在 AWS 上构建“不可阻挡”的 Serverless 支付系统(Circuit Breaker 模式)
发布: (2025年12月13日 GMT+8 18:30)
5 min read
原文: Dev.to
Source: Dev.to
当你的支付网关宕机时会发生什么?在传统应用中,用户会看到加载动画,随后出现 “500 Server Error”,而你则失去这笔交易。
我想构建一个永不崩溃的系统。即使后端数据库“着火”,用户的订单也应被接受、排队,并在系统恢复后自动处理。
技术栈
- 前端:Python(Streamlit)– 商店 & 管理仪表盘。
- 编排:AWS Step Functions – 处理业务逻辑的 “大脑”。
- 计算:AWS Lambda(Java 11)– 执行业务逻辑的 “工作者”。
- 状态存储:Amazon DynamoDB – 存储断路器状态(Open/Closed)和订单历史。
- 弹性:Amazon SQS – 用于失败订单的 “停车场”。
- 可观测性:Grafana Cloud(Loki)– 日志聚合。
- 基础设施:Terraform – 完整的 IaC。
注意: 使用 Terraform 管理资源。最佳实践是将所有资源分散到不同文件中,以便创建、删除或进行任何类型的更新。
问题:级联故障
在微服务架构中,如果服务 A 调用服务 B,而服务 B 卡住,服务 A 最终也会卡住。大量的 “支付” 点击会让数据库在重试时被压垮,等同于对自己进行 DDoS 攻击。
解决方案: 断路器(Circuit Breaker)—— 类似家庭电路的断路器,在电流激增时跳闸,以保护系统。
