使用 Azure Functions(Python)自动化 EL pipeline
发布: (2025年12月9日 GMT+8 21:45)
4 分钟阅读
原文: Dev.to
Source: Dev.to
Problem & Context
作为数据工程师,我负责在不同存储位置之间移动数据。原有的做法是在每个 ADF pipeline 上使用触发器,当有新 blob 创建时就启动一次复制。该方案既不高效,也不具备可扩展性,且难以维护。我需要一种可复现、简洁、快速且可扩展的架构,于是选择了 Azure Functions 方案。
Architecture at a Glance
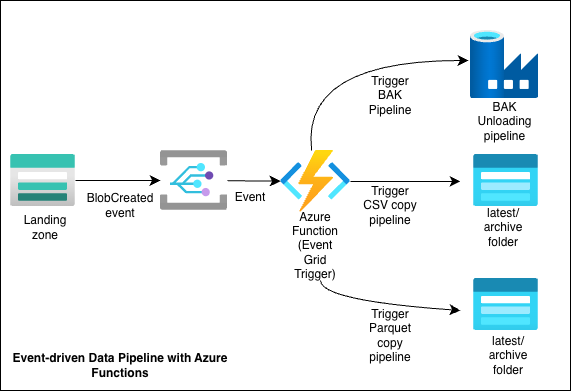
- 新文件被上传到源 Storage Account。
- Event Grid 触发 BlobCreated 事件。
- Azure Function(Python,Event Grid 触发器)接收该事件。
- 函数执行以下操作:
- 解析事件负载以识别容器/blob。
- 使用环境变量确定数据来源(origin)以及后续步骤。
- 触发相应的 pipeline。
- pipeline 执行,将文件复制到目标 Storage Account 中的相应文件夹,或调用 ADF pipeline。
单个 Azure Function App 托管多个函数(共 4 个):
- 2 个用于复制 CSV 文件的函数
- 1 个用于 Apache Parquet 文件传输的函数
- 1 个用于触发处理 SQL Bak 文件的 ADF pipeline 的函数
每个函数都与接收其对应文件类型的存储容器关联,确保运行正确的 pipeline。
Config & Environment Variables
为了避免硬编码存储路径和 pipeline 名称,大部分配置都存放在 Function App 的 Application Settings(环境变量)中,例如:
- 源容器
- 目标文件夹(如
latest、archive) - 针对特定 “origin” 调用的 ADF pipeline
这种做法便于:
- 支持多个数据源
- 在不同环境(dev / test / prod)之间推广解决方案
- 在不重新部署代码的情况下更新目标位置
示例: 对于 CSV 源 Alderhey,变量命名为 Alderhey_1_destination_folder、Alderhey_1_destination_storage_account 等,其他目标也采用类似模式。
Auth & Networking
身份验证通过 Azure AD 应用注册实现,凭据存放在环境变量中。该应用被授予以下角色:
- 对相关存储账户的 Storage Blob Data Contributor
- 对 ADF 实例的 Data Factory Contributor
根据实际环境,还可能需要配置:
- Function App 的 VNet 集成
- Storage 和 Data Factory 的私有端点
- 允许 Event Grid → Function、Function → Storage/ADF 流量的防火墙规则
这些网络设置常常是 “在我的机器上可以工作” 问题的根源,请逐步测试连通性。
How to Deploy
- 在所选区域创建一个 Azure Function App(Python 运行时)。
- 通过 VS Code 或 Azure DevOps/GitHub Actions 部署函数代码。
- 配置 Application Settings(环境变量),包括:
- 源/目标存储详情
- pipeline 名称 / 资源 ID
- 创建 App Registration 并分配所需角色。
- 在你的 Storage Account 上创建针对 BlobCreated 事件的 Event Grid 订阅,指向 Function 端点。
- 上传测试文件,验证 pipeline 是否运行并将数据写入预期位置。
Lesson Learned
本项目展示了如何利用 Azure Functions 实现 EL pipeline,代码量极少、可复用性高且实现全自动。该方案可在不同环境、租户以及新增目标之间迁移。如果你正在使用 Azure Functions、Event Grid 或 ADF 并希望交流想法,欢迎联系。
Full code: My Github
Connect with me on LinkedIn: Nafisah Badmos