XBOW, Anthropic의 Mythos 프리뷰를 공격 보안 테스트에 활용
Source: Bleeping Computer

몇 주 전, 초기 기능 테스트를 위해 Mythos Preview에 대한 조기 접근 권한을 받았습니다. 아래는 Mythos Preview를 어떻게 테스트했는지, 어떤 결과를 얻었는지, 그리고 그 의미에 대한 상세 내용입니다.
약 3개월 전, Anthropic은 우리에게 새로운 모델이 능력 면에서 큰 변화를 가져올 것이라고 생각한다며 그 능력을 평가하는 데 도움을 요청했습니다. 그래서 우리는 모델을 보안 검증 과정에 넣었습니다. 벤치마크, 워크플로, 인터랙티브 사용, 그리고 통합까지 모두 진행했습니다.
오늘, 우리는 드디어 Mythos Preview를 어떻게 테스트했는지, 어떤 결과를 얻었는지, 그리고 그 의미가 무엇인지 공유합니다.
스포일러: 이 모델은 큰 도약을 이룹니다. 특히 소스 코드가 제공될 때 취약점 후보를 찾는 능력이 기존 모델보다 현저히 뛰어납니다. 기술적인 정밀함으로 소통하고, 코드에 대해 훌륭히 추론하며, 네이티브 코드 분석 및 리버스 엔지니어링 같은 복잡한 영역에서도 강력한 가능성을 보여줍니다.
우리의 결론: Mythos Preview는 강력한 취약점 리드와 기술적으로 정밀한 분석을 생성하는 강력한 도구입니다. 특히 보안 마인드로 소스 코드를 분석하는 데 뛰어납니다. 하지만 마법은 아닙니다. 모델은 몸이 없는 두뇌일 뿐입니다.
소스 코드 감사는 대부분 두뇌 활동이지만, XBOW가 수행하는 실시간 사이트 펜테스트는 두뇌의 힘에 맞춰질 수 있는 몸이 필요합니다.
테스트 방법론
우리가 먼저 한 일은 회사 내 다양한 부서에서 온 10명의 전문가 팀을 구성해 모델을 여러 관점에서 평가하도록 하는 것이었습니다. 우리는 모든 모델을 Opus 4.7과 GPT 5.5를 분석할 때 사용한 내부 벤치마킹 시스템으로 테스트합니다. 이 시스템에서는 이전에 취약점이 발견된 오픈소스 애플리케이션을 취약 버전으로 고정하고, 우리 에이전트를 실행합니다.
하지만 이번에는 다른 각도에서도 분석 범위를 넓혔습니다:
- 위협 모델링, 취약점 검증, 안전성에 대한 모델의 판단
- 소스 코드를 읽는 능력 vs. 실시간 시스템과 상호작용하는 능력
- 표준 평가에서 아직 탐색하지 못한 익스플로잇(예: 네이티브 앱 취약점) 찾기
용어에 대한 주의: 사람들은 “Mythos”라고 할 때 때때로 원시 모델을 의미합니다. 이번 평가에서는 Claude Code 내부에서 사용된 Mythos Preview와 API를 통해 XBOW 에이전트의 엔진으로 활용한 원시 모델 두 경우를 모두 살펴보았습니다. 오케스트레이션, 도구, 프롬프트, 실시간 사이트 접근 여부가 결과에 실질적인 영향을 미치기 때문에 두 경우를 구분했습니다.
결과
인터랙티브하게 Mythos Preview를 사용해 본 테스터들은 매우 인상 깊었다고 말합니다. “지금까지 본 어떤 것보다도 ‘그냥 가서 뭔가 찾아라’에 가깝다”는 평가가 있었습니다. 자체 소스 코드를 제공했을 때도 약점들을 찾아냈으며—다행히도 치명적인 문제는 없었지만—수정이 필요한 몇 가지 항목을 발견했습니다.
오픈소스 소프트웨어에 적용해 본 결과, 첫 주가 끝날 무렵 이미 공개해야 할 새로운 취약점이 다수 생겼습니다.
