Claude Opus 4.6 面向开发者:Agent Teams、1M Context 与真正重要的
Source: Dev.to

TL;DR – 新增功能
| 功能 | 功能说明 | 为什么在乎 |
|---|---|---|
| 1 M 令牌上下文 | 一次性处理约 30 K 行代码 | 完整代码库的理解,而不仅是代码片段 |
| 代理团队 | 多个 Claude 实例并行工作 | 代码审查约 90 秒完成,而非约 30 分钟 |
| 自适应思考 | 四种努力级别(低 → 高) | 简单任务费用更低,复杂任务可深入 |
| 上下文压缩 | 自动汇总旧上下文 | 长时间会话不出现上下文衰减 |
| 128 K 输出令牌 | 输出量提升 4 倍 | 完整实现,而非截断片段 |
1. 代理团队(研究预览)
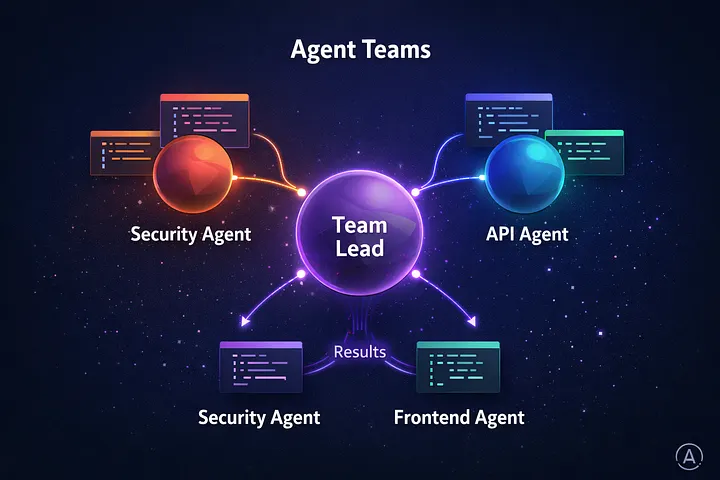
为什么重要 – 这是 Claude Code 用户的核心功能。
| 之前 | 之后 |
|---|---|
| 单一代理,顺序处理(例如,逐文件审查 PR) | 描述团队结构;Claude 会生成多个独立工作并相互协作的代理 |
如何启用
通过 settings.json
{
"experimental": {
