在 Rust 中设计防崩溃、幂等的 EVM 索引器
发布: (2026年2月20日 GMT+8 03:18)
7 分钟阅读
原文: Dev.to
Source: Dev.to
数据管道并不是因为慢而失败——它们失败是因为写入了部分状态、盲目重试,并在重启时导致不一致。
技术栈
- Rust (Tokio)
ethers-rs用于 RPC- PostgreSQL
- SQLx
- Axum 用于查询 API
实际问题:部分状态
假设区块 N 包含:
- 120 笔交易
- 350 条日志
一个天真的处理流程可能是:
- 插入区块
- 插入交易
- 插入日志
- 更新检查点
会出现什么问题?
如果进程在第 2 步(交易已插入)之后、第 3 步(日志插入)之前崩溃,数据库将处于不一致状态:
- 区块 已存在
- 交易 已存在
- 日志 缺失
- 检查点 未更新
重启后你必须决定:
- 重试 失败的步骤?
- 跳过 它并继续?
- 覆盖 已存在的数据?
- 检测 并处理部分写入?
大多数索引器都处理不好这个问题。
设计目标
在编写代码之前,我定义了严格的不变式:
- Atomicity(原子性): 一个块要么 完全写入,要么根本不写入。
- Restart safety(重启安全): 重启进程必须是安全的。
- Idempotence(幂等性): 重复处理不会破坏状态。
- Durable checkpoints(持久检查点): 检查点必须反映持久状态。
- No external consistency assumptions(不做外部一致性假设).
设计的核心思想是:数据库是真实来源;进程是可丢弃的。
系统架构
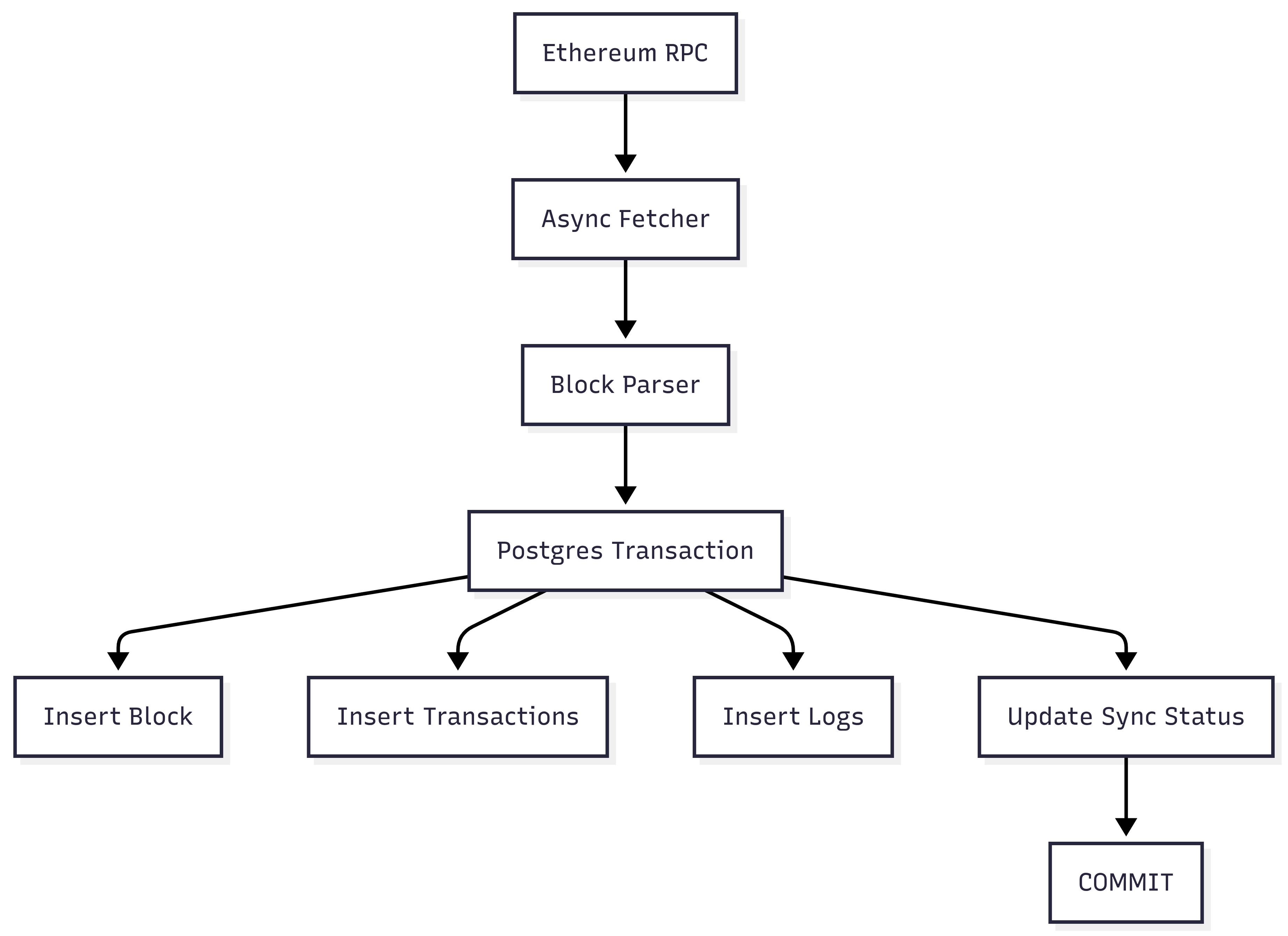
单个块的所有操作都在单个 PostgreSQL 事务中执行。
因此,要么 全部提交,要么 不保存任何内容——不存在部分状态。
原子块处理
核心模式如下:
let mut tx = pool.begin().await?;
store_block(&mut tx, &block).await?;
store_transactions(&mut tx, &block).await?;
store_logs(&mut tx, &block).await?;
update_checkpoint(&mut tx, block_number).await?;
tx.commit().await?;关键细节: 检查点更新在同一个事务中。
如果事务回滚:
- 区块不会被存储。
- 检查点不会移动。
恢复变得非常简单。
什么先坏了
最初,我在提交块数据之后更新检查点。它能工作——直到我模拟崩溃。
问题
如果进程崩溃:
- 块已被存储。
- 检查点未更新。
重启后系统会重新处理同一个块,导致:
