超越 FFI:使用 Rust 与无锁环形缓冲区实现零拷贝 IPC
Source: Dev.to


作者: Rafael Calderon Robles | LinkedIn
1. 调用成本神话:编组与运行时
人们常误以为开销仅来自 CALL 指令。 在现代环境(例如 Python/Node.js → Rust)中,真正的“税收”在三个不同的检查点产生:
| 检查点 | 发生了什么 |
|---|---|
编组 / 序列化 (O(n)) | 将 JS 对象或 Python dict 转换为 C 兼容的结构(连续内存)。 这会在 Rust 甚至触及字节之前就消耗 CPU 周期并污染 L1 缓存。 |
| 运行时开销 | Python 必须释放并重新获取 GIL;Node.js 跨越 V8/Libuv 屏障会产生昂贵的上下文切换。 |
| 缓存抖动 | 在 GC 管理的堆和 Rust 栈之间跳转会破坏数据局部性。 |
如果你每秒处理 10 万条消息,CPU 花在跨边界复制字节的时间会超过执行业务逻辑的时间。

Source: …
2. 解决方案:基于共享内存的 SPSC 架构
另一种方案是使用 无锁环形缓冲区 放在共享内存段(mmap)中。我们建立一个 SPSC(单生产者单消费者) 协议,由主机写入、Rust 读取,热路径上没有系统调用或互斥锁。
缓存对齐环形缓冲区的结构
在生产环境中运行且不触发未定义行为(UB),必须严格控制内存布局。
use std::sync::atomic::{AtomicUsize, Ordering};
use std::cell::UnsafeCell;
// Design constants
const BUFFER_SIZE: usize = 1024;
// 128 bytes to cover both x86 (64 bytes) and Apple Silicon (128 bytes pair‑prefetch)
const CACHE_LINE: usize = 128;
// GOLDEN RULE: Msg must be POD (Plain Old Data).
// Forbidden: String, Vec, or raw pointers. Only fixed arrays and primitives.
#[repr(C)]
#[derive(Copy, Clone)] // Guarantees bitwise copy
pub struct Msg {
pub id: u64,
pub price: f64,
pub quantity: u32,
pub symbol: [u8; 8], // Fixed‑size byte array for symbols
}
#[repr(C)]
pub struct SharedRingBuffer {
// Producer isolation (Host)
// Initial padding to avoid adjacent hardware prefetching
_pad0: [u8; CACHE_LINE],
pub head: AtomicUsize, // Write: Host, Read: Rust
// Consumer isolation (Rust)
// This padding is CRITICAL to prevent false sharing
_pad1: [u8; CACHE_LINE - std::mem::size_of::()],
pub tail: AtomicUsize, // Write: Rust, Read: Host
_pad2: [u8; CACHE_LINE - std::mem::size_of::()],
// Data: Wrapped in UnsafeCell because Rust cannot guarantee
// the Host isn’t writing here (even if the protocol prevents it).
pub data: [UnsafeCell; BUFFER_SIZE],
}
// Note: In production, use #[repr(align(128))] instead of manual arrays
// for better portability, but manual padding illustrates the concept here.