"agentTeams": true
}
}或通过环境变量
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=true最佳使用场景
- 跨层次代码审查 – 安全代理 + API 代理 + 前端代理
- 调试竞争假设 – 每个代理并行测试不同的理论
- 跨多个服务的新功能 – 每个代理负责其所属领域
- 大规模重构 – 在模块之间分而治之
实际工作原理
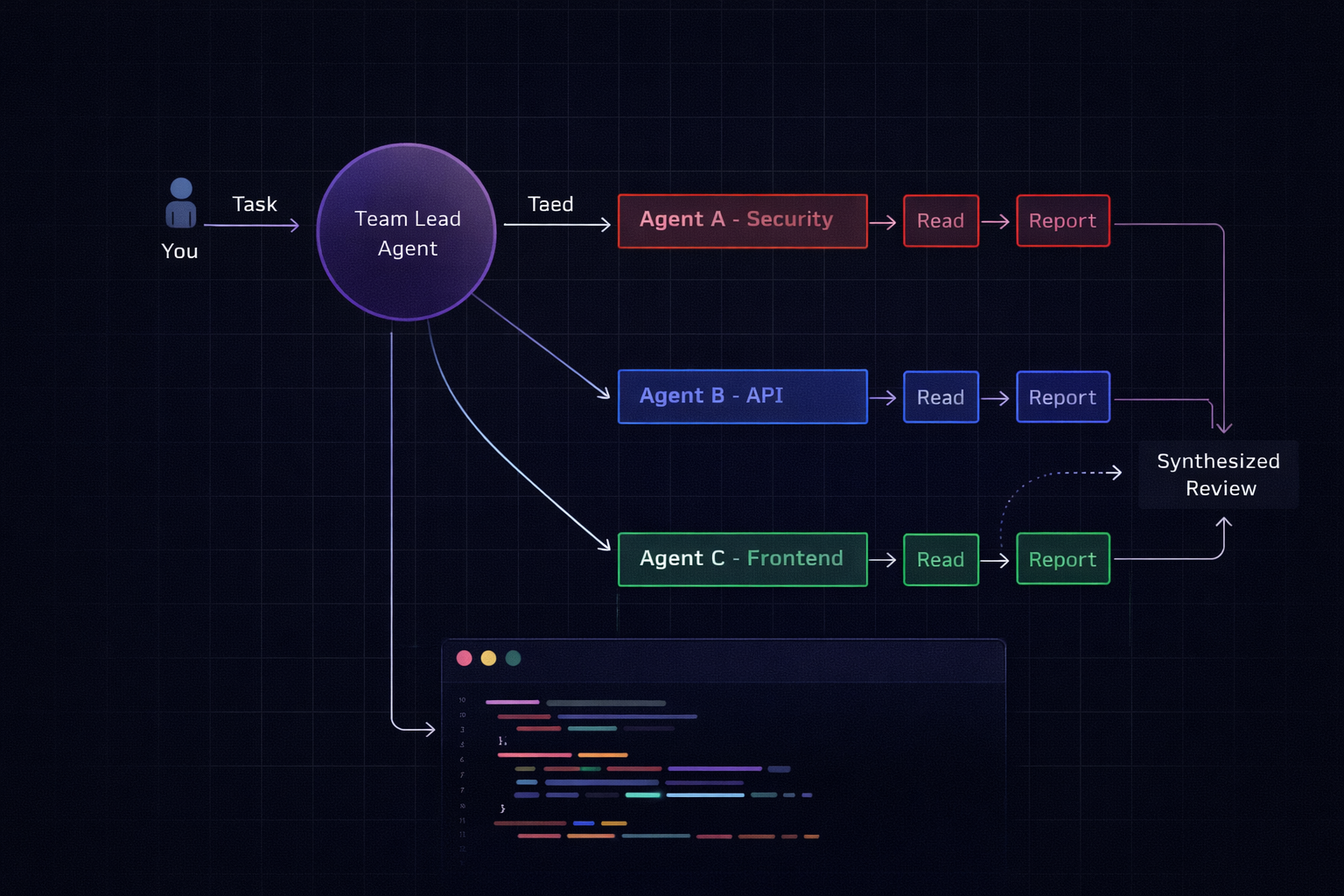
- 一个会话充当 团队负责人。
- 负责人 将任务拆分为子任务 并 生成队友会话(每个都有自己的上下文窗口)。
- 队友独立工作,并将结果回报给负责人。
- 负责人 综合这些发现。
你可以使用 Shift+↑/↓ 或通过 tmux 跳转到任意子代理。
小技巧:代理团队在阅读密集的任务上表现出色。对于写入密集、可能在同一文件上产生冲突的任务,单代理方式仍然更可靠。
2. 实际可用的 1 M Token 上下文窗口
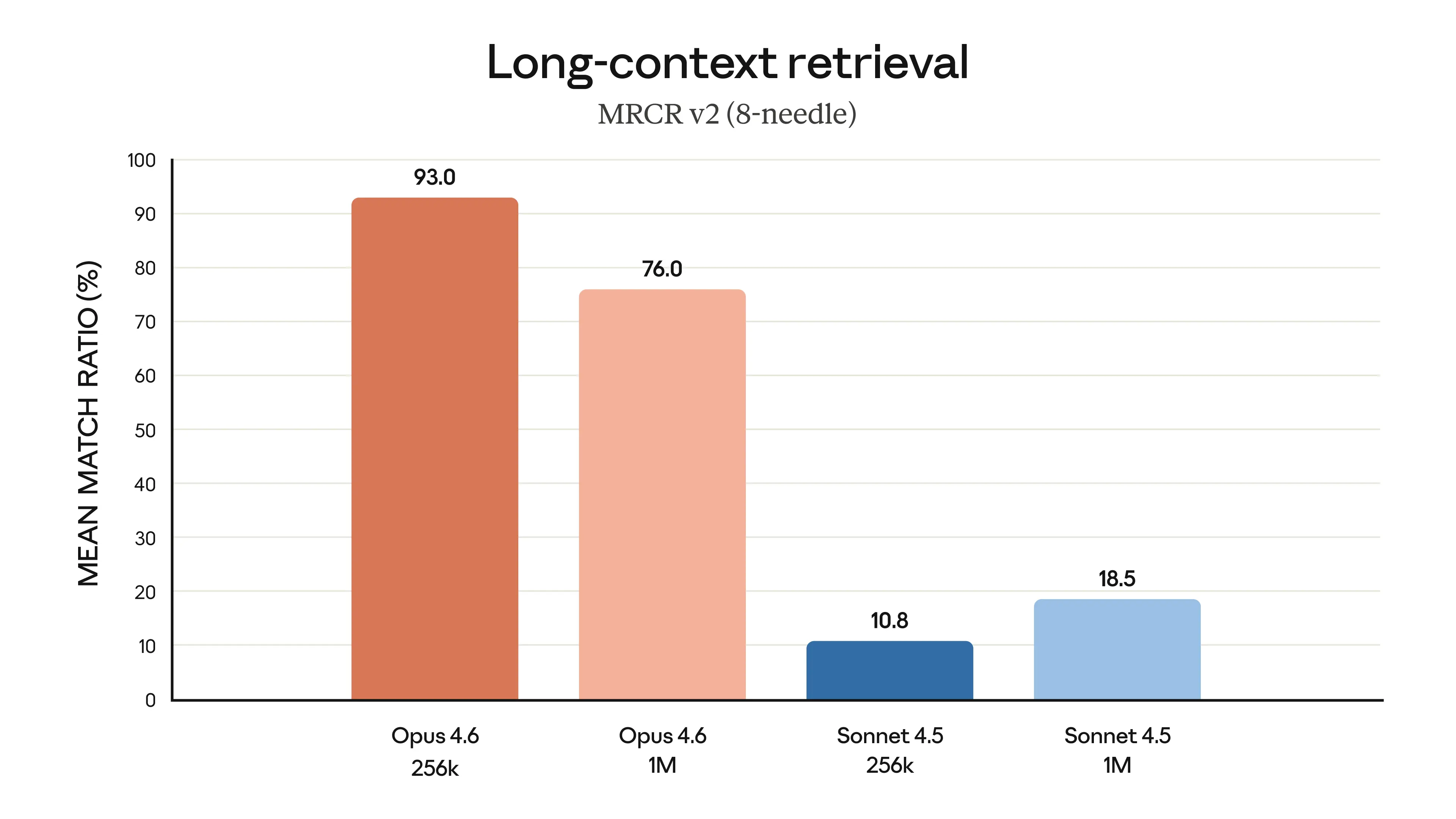
其他模型以前也有过大上下文窗口。这里的区别在于 检索质量。
Anthropic 的 MRCR v2 基准(衡量模型在海量上下文中查找并推理特定信息的能力)显示:
Opus 4.6 : 76.0% ████████████████████████████████████████
Sonnet 4.5: 18.5% ███这不仅仅是“更多 token”。它是模型记住上下文与忘记上下文之间的差别。
这如何改变你的日常工作流程
| 任务 | 之前(≈200 K token) | 之后(≈1 M token) |
|---|---|---|
| Bug 追踪 | 逐个文件喂入,重新解释架构 | “从队列到 API 追踪 bug” – 能看到全部内容 |
| 代码审查 | 自己概括 PR | 喂入整个 diff + 周边代码 |
| 新功能 | 在提示中描述代码库 | 让模型直接读取整个代码库 |
| 重构 | 大约 15 个文件后失去上下文 | 所有 47 个文件在同一会话中保持上下文 |
实际示例
# 将整个服务加载到 Claude Code
cat src/**/*.ts | wc -l
# → 28 000 行 – 完全可以放入 1 M token 窗口
# 要求 Claude 在完整代码库中追踪 bug
> "The /api/tasks endpoint sometimes returns stale data.
