왜 클라우드 인프라가 이벤트 기반인가?
Source: Dev.to
위에 제공된 내용 외에 번역할 텍스트가 없습니다. 번역이 필요한 본문을 제공해 주시면 한국어로 번역해 드리겠습니다.
이벤트‑드리븐 아키텍처가 실제 의미하는 바 (교과서 수준을 넘어)
핵심은 간단합니다:
무언가가 변하면 → 시스템이 자동으로 반응한다.
이벤트는 의미 있는 상태 변화이며, 예를 들어 다음과 같습니다:
- CPU가 임계값을 초과함
- 트래픽이 급증함
- VM이 비정상 상태가 됨
- 배포가 진행됨
- 비용 이상 현상이 나타남
- 보안 규칙이 수정됨
사람이 직접 개입하거나 동기식 요청을 기다리는 대신, 시스템은 이러한 변화를 감지하고 실시간으로 대응합니다.
이로 인해 얻어지는 장점:
- 느슨하게 결합된 시스템
- 더 빠른 반응
- 높은 복원력
- 인간 개입 최소화
Amazon Web Services, Microsoft Azure, Google Cloud와 같은 클라우드 플랫폼은 본질적으로 이 모델을 기반으로 구축되어 있으며, AWS Lambda와 Google Cloud Pub/Sub와 같은 서비스를 활용합니다.

Reactive Scalability: 무언가 발생했기 때문에 확장
Traditional infrastructure scales based on assumptions.
전통적인 인프라는 가정에 기반해 확장됩니다.
Event‑driven infrastructure scales based on reality.
이벤트 기반 인프라는 현실에 기반해 확장됩니다.
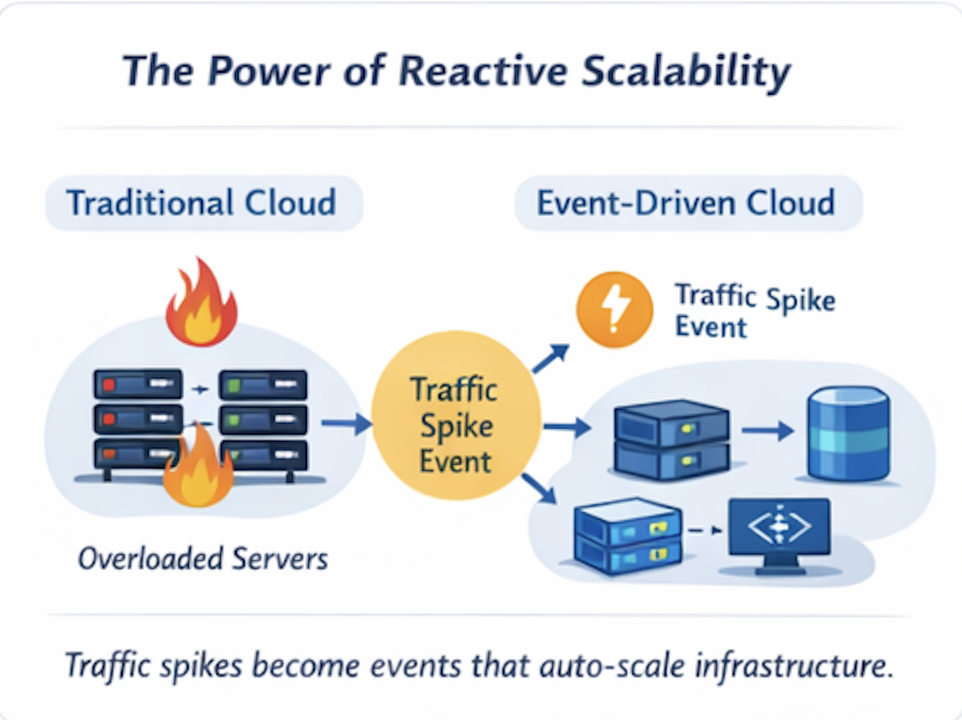
기존 문제
A sudden traffic surge (flash sale, feature launch, marketing spike) overwhelms fixed capacity.
갑작스러운 트래픽 급증(플래시 세일, 기능 출시, 마케팅 스파이크)이 고정된 용량을 초과합니다.
Result
결과
- Slow response times
- 응답 시간 지연
- Errors
- 오류
- Pager alerts
- 페이지 알림
- Revenue loss
- 매출 손실
이벤트 기반 현실
Traffic increase is treated as an event, not a surprise. That single signal automatically triggers:
트래픽 증가를 놀라움이 아닌 이벤트로 간주합니다. 이 단일 신호가 자동으로 트리거합니다:
- New containers or instances spinning up
- 새로운 컨테이너 또는 인스턴스 자동 생성
- Load balancers redistributing traffic
- 로드 밸런서가 트래픽 재분배
- Read replicas scaling out
- 읽기 복제본 확장
- Caches warming proactively
- 캐시를 사전 가열
All of this happens in seconds, without human involvement.
이 모든 과정은 몇 초 안에, 인간 개입 없이 이루어집니다.
- Developers experience fewer firefights.
- Developers는 화재 진압 상황이 줄어듭니다.
- FinOps sees capacity only when it’s needed—no idle waste.
- FinOps는 필요할 때만 용량을 확인하므로 유휴 자원이 없습니다.
자동 복구: 실패는 또 다른 이벤트일 뿐
Failures are inevitable. Downtime is not.
이벤트 기반 클라우드에서는 실패가 공황을 일으키지 않고 워크플로우를 트리거합니다.
예시
- 노드가 응답하지 않게 됩니다
- 모니터링이 실패 이벤트를 발생시킵니다
- 인스턴스가 로테이션에서 제거됩니다
- 대체 인스턴스가 프로비저닝됩니다
- 트래픽이 재라우팅됩니다
- 사건이 로그에 기록되고 알림이 전송됩니다
티켓이 없습니다. 대기하지 않습니다. 영웅적인 행동도 없습니다.
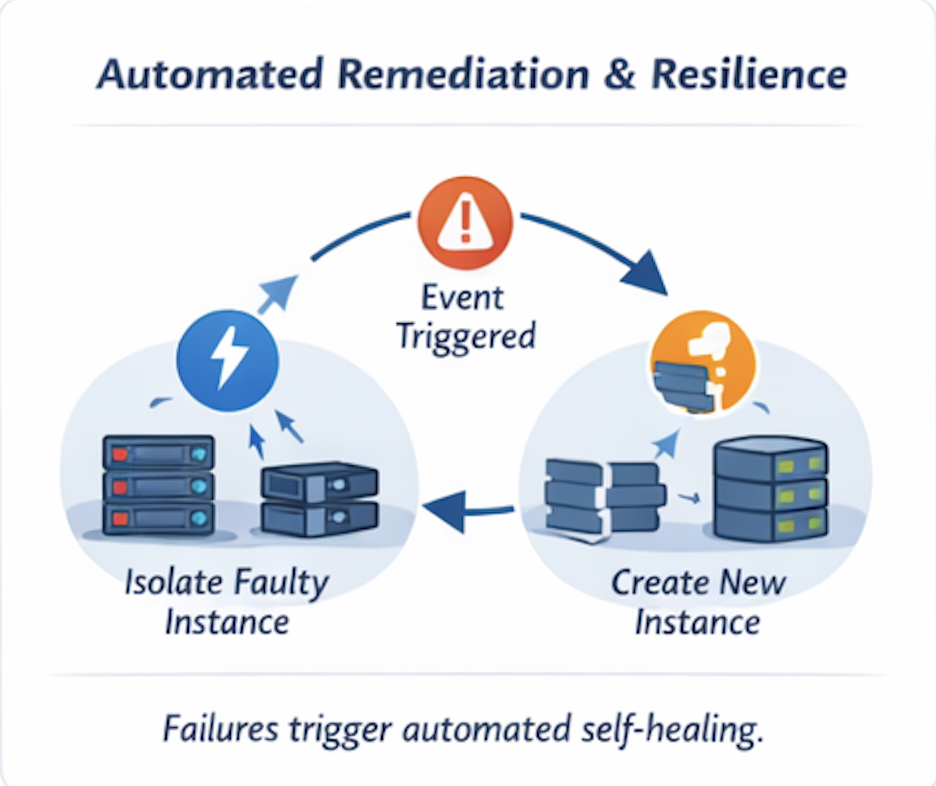
이는 자체 복구 인프라이며, 시스템이 수동 프로세스에 의존하지 않고 이벤트에 반응할 때만 가능합니다.
구성, 거버넌스 및 컴플라이언스 – 이벤트에 의해 강제됨
대규모 클라우드 환경에서는 구성 드리프트가 필연적입니다. 수동으로 강제하는 방식은 규모에 맞지 않습니다.