- 重复插入尝试。
- 外键约束冲突。
- 恢复逻辑混乱。
修复
将检查点更新放入块事务内部。
现在:
- 提交保证块 + 检查点持久。
- 回滚保证什么也没发生。
- 重启逻辑变得确定性。
教训
恢复逻辑必须是写入路径的一部分,而不是事后考虑。
幂等性策略
崩溃、重试和 RPC 超时都会发生。系统必须能够安全地多次重试同一个区块。所有插入均使用:
INSERT ... ON CONFLICT DO NOTHING为什么这样可行
- 区块已存在 → 忽略插入。
- 交易已存在 → 忽略插入。
- 日志已存在 → 忽略插入。
调用 sync_block(N) 十次产生的状态与调用一次相同。
幂等性不是一种优化——它是生存的必需条件。
隔离级别考虑
PostgreSQL 默认使用 READ COMMITTED。对于这个索引器来说已经足够,因为:
- 块是顺序处理的。
- 没有并发写入者修改同一个块。
如果我并行化块的摄取,我会评估:
- 为了一致性使用
REPEATABLE READ,或者 - 显式的行级锁定,或者
- 分区写入。
原子性比单纯的速度更重要。
故障场景建模
| 场景 | 结果 |
|---|---|
| Crash before commit | 整个事务回滚;检查点保持不变。 |
| Crash after commit | 检查点已更新,区块变为完全持久。 |
| Duplicate processing | 安全,因为使用了 ON CONFLICT DO NOTHING。 |
| RPC timeout | 进行指数退避重试;幂等写入确保安全。 |
| Database lock contention | 事务范围保持最小;事务内部不进行外部 I/O。 |
设计原则: 每个区块同步必须是 原子 且 幂等 的。
运行时观察
| 指标 | 值 |
|---|---|
| 平均区块处理时间 | ~5 – 15 毫秒(受 RPC 限制) |
| 每个区块的数据库时间 | — 吞吐量(见下文注释) |
- 严格的每区块事务仅带来轻微的开销。
权衡
- 写入延迟略有提升
- 正确性保证大幅提升
在索引系统中,数据损坏比数据延迟更糟糕。
我接下来想改进的内容
- 使用受限工作池的并行历史同步
- 支持重组安全的回滚逻辑
- 分区块表
- 基于 WAL 的复制以实现读扩展
- 用于摄取延迟的 Prometheus 指标
经验教训
后端系统最难的不是性能——而是状态恢复。
将写入原子化的简化要点:
- 重试逻辑
- 崩溃恢复
- 对不变式的推理
帮助实现的关键工具:
- Rust – 在编译时强制正确性。
- PostgreSQL – 保证持久性。
- 事务 – 让系统保持一致。
该系统并未针对速度进行优化;它的优化目标是当出现问题时仍能保持正确。
这才是基础设施中最重要的。