> Trace the data flow from the queue processor through
> the cache layer to the API response handler."定价说明: 标准定价(每百万输入/输出 token $5 / $25)适用于 200 K token 以内。超过该量后,将使用高级定价 $10 / $37.50。对大多数开发工作流而言,你仍会保持在 200 K token 以下。
3. 自适应思考与努力级别

Claude Opus 4.6 引入了四个努力级别(低 → 最大)。模型会自动选择能够满足请求的最便宜级别,但在需要更深入推理或更彻底的代码生成时,你可以强制使用更高的级别。
| 努力级别 | 典型使用场景 | 成本影响 |
|---|---|---|
| 低 | 简单查询,单行修复 | 最低 |
| 中等 | 常规重构,标准 PR 审核 | 中等 |
| 高 | 复杂的架构变更,多服务调试 | 较高 |
| 最大 | 全栈功能实现,全面测试脚手架 | 最高 |
如何控制努力
在 settings.json 中
{
"defaultEffort": "medium", // low | medium | high | max
"allowEffortOverride": true // let the UI expose a selector
}在提示中内联
@effort=high
Please generate a complete CRUD module for the `Task` entity, including validation, service layer, and unit tests.何时使用每个级别
| 情境 | 推荐努力 |
|---|---|
| 快速拼写错误修复或单行代码 | 低 |
| 标准代码审查或 lint | 中等 |
| 跨服务错误排查,性能分析 | 高 |
| 端到端功能脚手架,设计层面推理 | 最大 |
结论
- Agent Teams 让您并行处理读取密集型工作,并保持每个子任务的上下文整洁。
- 1 M‑token 上下文 意味着您可以将整个仓库交给 Claude,让它进行整体推理。
- 自适应努力级别 为您提供细粒度的成本控制,在需要时不牺牲深度。
如果您已经在使用 Claude Code,请启用实验性标志,开始向模型提供更大块的代码库,让模型自行决定使用多少“思考”能力。您的日常开发工作流将变得更快、更省钱,且不再缺乏上下文。
新 API 参数:thinking.budget_tokens(结合努力等级)
// 快速重命名 – 不要想太多
const response = await anthropic.messages.create({
model: "claude-opus-4-6",
thinking: { type: "enabled", effort: "low" },
messages: [{ role: "user", content: "Rename userId to accountId across this module" }]
});
// 复杂的架构决策 – 深入思考
const response = await anthropic.messages.create({
model: "claude-opus-4-6",
thinking: { type: "enabled", effort: "max" },
messages: [{ role: "user", content: "Design the migration strategy for moving from REST to GraphQL" }]
});努力等级
| 等级 | 描述 |
|---|---|
low | 最小推理;快速且廉价。 |
medium | 推理与成本的平衡。 |
high | 默认等级;彻底但高效。 |