3. 协议:Acquire/Release 语义
忘掉 mutexes——使用 memory barriers。
-
Producer (Host):
- 将消息写入
data[head % BUFFER_SIZE]。 - 以 Release 语义递增
head。
这保证了数据写入在索引更新被观察到之前是可见的。
- 将消息写入
-
Consumer (Rust):
- 以 Acquire 语义读取
head。 - 如果
head != tail,读取数据后递增tail。
- 以 Acquire 语义读取
同步是硬件原生的;不需要操作系统介入。
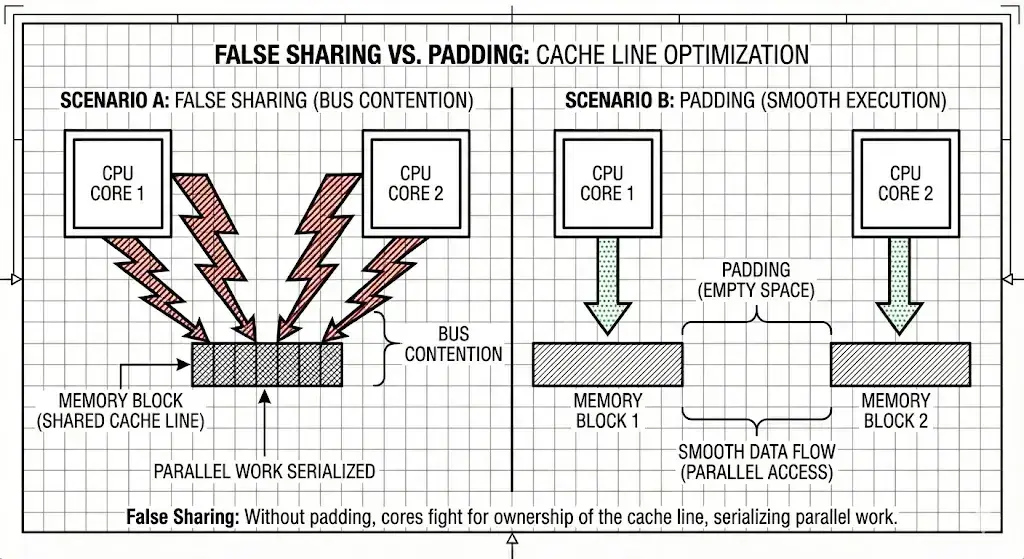
4. 机械亲和性与伪共享
如果忽视硬件,吞吐量会崩溃。伪共享发生在 head 和 tail 位于同一缓存行时。
Core 1(例如 Python)更新 head → 整个缓存行被失效。
Core 2(Rust)随后读取 tail(同一行) → 必须等待缓存行通过 MESI 协议同步后才能继续。这可能导致性能下降一个数量级。
解决方案: 在两个原子变量之间强制至少 128 字节(填充)的物理分离,如上面的结构所示。
5. 等待策略:不要烧毁服务器
无限循环 (while true) 会占用 100 % 的 CPU 核心,这在云环境或电池供电的设备上是不可接受的。
正确的策略是 Hybrid:
- Busy Spin (≈ 50 µs): 调用
std::thread::yield_now()。将执行权让给操作系统,但保持“热”状态。 - Park/Wait (Idle): 如果在 X 次尝试后仍未收到数据,使用轻量级阻塞原语(例如 Linux 上的
Futex或Condvar)让线程休眠,直到收到信号。
// Simplified Hybrid Consumption Example
loop {
let current_head = ring.head.load(Ordering::Acquire);
let current_tail = ring.tail.load(Ordering::Relaxed);
if current_head != current_tail {
// 1. Calculate offset and access memory (unsafe required due to FFI nature)
let idx = current_tail % BUFFER_SIZE;
let msg_ptr = ring.data[idx].get();
// Volatile read prevents the compiler from caching the value in registers
let msg = unsafe { ptr::read_volatile(msg_ptr) };
process(msg);
ring.tail.store(current_tail + 1, Ordering::Release);
} else {
// Backoff / Hybrid Wait strategy
spin_wait.spin();
}
}6. 指针陷阱:真正的零拷贝
“Zero‑Copy” 在此情境下有细则。
警告: 切勿在
Msg结构体中传递指针(Box、&str、Vec)。
Rust 进程和宿主进程(Python/Node)拥有不同的虚拟地址空间。像 0x7ffee… 这样的指针在 Node 中是有效的,但在 Rust 中是垃圾(并且很可能导致段错误)。
你必须 扁平化 数据。如果需要发送可变长度的文本,请使用固定缓冲区([u8; 256])或实现一个专用于字符串 slab 分配器的次级环形缓冲区,但保持主结构扁平(POD)。
结论
实现共享内存环形缓冲区将 Rust 从“快速库”转变为异步协处理器。我们消除了编组成本,实现的吞吐量几乎仅受 RAM 带宽限制。
然而,这会增加复杂性:你需要手动管理内存,必须将结构体对齐到缓存行,并且必须在没有编译器帮助的情况下防止竞争条件。仅在标准 FFI 明显成为瓶颈时才使用此架构。
Tags: #rust #performance #ipc #lock‑free #systems‑programming
进一步阅读