高层架构
系统处理三种不同的状态:
| 路径 | 描述 |
|---|---|
| 绿色(Closed) | 后端健康,订单立即处理。 |
| 红色(Open) | 后端崩溃,断路器跳闸,流量不再到达后端。 |
| 黄色(Recovery) | 订单被路由到 SQS 队列,稍后自动重试。 |
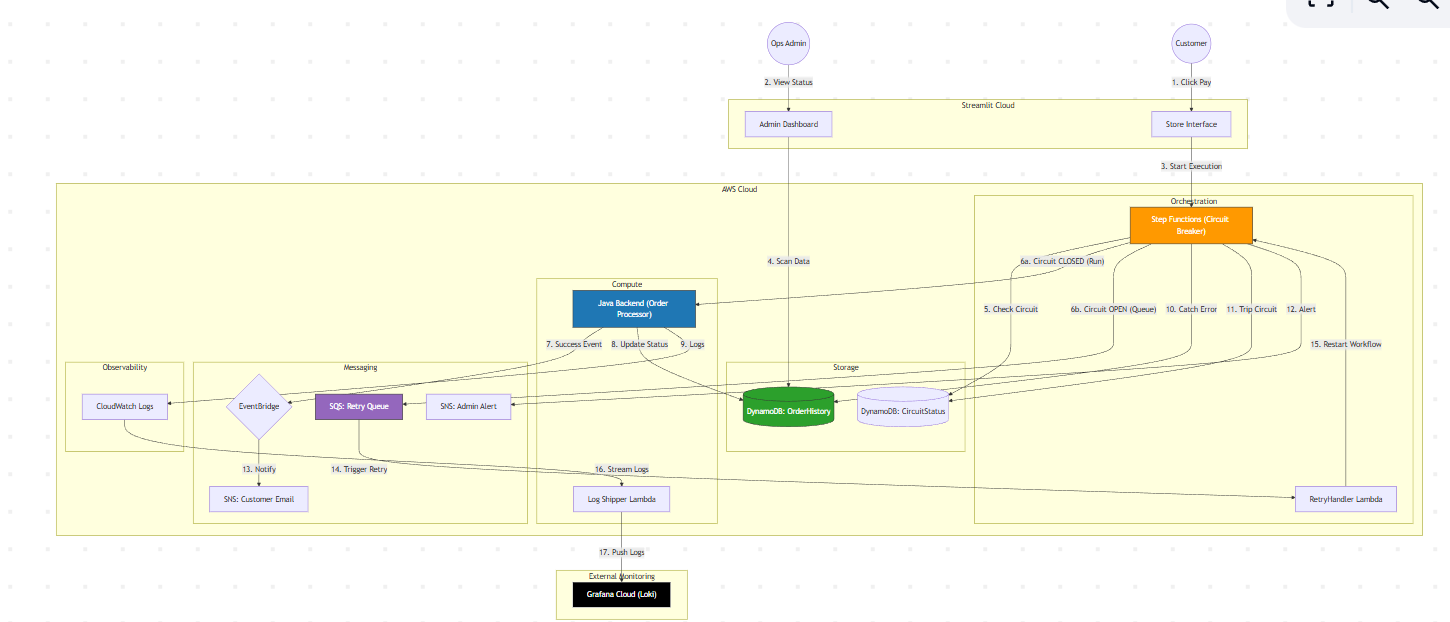
逻辑流程
核心是一个 AWS Step Functions 状态机,充当流量控制器。
-
检查 – 每一次 “支付” 点击,工作流都会查询 DynamoDB 中的断路器状态。
- 若为 OPEN,则跳过后端。
- 若为 CLOSED,则继续调用 Java Lambda。
-
执行 – Lambda 处理支付。
- 成功:将订单历史更新为 COMPLETED 并触发 EventBridge 事件(通过 SNS 发送客户邮件)。
- 失败:捕获错误并使用指数退避重试(等待 1 秒,然后 2 秒)。
-
“跳闸” – 若后端持续失败,状态机会:
- 将状态写为 OPEN 到 DynamoDB。
- 通过 SNS 向系统管理员发送警报(“Critical: Circuit Tripped”)。
- 在仪表盘中将订单标记为 FAILED。
-
自愈(自动重试) – 当断路器为 OPEN 时,新订单被标记为 QUEUED 并发送到 Amazon SQS。
- “重试处理器” Lambda 监听队列,等待(例如 30 秒),然后重新提交订单到状态机。
- 若后端已修复,订单即可处理;否则再次返回队列。
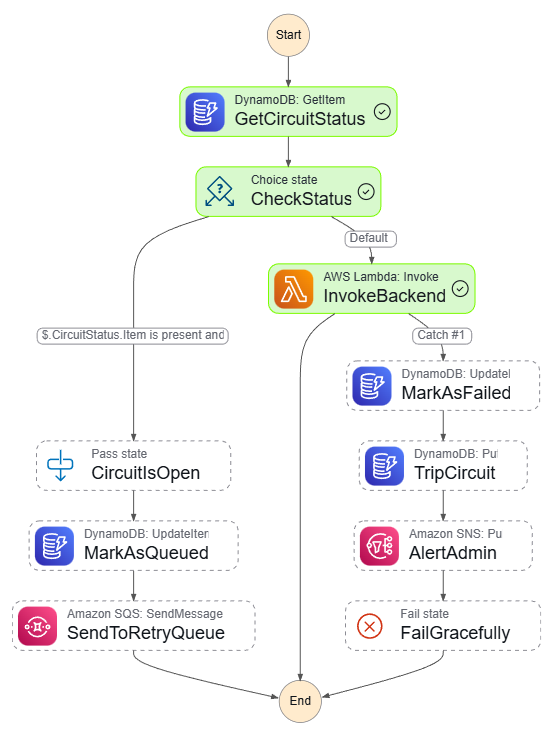
低层图

测试数据场景
成功
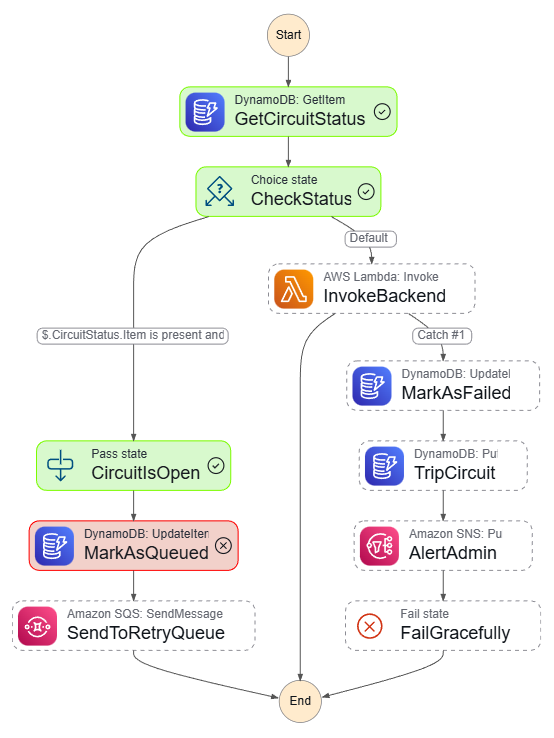
混沌模式
可观测性与监控
- 集成 Grafana Cloud(Loki),从 CloudWatch 采集日志。
- Streamlit 仪表盘 实时显示订单状态(PENDING → COMPLETED 或 FAILED)。
- Grafana Explore 支持深度日志检索,例如
{service="order-processor"}用于定位特定堆栈信息。
关键收获与权衡
| 方面 | 见解 |
|---|---|
| 复杂度 vs. 可靠性 | 更多的组件(队列、状态机)会提升系统复杂度,但能实现高可用;前端永远不会看到崩溃。 |
| “幽灵”数据 | 捕获块会用错误信息替换原始输入。使用 ResultPath 可以保留原始订单 ID,以便在失败后仍能更新数据库。 |
| 成本优化 | 标准 Step Functions 工作流在大规模时成本较高。切换到 Express Workflows 并使用 ARM64(Graviton) Lambda 可将成本降低约 40%。 |
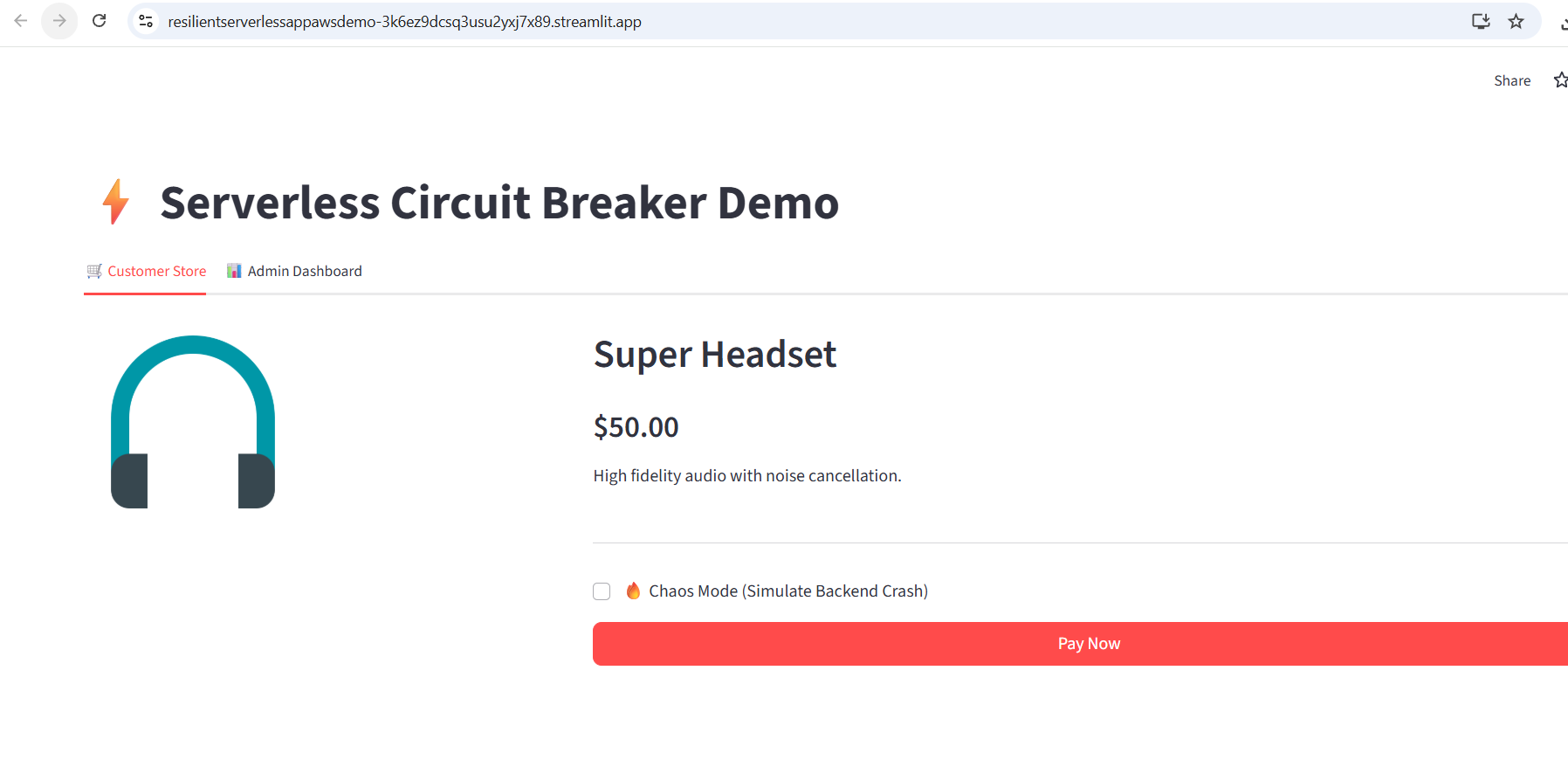
应用截图
下单 UI
管理 UI

结论
本项目展示了事件驱动架构结合断路器模式,如何构建能够优雅降级的系统。系统在崩溃期间不会失去收入,而是将流量“暂停”,待风暴过去后再继续处理。
使用的技术: AWS、Java、Python、Terraform、Grafana.