max | 完全推理;最高质量。 |
自适应模式
当 thinking.type 设置为 adaptive 时,模型会自动选择合适的努力等级:
- 简单问题 → 快速、低成本的答案。
- 复杂推理 → 完整处理的响应。
为什么这对成本很重要
在生产环境中运行 AI 驱动的工具时,并不需要每个请求都使用最高智能。通过利用自适应思考,你可以:
- 将琐碎查询路由到更快、更便宜的模型。
- 为高需求任务保留最强大的模型(例如 Opus)。
我们在 Glinr 中采用了这种模式,动态地将简单查询路由到轻量模型,将复杂工作委派给 Opus。自适应思考将这种路由逻辑直接嵌入模型,降低了延迟和成本。
4. Context Compaction (Beta)
const response = await anthropic.messages.create({
model: "claude-opus-4-6",
context_compaction: { enabled: true },
// ... long conversation history
});为什么重要
- 如果不进行压缩,2 小时的重构会超出任何上下文限制。
- 通过压缩,模型会保留 摘要 形式的早期工作,同时对最近的回合保持完整细节。
- 可以把它想象成对话历史的
git squash。
5. Benchmarks That Matter for Developers
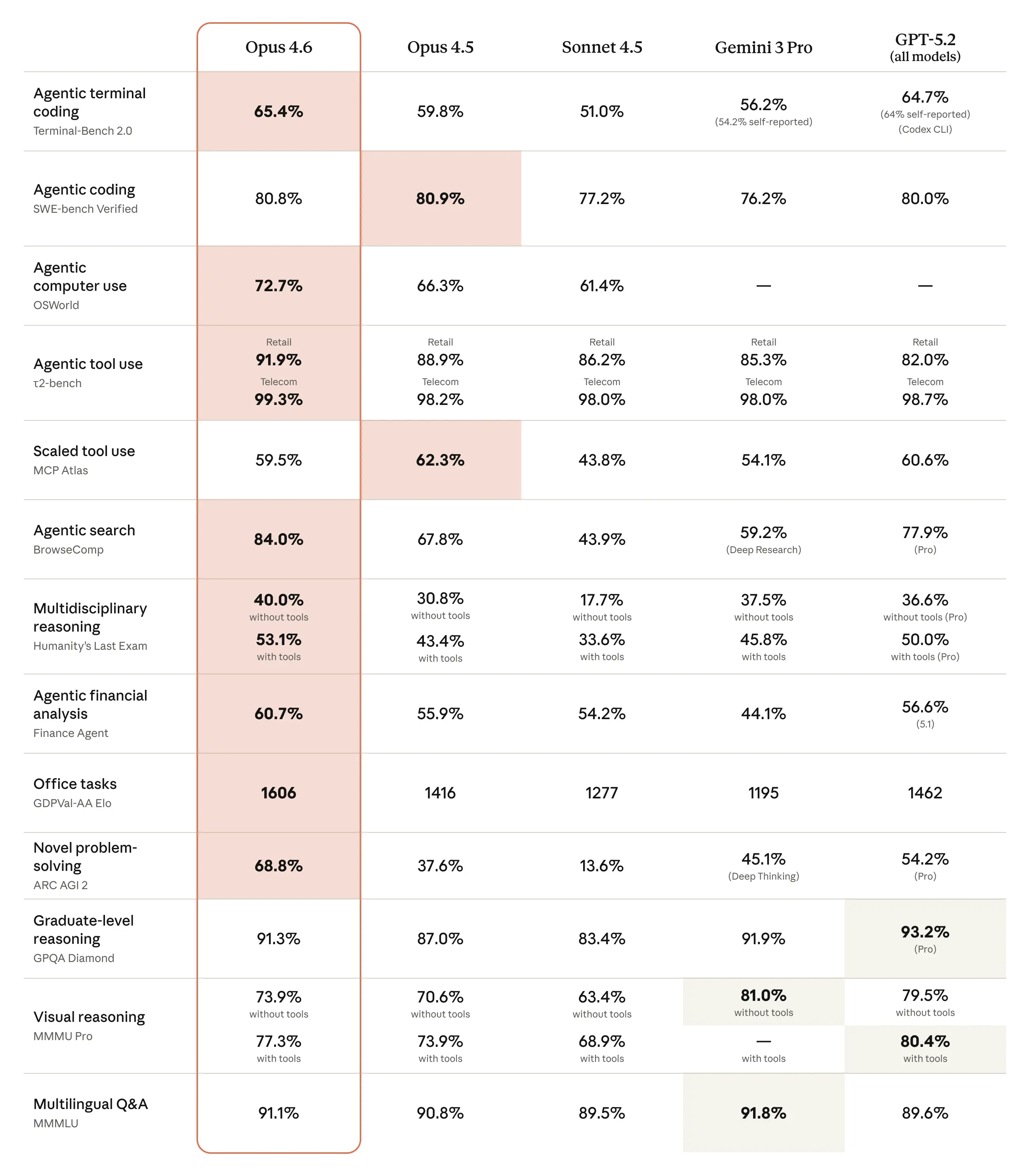
跳过学术基准。以下才是写代码时真正重要的:
| Benchmark | Opus 4.6 | Opus 4.5 | 测试内容 |
|---|---|---|---|
| Terminal‑Bench 2.0 | 65.4 % | 59.8 % | 实际代理式编码任务 |
| SWE‑bench Verified | 80.8 % | ~72 % | 解决真实的 GitHub 问题 |
| MRCR v2 (1 M) | 76.0 % | N/A | 长上下文检索 |
| HLE | #1 | – | 最难的推理问题 |
Terminal‑Bench 分数尤为重要。它衡量模型在拥有完整终端环境时的表现——运行测试、调试和迭代。65.4 % 的成功率意味着模型能够自主解决近三分之二的复杂编码任务。
6. 安全性:发现 500 + 零日漏洞
在发布前,Anthropic 的团队使用 Opus 4.6 对开源代码库进行漏洞搜寻。扫描发现了 500 + 之前未知的零日漏洞,从简单的崩溃错误到严重的内存损坏缺陷不等。在一个显著案例中,Claude 自动生成了概念验证 exploit 以验证该发现。
关键要点
- AI 能发现数百个传统测试遗漏的关键漏洞。
- 自动化的概念验证生成加快了验证和修复的速度。
- 将 AI 用于安全审计代表了我们保护软件方式的重大变革。
如果你在使用 AI 进行安全审计,这是一场颠覆性的变革。
关键要点
Opus 4.6 并非边际升级。以下组合:
- 实际有效的上下文 – 1 M token,检索准确率 76 %
- 并行代理团队 – 分而治之
- 自适应投入 – 按需付费
- 上下文压缩 – 会话可持续数小时,而非数分钟
…打造出一种质的不同的工具。它不再是“AI 自动补全”,而更像是“AI 开发团队”。
该模型现已通过 API 中的 claude-opus-4-6、Claude Code 和 claude.ai 提供。
我们正在将 Opus 4.6 的能力集成到 Glinr —— 一个智能在模型之间路由、管理多代理工作流并跟踪从工单到部署的所有内容的 AI 任务编排平台。如果你正在构建 AI 驱动的开发工具,欢迎交流。
Tags: ai, webdev, programming, productivity, Claude4.6, GLINR
关注并点赞以获取更多内容
- Medium –
- LinkedIn –
- Site –