10,000 个 eBPF 事件对应 1 条警报:别把 CPU 烧坏
Source: Dev.to
问题
eBPF 让你可以观察 Linux 内核所做的 一切。
问题在于:如果把每一个事件都发送到用户空间,你的监控本身就会成为故障点。
在繁忙的服务器上,内核每秒可以产生 数百万个事件:文件打开、网络数据包、进程 fork … 所有事情。
如果你尝试把这些全部发送到数据库或日志系统,会出现两件事:
- 观察者效应: 你的监控代理会消耗 CPU,导致延迟变差。
- 磁盘死亡: 你会用噪声把存储填满,而这些噪声没人会去阅读。
我见过有人仅仅因为在错误的地方打开 debug,就背上了巨额的日志费用。
于是问题变成:如何把 10,000+ 原始事件压缩成 1 条有用的告警,而不把 CPU 烧光?
TL;DR
不能把每个事件都发送到用户空间。跨越边界(内核 → 用户)是有代价的。
我使用的模式是 3‑阶段漏斗:
- 内核过滤 – 在唤醒任何代理之前尽可能丢弃。
- 环形缓冲区 – 需要发送时高效搬运数据。
- 用户空间窗口 – 在时间维度上寻找模式,只有在必要时才告警。
这就是我现在用 Rust + eBPF 构建自己的代理的核心思路。
架构:漏斗,而不是消防栓
如果把 eBPF 当作日志管道来使用,你会输。大部分成本并不是 “eBPF 本身”,而是你频繁跨越 内核 → 用户空间 所强加的工作:
- 唤醒 / 上下文切换
- 代理中每个事件的分配
- 反压导致的丢失事件(即盲点)
你需要一个漏斗:尽早 丢弃无聊的东西,只把有趣的尾巴发送出去。
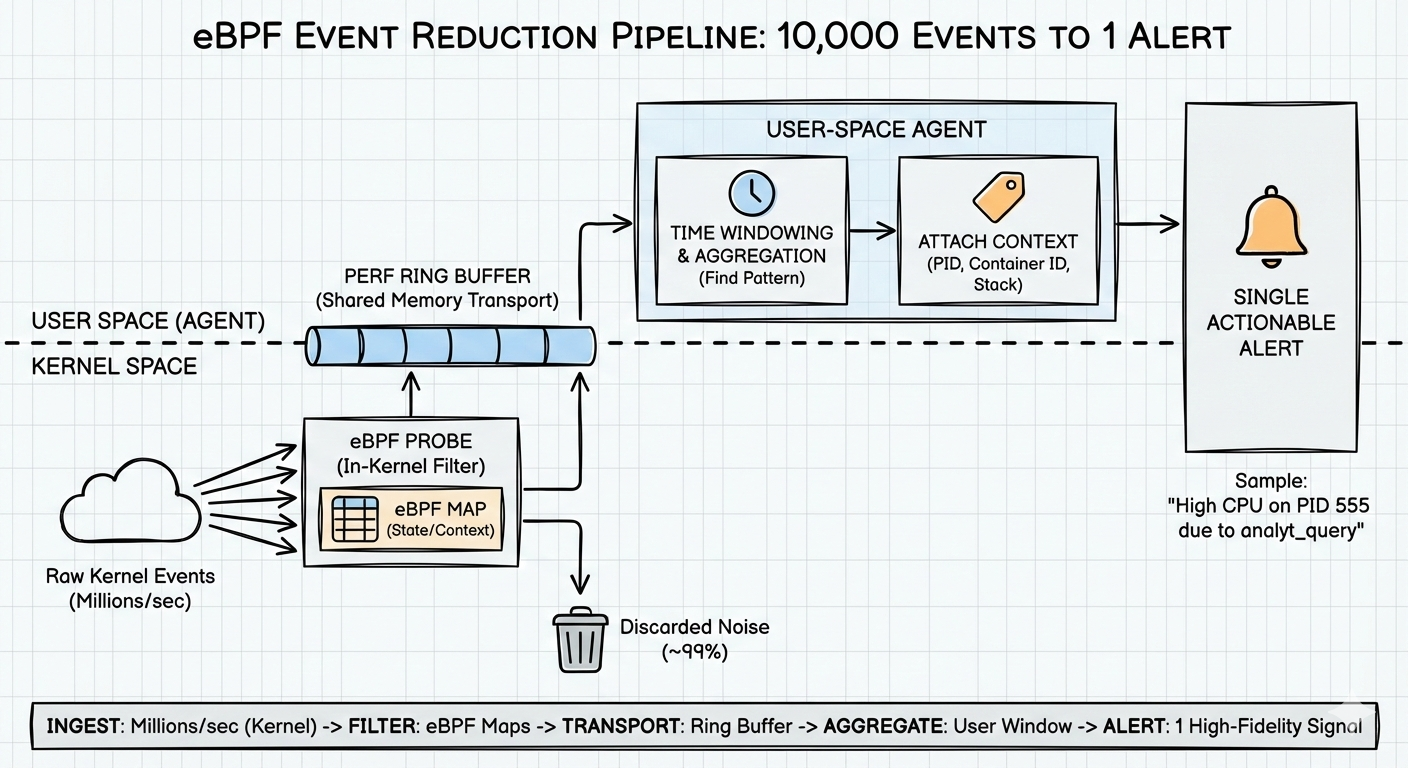
阶段 1:内核过滤(不唤醒代理)
最快的代码是根本不运行的代码。
最便宜的事件是根本不发送的事件。
示例:检测慢速 HTTP 请求
朴素做法
- 在每一次请求开始和结束时,都向用户空间发送一个事件。
- 让代理为每个请求计算
(end - start)并检查是否> 500 ms。
结果:你每秒要发送成千上万的事件,只是为了发现几乎所有请求都是正常的。
eBPF 做法
- 在内核内存中保留一个小 map(哈希表)。
- 请求开始时,将开始时间戳存入 map。
- 请求结束时,查找开始时间,计算时长并检查。
内核中的逻辑:
- 如果时长
> 500 ms→ 向用户空间发送 一个 事件
于是 99 % 的“健康”请求根本不跨越内核边界。没有额外的唤醒,没有额外的分配,什么都不产生。
同样的思路可以用于 fork 风暴、短命作业等。把廉价检查放在内核里,只在出现“有趣”情况时才发出。
阶段 2:环形缓冲区(无痛搬运数据)
当我们真的发现了一个 “坏” 事件(例如 fork‑bomb 模式)时,仍然需要把它送到用户空间。我们 不想:
- 每个事件都写文件
- 把所有数据都通过 TCP 套接字发送
这两者都太慢且会增加开销。
相反,使用 perf 环形缓冲区:
- 内核与用户空间共享的缓冲区
- 内核把事件写入 head
- 代理从 tail 读取
- 每个事件无需系统调用,也无需在热路径上进行分配
难点:落后