벤치마크에서 Mythos Preview를 사용한 테스터들도 역시 인상 깊었지만, 그들의 평가는 약간 다른 차원—데이터에 기반한—이었습니다. 결과는 모델이 엄청난 힘을 발휘한 영역과 다소 미미한 진전만 보인 영역을 명확히 구분해 주었습니다.
Mythos Preview 벤치마크 성능
Mythos Preview를 분석한 후 도출된 주요 인사이트는 다음과 같습니다:
- 소스 코드 감사를 수행할 때 매우 강력함
- 익스플로잇 검증은 어느 정도 가능하지만, 앞선 수준은 아님
- 판단이 엇갈림. 너무 문자 그대로 보수적이면서도, 발견을 실제 적용 가능성 측면에서 과대평가하는 경향이 있음
- 네이티브 코드 취약점 발견 및 리버스 엔지니어링에 강함
차세대 수준의 취약점 발견
Mythos Preview는 공급자와 관계없이 기존 모든 모델을 뛰어넘는 큰 도약을 보여줍니다. 이는 XBOW의 웹 익스플로잇 벤치마크에서도 마찬가지입니다.
이 벤치마크는 모델이 실시간 웹사이트 환경에서 검증 가능하고 실행 가능한 취약점을 찾아줄 수 있는지를 테스트합니다. 80개의 “액션”(쉘, 파이썬 스크립트 등 표준 명령어나 XBOW 공격 도구 사용) 중에서 시스템이 취약점을 검증된 방식(PoC||GTFO)으로 활용할 수 있을 때만 성공으로 간주합니다.
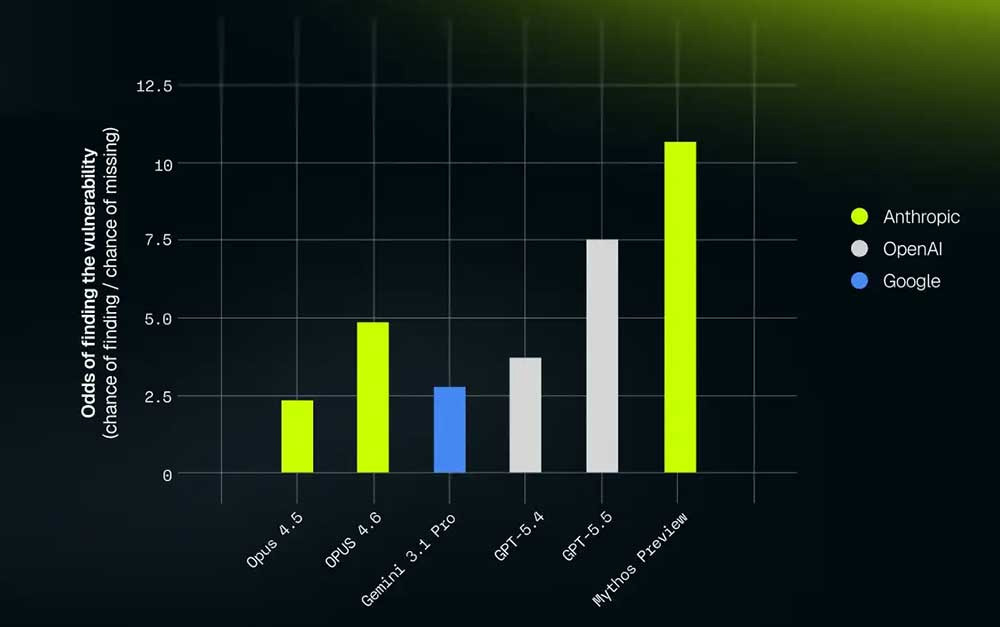
※ 참고: Opus 4.7은 시스템과 독특한 방식으로 상호작용하기 때문에 이 차트에 포함하지 않았습니다. 전체 이야기는 여기에서 확인할 수 있습니다.