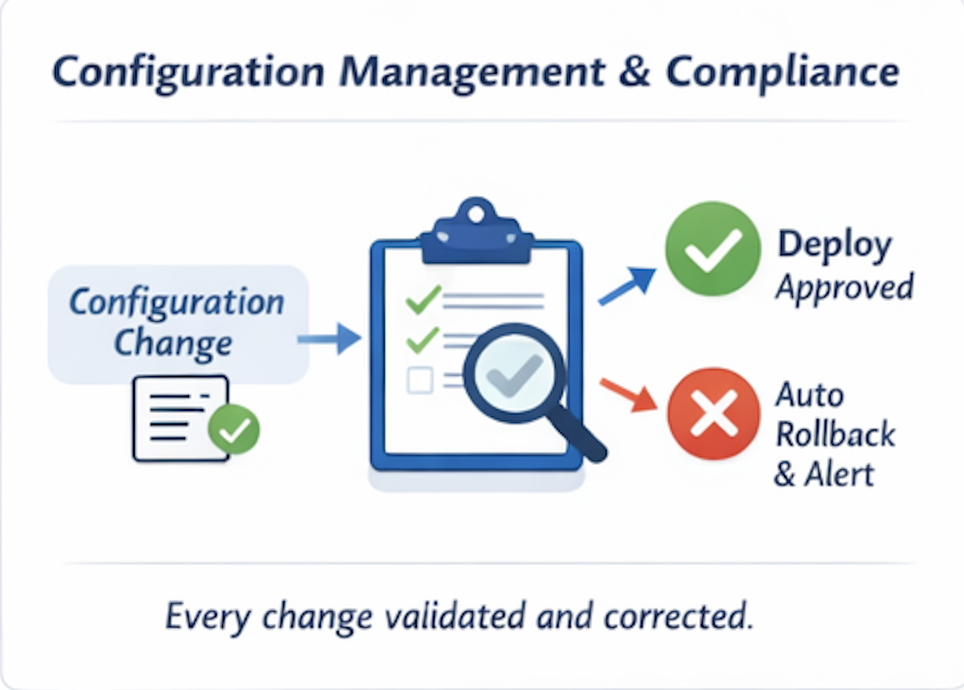
이벤트 기반 거버넌스는 모델을 전환합니다:
- 모든 인프라 변경이 이벤트가 됩니다
- 각 이벤트는 자동 정책 검사를 트리거합니다
- 위반 사항은 즉시 교정 조치 또는 알림을 생성합니다
- 드리프트가 거의 실시간으로 감지되고 수정됩니다
정기적인 감사와 사후 수정 대신, 컴플라이언스가 지속적이고 자동화됩니다. 이는 특히 다음 상황에서 중요합니다:
- 규제 대상 환경
- 다중 계정·다중 클라우드 설정
- 고속 엔지니어링 팀
자동화: 신호를 결과로 전환하기
이것이 이벤트‑드리븐 클라우드가 진정으로 가치를 복합적으로 창출하는 지점입니다. 이벤트를 전체 플랫폼을 연결하는 접착제라고 생각하세요.

단일 이벤트는 여러 자동화 작업으로 확장될 수 있습니다:
- 스토리지 업로드 → 처리 함수
- 처리 완료 → 데이터베이스 업데이트
- 데이터베이스 업데이트 → 알림
- 알림 → 하위 워크플로우
각 단계는 새로운 이벤트를 발생시켜, 느슨한 결합으로 작업을 연쇄합니다.
결과는?
더 적은 sc
이벤트‑드리븐 클라우드 인프라의 장점
- 크론 작업 감소
- 수동 런북 감소
- 시스템 신뢰성 향상
엔지니어는 제품 개발에 집중합니다.
FinOps 팀은 청구서를 쫓기보다 신호 최적화에 집중합니다.
FinOps에 더욱 중요한 이유
불편한 진실은 다음과 같습니다:
클라우드 비용은 무작위로 급증하지 않습니다. 무언가가 발생했기 때문에 급증합니다.
- 워크로드가 예상치 못하게 스케일업됨
- 일정이 삭제됨
- 배포가 루프에 빠짐
- 서비스가 유휴 상태이지만 계속 켜져 있음
이 모든 것이 이벤트입니다.
이벤트‑드리븐 인프라는 FinOps 팀이 다음을 할 수 있게 합니다:
- 비용에 영향을 주는 이벤트를 즉시 감지
- 청구서가 폭발하기 전에 대응
- 셧다운, 스케일‑다운, 최적화 자동화
- 비용을 시스템 동작에 직접 연결
이벤트가 없으면 FinOps는 반응형입니다.
이벤트가 있으면 FinOps는 실시간 비용 제어가 됩니다.
클라우드는 기다리지 않는다 – 인프라도 마찬가지
현대 클라우드 인프라는 서버 관리가 아니라
변화에 지능적으로 대응하는 것입니다.
이벤트‑드리븐 아키텍처는 모든 변화를 관찰 가능하고, 실행 가능하며, 자동화하도록 만들어 이 전환을 가능하게 합니다.
- 지능형 스케일링
- 자동 복구 시스템
- 지속적인 컴플라이언스
- 실시간 비용 최적화
이벤트‑드리븐 설계는 이제 선택 사항이 아닙니다.
현재 상황에 자동으로 반응하지 못하는 클라우드는 이미 뒤처진 것입니다.
클라우드 인프라의 미래는 정적이지 않습니다.
그것은 듣고,
반응하고,
최적화합니다.
그리고 그것은 이벤트‑드리븐입니다.