如果内核写入的速度快于读取速度,缓冲区会环绕并覆盖旧数据 → 事件被丢失。为降低风险,不要一次只读一个事件并同步处理。我的模式是:
- 从环形缓冲区 批量 读取事件
- 把它们推入内部队列/通道
- 在单独的工作线程中处理
保持环形缓冲区尽可能空,保持内核满意。
阶段 3:窗口(从原始事件到真实告警)
即使过滤后,原始事件仍不是告警。
示例流
PID 100 called fork
PID 100 called fork
PID 100 called fork这并不可操作,只是一串列表。
要把它变成有用的信息,需要在用户空间使用时间窗口。非常简化的伪代码:
# on each fork event
if event.type == "FORK":
process_stats[event.pid].fork_count += 1
# every 1 second (the tick)
for pid, stats in process_stats.items():
if stats.fork_count > 50:
trigger_alert("fork_bomb_suspected", pid)
stats.fork_count = 0现在你得到一个指标:每秒每个 PID 的 fork 数。
告警变为:
“PID 1234 在最近一秒内调用了 57 次 fork。”
比盯着一堆单独的 fork 事件要有用得多。
同样的思路可以用于其他模式:
- “在短时间窗口内打开了 N 个新文件描述符”
- “在 2 秒内创建并退出了 M 个子进程”
- “同一 IP 的网络连接在最近一秒内激增”
缺失的环节:上下文
即使有了良好的过滤和窗口,工具仍常在 “为什么?” 这类问题上失手。你得到的是:“PID 555 的 CPU 高”。你问:“PID 555 实际在干什么?”如果进程已经退出,就无法再检查。
因此我在事件发生的瞬间附带上下文信息:
- 栈追踪 → 当时执行的是哪个函数
- 父 PID → 谁启动了它
- 容器 / cgroup ID → 属于哪个容器 / pod
我尽可能在事件附近(eBPF 程序内部或刚到用户空间时)获取这些数据,并随告警一起发送。告警示例:
“容器 X 中 CPU 高,进程
/usr/bin/worker,函数handle_batch(),父 PID 42”
这样你才有机会真正解决问题,而不是盯着数字发呆。
我今天是怎么使用这些思路的
这些想法对我而言并非空想。我正把它们实现到一个小型的 Rust + eBPF 代理中,我叫它 Linnix:
- eBPF 程序负责内核过滤并写入 perf 环形缓冲区
- Rust 守护进程批量读取事件,执行时间窗口逻辑并触发告警
- 我保持 < 1 % CPU 开销 的硬性预算,这迫使我必须谨慎挑选离开内核的内容
只要遵循以下原则:
- 早过滤(在内核)
- 快传输(环形缓冲)
- 后聚合(用户空间窗口)
就能在每秒数百万操作的系统上进行观察,而不会让你的 “可观测性” 层成为问题本身。
接下来,我想讨论自动化修复——如何在安全的前提下对这些信号采取行动(例如,杀掉失控进程),而不引入新的故障类别。
如果你想看到代码实现,我正在这里慢慢开源: