Agent Factory 回顾:深入探讨 Agent 评估、实用工具和多代理系统
抱歉,我需要您提供要翻译的具体文本内容才能进行翻译。请把文章的正文粘贴在这里,我会按照您的要求保留来源链接、格式和技术术语,并将内容翻译成简体中文。
Source:
解构代理评估
超越单元测试:为何代理评估不同
时间戳: 02:20
评估一个代理与传统软件测试在本质上有所不同。
- 传统软件测试 是确定性的;相同的输入总会产生相同的输出(A = B)。
- 大语言模型评估 类似于学校考试:通过问答对来探查静态知识,以判断模型是否“知道”某些内容。
- 代理评估 更像是工作绩效评审。我们评估一个复杂系统的行为——包括自主性、推理、工具使用以及对不可预测情境的处理。由于代理是非确定性的,同一提示可能产生不同的——但同样有效——结果。

全栈方法:要衡量什么
时间戳: 04:15
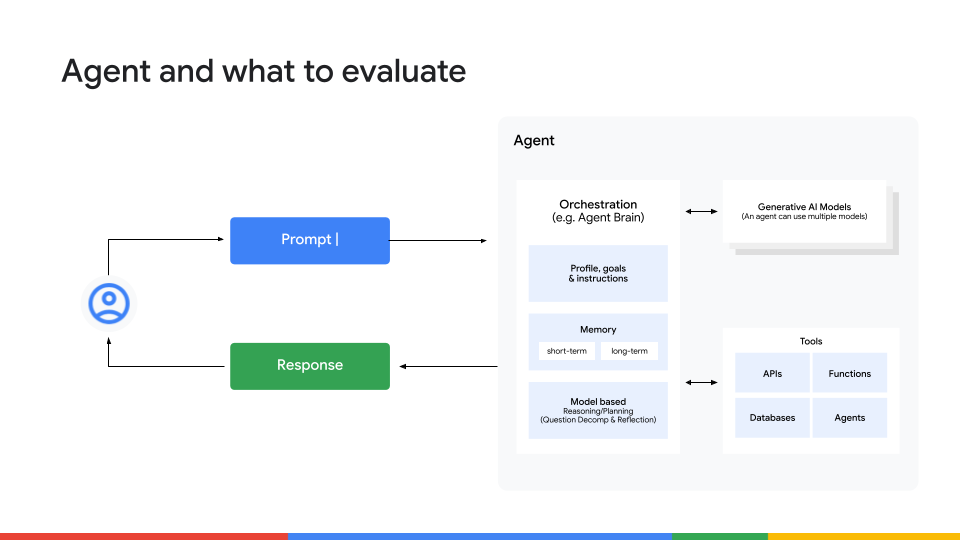
如果我们不只关注最终输出,我们应该衡量什么?简短的答案是全部。我们需要一种全栈方法,检查代理行为的四个关键层面:
-
最终结果 – 代理是否达成了目标?
除了简单的通过/未通过,还要考虑质量、连贯性、准确性、安全性以及避免幻觉。 -
思考链(推理) – 代理是如何得出答案的?
验证它是否将任务拆解为逻辑步骤,以及其推理是否一致。仅凭运气得到正确答案的代理并不可靠。 -
工具使用 – 代理是否选择了正确的工具并传递了正确的参数?
评估效率,并留意代价高昂、冗余的 API 调用循环。 -
记忆与上下文保持 – 代理能否在需要时回忆对话早期的信息?
如果新信息与已有知识冲突,代理能否正确解决冲突?
