Lakehouse 数据建模:有什么变化
Source: Dev.to

传统的数据建模假设你能够控制数据库。你预先定义模式,在写入时强制外键约束,并通过索引进行优化。Lakehouse 打破了这些假设的每一条。
数据以开放文件格式存储在对象存储中。模式可以在不重新写入数据的情况下演进。查询通过可能不强制关系约束的引擎运行。建模的原则相同,但实现方式不同。
湖仓有什么不同
湖仓将数据存储为文件——通常是 Parquet ——在对象存储上,如 S3 或 Azure Blob。
当你将此存储与像 Apache Iceberg 这样的开放表格式结合时,你将获得:
| 功能 | 描述 |
|---|---|
| 模式定义 | 集中式、版本控制的列定义。 |
| 分区元数据 | 无需手动文件系统技巧即可高效裁剪。 |
| 快照历史 | 时光旅行查询和轻松回滚。 |
| 事务保证 | 原子提交、隔离性以及写入者之间的一致性。 |
与传统关系型数据库相比有哪些变化?
- 写入时不强制 外键约束。
- 存储引擎不执行 触发器 或 存储过程。
- 必须在你的数据管道或视图中处理 参照完整性。
为什么这种权衡是值得的
- 开放格式 → 与供应商无关的数据,可被任何引擎读取。
- 引擎可移植性 → Spark、Dremio、Flink、Trino 等都可以查询相同的表。
- 低成本存储 → 对象存储比传统数据库使用的块存储便宜得多。
- 多计算 → 在不复制数据的情况下运行不同的工作负载(批处理、流处理、临时查询)。
Source: …
Schema‑on‑Read 改变规则
- 传统数据仓库(schema‑on‑write) – 在写入数据之前就定义好模式。每一行必须符合该模式,否则插入会失败。这保证了一致性,但使得更改代价高昂:添加列需要
ALTER TABLE;更改数据类型可能需要重写整个表。 - Lakehouse(schema‑on‑read) – 数据先被存储,结构在查询时才应用。Iceberg 原生支持模式演进,允许在不重写底层文件的情况下添加、重命名、扩宽或重新排序列。
建模影响
| 层级 | 目的 |
|---|---|
| Bronze | 从源头 原样 摄取数据。进行最小的类型标注,不 拒绝不符合刚性模式的记录。 |
| Silver | 通过 SQL 视图 应用业务逻辑、连接和类型强制。 |
| Gold | 提供可直接消费的 稳定、文档化的模式 数据集。 |
模型在 视图层 而非存储层演进,使得迭代更快、迁移成本更低。
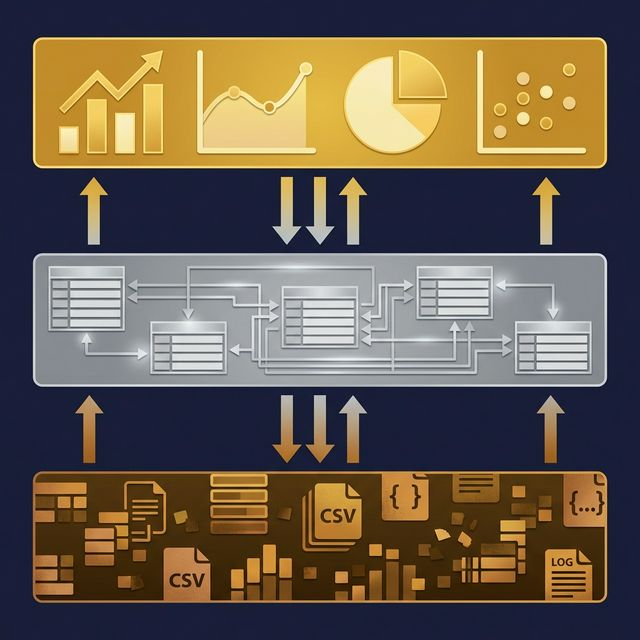
Medallion 架构作为建模模式
Medallion 架构(Bronze → Silver → Gold)是湖仓环境中最常见的数据建模模式。每一层都是一组 SQL 视图 或 受管表。
Bronze – 准备
- 将原始源数据映射到带类型的列。
- 重命名含糊不清的列名。
- 应用基本的数据类型转换。
- 为每个源表 创建一个视图。
Silver – 业务逻辑
- 关联相关实体(例如
orders+customers+products)。 - 应用业务规则(例如
revenue = quantity * price WHERE status = 'completed')。 - 过滤无效或重复的记录。
- 实现 逻辑数据模型。
Gold – 应用
- 为特定用例(执行仪表盘、销售报告、AI 代理上下文)定制视图。
- 最小化转换——主要从 Silver 视图中选择。
- 使用业务友好的名称和描述进行文档化。
在 Dremio 中,这些层被实现为 虚拟数据集(SQL 视图),并组织在 Spaces 中。每个视图:
- 使用 Wikis 进行文档化。
- 使用 Labels 进行标记。
- 通过细粒度 访问控制 进行治理。
因此,逻辑模型直接存在于平台中,而不是分散在 dbt 文件或部落知识中。
冰山表的物理建模
分区比索引更重要
Iceberg 依赖 partition pruning 而不是 B‑tree 索引。根据查询中最常使用的过滤条件选择分区列——通常是日期列。Iceberg 的隐藏分区意味着用户无需了解分区方案即可编写高效查询。排序顺序影响扫描性能
在每个分区内部,Iceberg 可以按指定列对数据进行排序。按经常被过滤的列(例如customer_id或region)进行排序,可实现最小/最大值裁剪,从而跳过不相关的文件。合并取代真空清理
流式插入会产生大量小文件。定期运行合并将这些小文件重写为更少的大文件,从而提升扫描性能。模式演进是非破坏性的
向 Iceberg 表添加列不会重写已有文件;旧文件对新列只返回NULL。这使得物理模型比传统数据库更具适应性。
Challenges to Watch For
No referential integrity enforcement.
Lakehouse 不会阻止你插入一个customer_id在customers表中不存在的订单。请在你的数据管道中构建数据质量检查。Schema drift across sources.
(此处继续描述…)
在 Bronze 层处理模式更改
当源系统意外更改其模式时,Bronze 层必须能够容忍新列或缺失列。请设计 Bronze 视图,以优雅地处理这些变化。
对视图的过度依赖
视图功能强大,但深度嵌套的视图链(例如 View D → View C → View B → View A)会带来性能和调试方面的挑战。尽可能将视图链保持在 不超过三层。
接下来该怎么做
如果您正从传统数据仓库迁移到湖仓,请从以下步骤开始:
- 重新创建 您最常用的表为 Iceberg 表。
- 转换 您最常用的转换为 SQL 视图。
- 组织 这些视图为 Bronze、Silver 和 Gold 层。
测量查询性能是否满足您的 SLA。如果不满足,请添加 Reflections 来优化繁重查询,而无需更改逻辑模型。