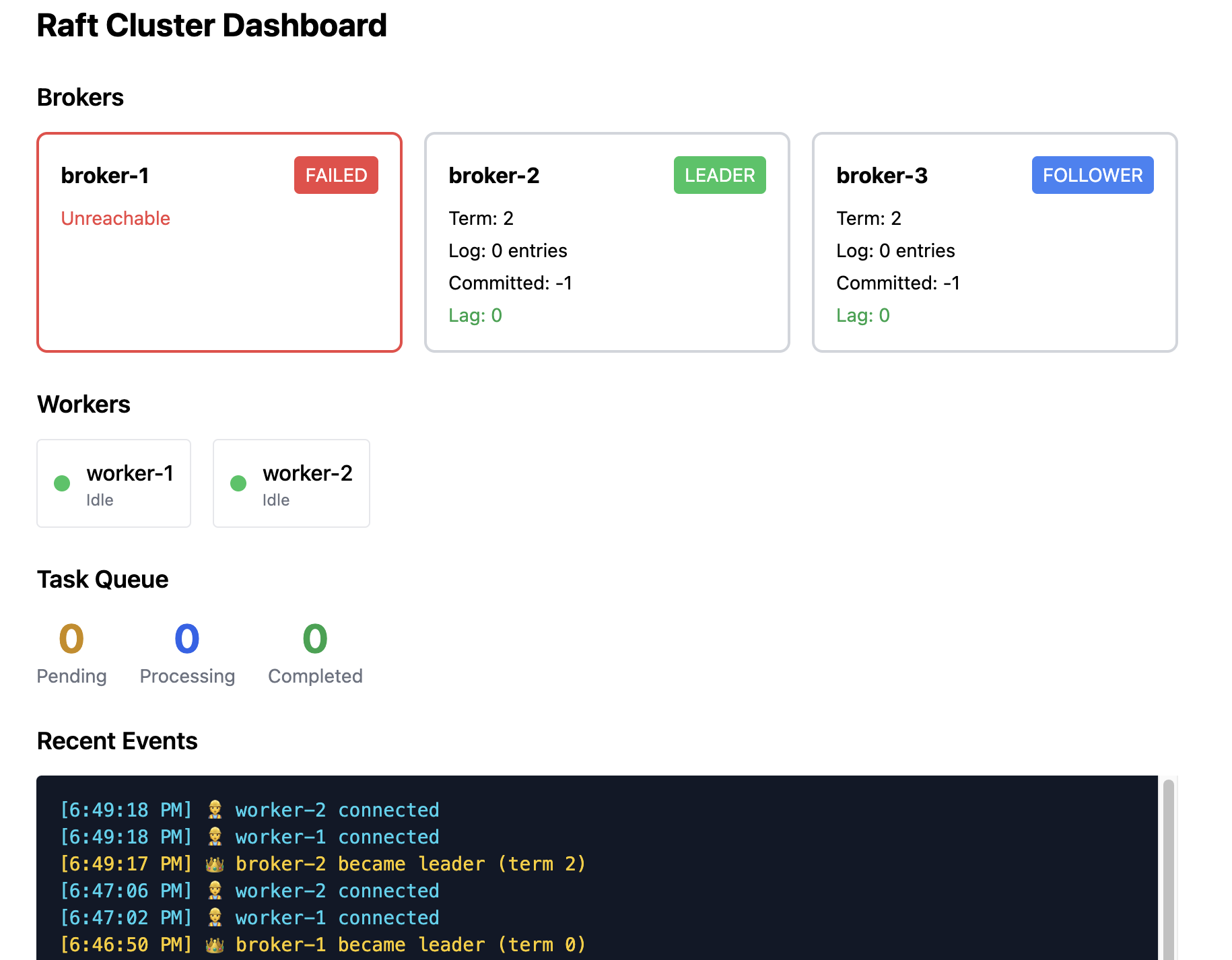
Worker 行为: Worker 对 Broker 1 的下一次请求会因连接错误而失败。它们会遍历已知的 broker 地址,查询 /status,发现 Broker 2 现在是 leader,并重新连接(通常在 1–2 秒内完成)。
数据安全性: 在崩溃前已经提交的任务是安全的——它们已经存在于多数节点上,新 leader 也拥有这些数据。未提交的条目(只被少于两台机器确认)会丢失,但这些条目从未向客户端确认过。
场景 2:Follower Broker 死亡
相较于 leader 故障要简单得多。
初始状态: Broker 1 为 leader,Broker 3 崩溃。
后续过程: 基本没有可见影响。leader 注意到 Broker 3 对 AppendEntries 没有响应,但仍能与 Broker 2 通信。只要 3 台机器中有 2 台存活,集群仍保持法定人数(quorum),写入操作仍然成功,因为 leader 会把日志复制给 Broker 2,收到确认后提交。
如果 Broker 3 恢复: 它会作为 follower 重新加入,从 leader 那里获取缺失的日志条目并追上进度。
场景 3:Worker 在任务执行中途死亡
Broker 能检测到失效的 worker 并自动重新分配任务。
初始状态: Worker 1 正在处理 Task A,Worker 2 处于空闲。

故障发生: Worker 1 崩溃或网络中断。
Broker 响应: Broker 通过心跳监控 worker 状态。当检测到 Worker 1 的心跳停止时,Broker 将该任务状态标记回 pending 并重新放回队列。随后 Worker 2(或其他可用 worker)会取走 Task A 并继续执行。
结果: 任务不会丢失,系统在 worker churn(增减)情况下仍保持一致性。