如何衡量:真实标签、LLM‑as‑a‑Judge 与 人类在环
时间戳: 06:43
一旦明确了要衡量什么,下一个问题就是怎么衡量。下面列出三种常用方法,各有优缺点:
| 方法 | 优势 | 局限性 |
|---|---|---|
| 真实标签检查 | • 快速、低成本 • 对客观指标可靠(例如“这是否是有效的 JSON?”或“格式是否符合模式?”) | • 无法捕捉细微差别或主观质量 |
| LLM‑as‑a‑Judge | • 可大规模扩展 • 能对计划连贯性等主观质量进行打分 | • 判决会继承模型的训练偏见,且可能不一致 |
| 人类在环 | • 金标准准确性 • 捕捉细微差别和领域专长 | • 速度慢且成本高 |
关键要点
不要只依赖单一方法。将它们结合在校准循环中:
- 创建黄金数据集——让人类专家生成一小批高质量的标注示例。
- 微调 LLM‑as‑a‑Judge 在该数据集上,直至其评分与人类评审保持一致。
- 部署已校准的评审模型,用于大规模自动评估。
这种方法让你在自动化规模下获得人类水平的准确性。
工厂车间:5 步评估代理
Factory Floor 部分从宏观概念转向使用 Agent Development Kit (ADK) 的实操演示。
实操:使用 ADK 的 5 步代理评估循环
时间戳: 08:41
ADK Web UI 非常适合在开发过程中进行快速、交互式测试。下面是我们用来调试一个错误使用工具的简单产品调研代理的五步“内部循环”工作流。
-
测试并定义“黄金路径”。
- 提示:
Tell me about the A‑phones. - 代理返回了错误信息(内部 SKU 而不是客户描述)。
- 我们在 Eval 选项卡中纠正了响应,创建了第一个“黄金”测试用例。

- 提示:
-
在黄金测试上运行代理。
- 在 Run 选项卡中执行测试。
- 验证输出现在是否符合预期描述。