당시 최신 모델이었던 Opus 4.6과 비교했을 때 크게 향상되었습니다:
- false negative(실제 존재하는 취약점을 놓친 경우) 비율이 42% 감소
- 두 모델 모두 사이트의 소스 코드를 제공한 경우에는 false negative가 55%까지 감소
이는 이후에도 반복될 테마의 첫 사례였습니다: Mythos Preview는 코드를 작성하는 데도 인상적이지만, 코드를 읽는 데는 더욱 놀라운 성능을 보여줍니다.
아래는 허용된 액션 수(실행된 스크립트)별 Mythos Preview, Opus 4.6, GPT 5.5의 통과율입니다. Mythos Preview는 Opus 4.6에 비해 훨씬 적은 반복 횟수로 취약점을 찾지만, GPT‑5.5와의 차이는 그리 크지 않습니다.
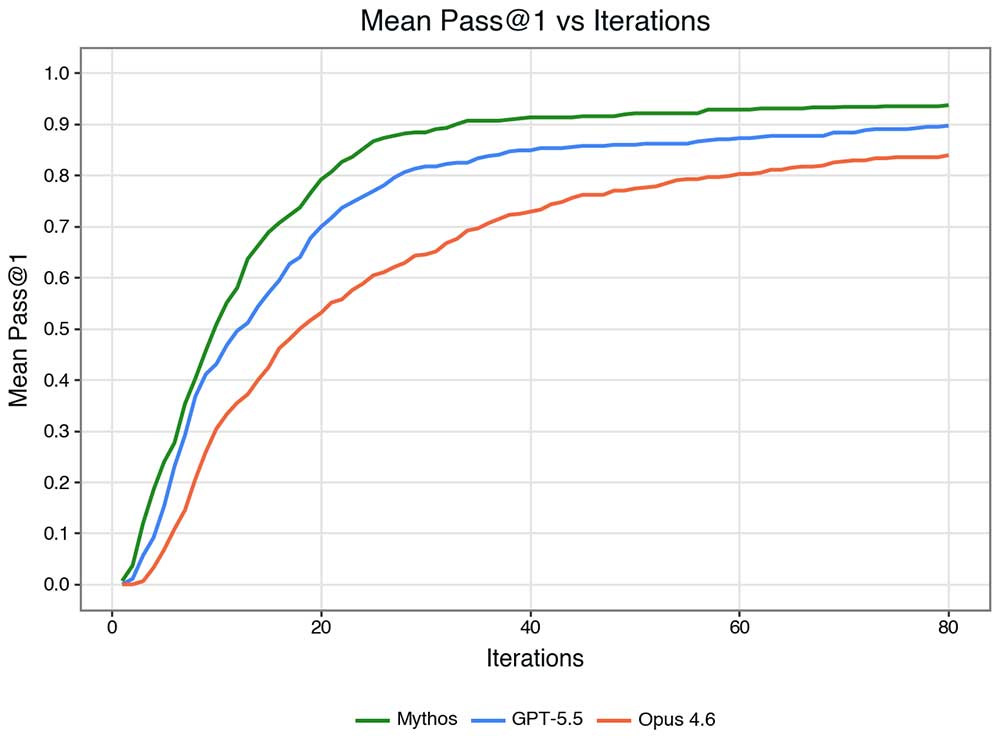
두 가지 고려사항을 추가하면 상황이 더 명확해집니다:
- 모델은 많은 작은 단계 혹은 몇 개의 큰 단계로 진행할 수 있습니다(자세한 내용 여기). 이 점은 크게 중요하지 않을 수도 있습니다. 액션 예산 대신 출력 토큰 예산을 고려해 보겠습니다.