-
添加边缘案例测试。
- 引入提示的变体(例如,不同的产品名称、模糊查询)。
- 在 Eval 选项卡中记录预期结果。
-
迭代提示 / 工具选择。
- 根据失败情况调整代理的提示或工具选择逻辑。
- 重新运行完整测试套件,以捕获回归问题。
-
自动化循环。
- 将测试套件导出到 CI 流水线。
- 使用 ADK 的 CLI 在每次提交时自动运行评估。
评估工作流(含截图)
-
评估并识别失败
保存测试用例后,我们运行了评估。正如预期的那样,它立即失败。
-
查找根本原因
我们打开了 Trace view,它显示了代理的逐步推理过程。很快就发现代理选择了错误的工具(lookup_product_information而不是get_product_details)。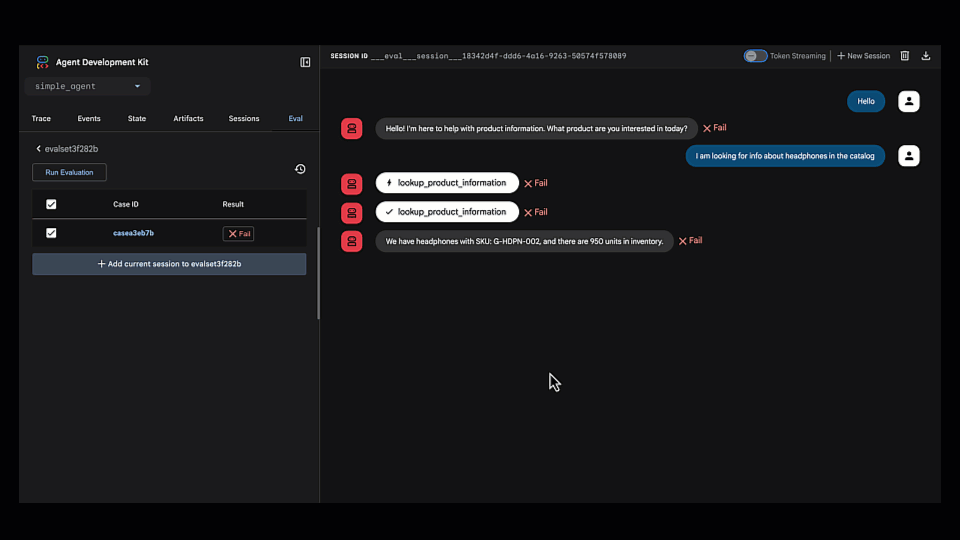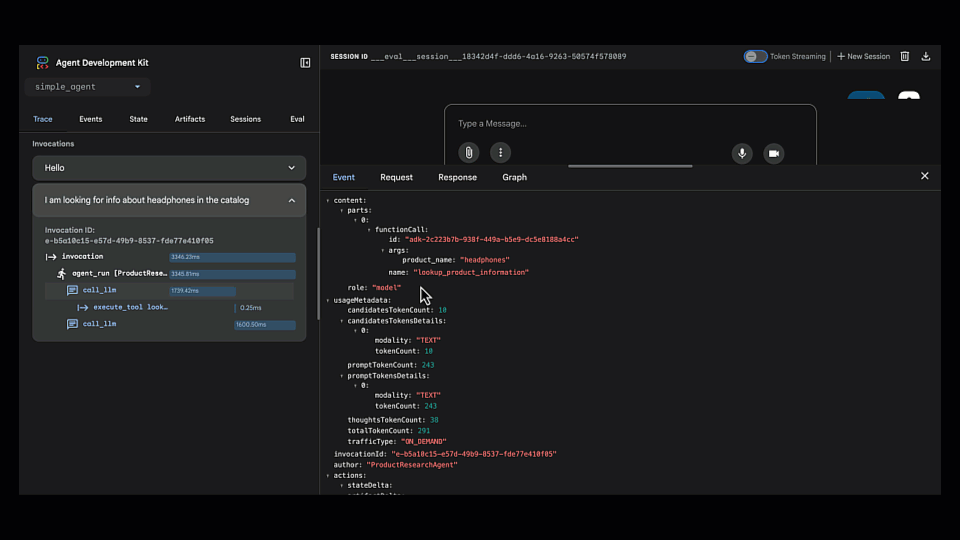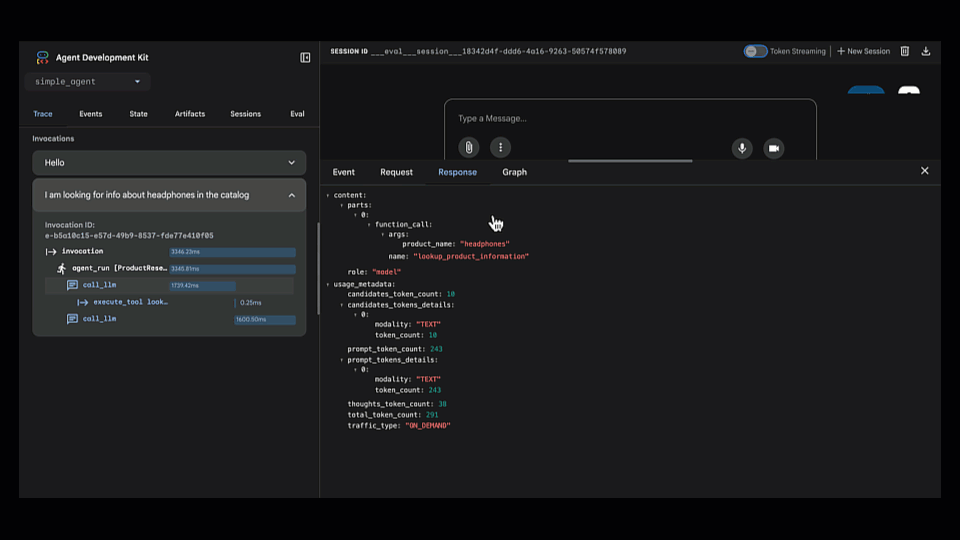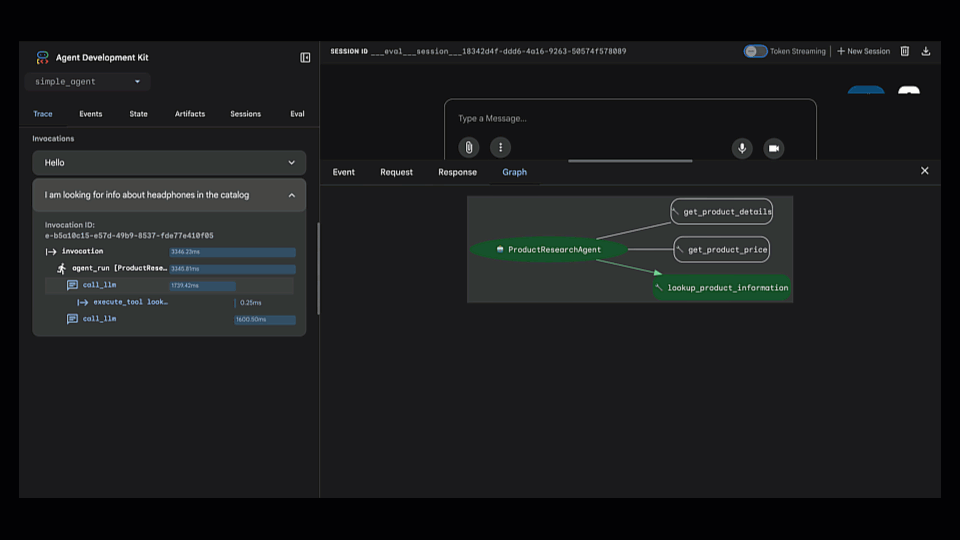
-
修复代理
根本原因是指令不明确。我们更新了代理的代码,明确说明在面向客户的请求与内部数据时应使用哪个工具。 -
验证修复
在 ADK 服务器热重载我们的代码后,我们重新运行评估。这次测试通过,代理返回了正确的面向客户的描述。
从开发到生产
ADK 工作流在开发阶段非常出色,但它的可扩展性有限。对于生产级需求,请迁移到能够处理大规模评估的平台。
从内循环到外循环:ADK 与 Vertex AI
时间戳: 11:51
- ADK 用于内循环 – 在开发期间进行快速、手动、交互式调试。
- Vertex AI 用于外循环 – 以更丰富的指标(例如 LLM‑as‑a‑judge)在大规模上运行评估。使用 Vertex AI Gen AI 评估服务 处理复杂的定性评估并构建监控仪表板。