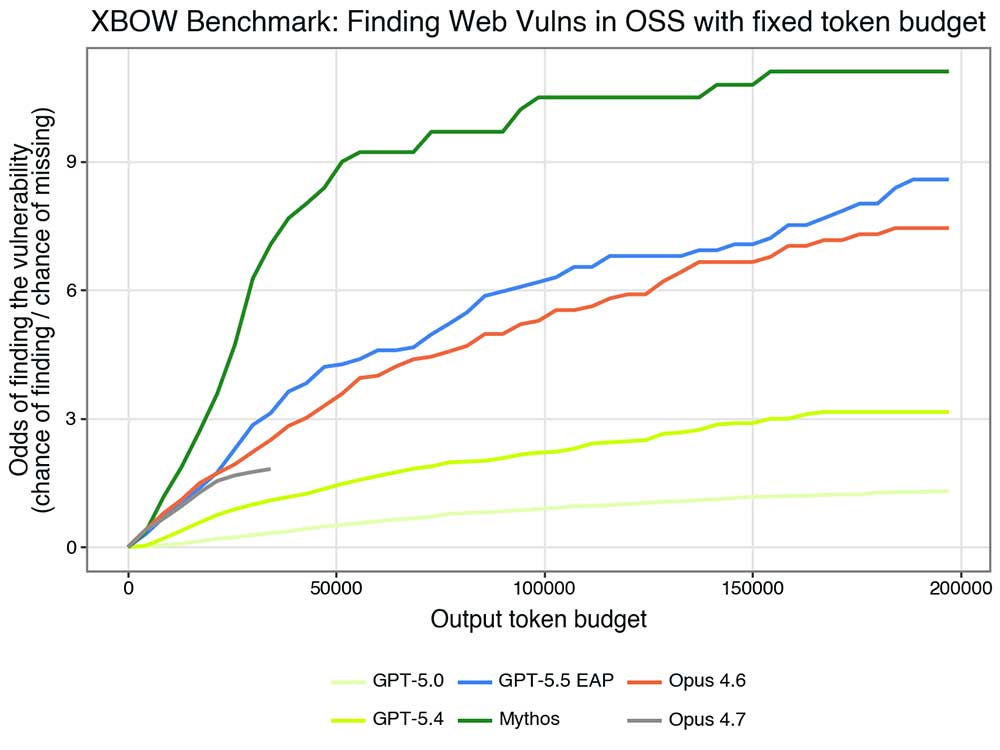
- 평균 통과율(취약점을 찾을 확률)보다 발견 확률, 즉 모델이 올바른 발견을 할 확률을 베팅 비율로 보는 것이 더 instructive합니다. 계산적으로는 히트 레이트를 미스 레이트로 나눈 값이 됩니다.
이러한 관점에서 보면 그림이 훨씬 선명해집니다: 토큰당 토큰으로, Mythos Preview는 취약점을 전례 없는 정밀도로 집중합니다.
실시간 사이트 검증이 가장 어려운 부분
Mythos Preview는 소스 코드 추론에 뛰어나지만, 우리의 평가를 통해 실용적인 진실이 확인되었습니다: exploitable한 많은 문제는 애플리케이션 소스 코드에 명백한 결함으로 나타나지 않습니다. 이들은 설정, 의존성, 배포 선택, 혹은 안전한 구성 요소가 결합되는 방식에서 발생합니다.
예를 들어, 어떤 의존성 자체는 안전할 수 있고, 소스 코드 자체도 안전할 수 있습니다. 하지만 소스 코드가 그 의존성을 안전하지 않게 사용한다면 취약점이 생깁니다. Gary McCraw가 유명하게 말했듯이(https://www.informit.com/articles/article.aspx?p=446451), “코드만 바라보는 것만으로는 대부분의 결함을 찾을 수 없습니다.”
이 점은 우리에게 특히 중요합니다. XBOW는 펜테스트를 수행하는데, 우리의 목표는 공격자가 보는 실시간 사이트입니다. 반면 Mythos Preview는 예를 들어 Project Glasswing에서 사용되듯 소스 코드(개발자가 보는 관점)를 감사하는 데 뛰어납니다.
실시간 사이트와 상호작용하는 것은 매우 강력하지만, 완전히 새로운, 매우 섬세한 차원을 도입합니다. 여기서 Mythos Preview가 균형을 바