冷启动问题:生成合成数据
Timestamp: 13:03
当你没有真实数据集时,可以使用一个简单的四步法来创建合成数据:
| 步骤 | 描述 |
|---|---|
| 1️⃣ 生成任务 | 提示大型语言模型(LLM)生成真实的用户任务。 |
| 2️⃣ 创建完美解答 | 使用“专家”代理为每个任务编写理想的、逐步的解答。 |
| 3️⃣ 生成不完美尝试 | 让较弱或不同的代理尝试相同任务,产生有缺陷的输出。 |
| 4️⃣ 自动评分 | 部署 LLM‑as‑a‑judge 将不完美尝试与完美解答进行比较并给出分数。 |
Source: (保持原样)
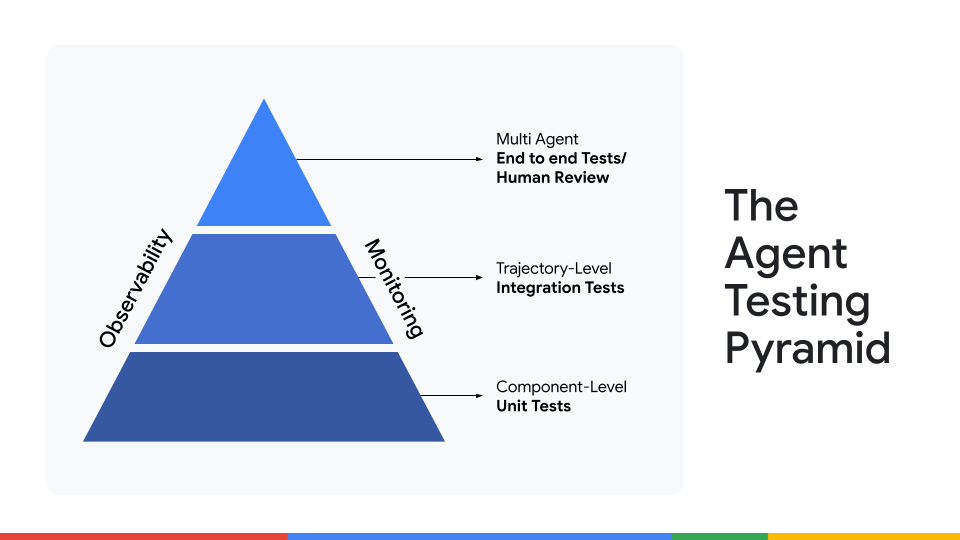
三层代理测试框架
时间戳: 14:10
当你拥有评估数据时,使用三层结构设计可扩展的测试:
| 层级 | 目的 | 示例 |
|---|---|---|
| 1️⃣ 单元测试 | 在隔离环境中测试最小的代码单元。 | 验证 fetch_product_price 能够从示例输入中提取正确的价格。 |
| 2️⃣ 集成测试 | 评估单个代理的完整多步骤流程。 | 给代理一个完整任务,检查它是否能够正确地串联推理和工具,以产生预期的结果。 |
| 3️⃣ 端到端人工评审 | 人类专家对最终输出的质量、细微差别和正确性进行评估。 | 使用“人机交互”反馈系统持续校准代理,并测试多个代理之间的交互。 |
下一步前沿:评估多代理系统
时间戳: 15:09
随着我们从单一代理流水线转向多个代理的编排,评估方式也必须随之演进。未来工作包括:
- 定义 系统层面的指标(例如,协同效率、冲突解决)。
- 构建 自动化编排测试平台,能够模拟跨多个代理的复杂用户旅程。
- 将 LLM‑as‑a‑judge 框架扩展至评估协作结果,而不仅仅是单个响应。
评估多代理系统
单独评判一个代理并不能说明整体系统的表现。
我们使用了一个客服系统的示例,其中包含两个代理:
- 代理 A – 负责初始接触并收集必要信息。
- 代理 B – 处理退款。
如果客户请求退款,代理 A 的任务是收集信息并将其交给代理 B。
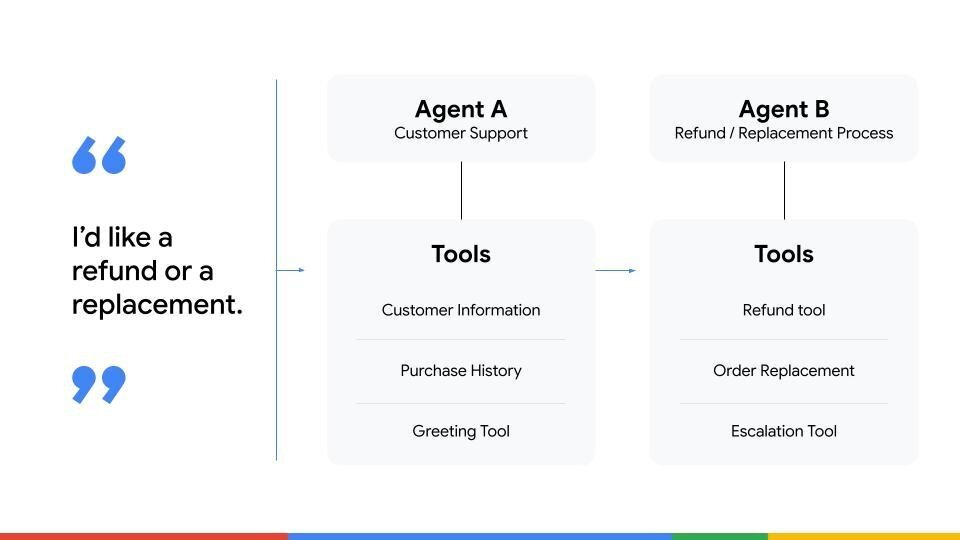
- 单独评估 代理 A 可能会给出 0 分的任务完成得分,因为它从不直接发放退款。
- 实际上,它通过成功交接任务完美地完成了自己的工作。
- 相反,如果代理 A 传递了错误的信息,整个系统就会失败——即使代理 B 的逻辑再完美也无济于事。
这说明在多代理系统中,端到端评估最为关键。我们需要衡量代理之间任务交接的流畅度、上下文共享以及协作实现最终目标的能力。
开放问题与未来挑战
时间戳: 18:06
我们在结束时提到了当今 agent evaluation 中一些最大的未解挑战:
- Cost‑Scalability Trade‑off – 人工评估质量高但成本昂贵;LLM‑as‑a‑judge 可扩展但需要仔细校准。找到合适的平衡点是关键。
- Benchmark Integrity – 随着模型变得更强大,基准测试题目可能泄漏到训练数据中,使得得分的意义降低。
- Evaluating Subjective Attributes – 我们如何客观地衡量代理输出中的创造力、主动性或幽默感等主观属性?这仍是社区面临的未解问题。
Your Turn to Build
本期内容涵盖了众多概念,目标是为您提供一个实用框架,以便思考和实现稳健的评估策略。从 ADK 中的快速迭代循环到 Vertex AI 中的大规模流水线,正确的评估思维方式是将酷炫原型转化为可投入生产的智能体的关键。
我们鼓励您 观看完整节目,亲眼看到演示效果,并将这些原则应用到您自己的项目中。