우리는 브라운 대학교에서 Hackathon을 우승했다 🏆
Source: Dev.to
Inspiration
우리 모두는 어디서 시작해야 할지 모른 채 가정 수리 문제에 직면해 본 적이 있습니다. 혼자 사는 여성이나 막 세탁을 배운 대학 신입생(그게 바로 저!)은 막힌 변기부터 물 파이프 누수까지 일상적인 문제에 부딪힐 수 있습니다.
때때로 사소한 문제를 확인하기 위해 낯선 사람을 우리 생활 공간에 들이는 것이 불편하게 느껴집니다. 뉴욕 같은 도시에서는 짧은 기술자 방문조차도 비용이 많이 들어, 젊은 성인과 노인 모두에게 실제 재정적 부담이 됩니다. 우리는 많은 사람들이 첫 번째로 무엇을 해야 하는지, 그리고 실제로 안전하게 시도할 수 있는 것이 무엇인지에 대한 명확하고 단계별 안내가 필요하다는 것을 깨달았습니다.
이것이 바로 우리에게 가정용 전자제품 및 수리에 경험이 있는 사람과 FaceTime으로 대화하듯, 인터랙티브한 가정 문제 해결 플랫폼을 만들게 한 동기가 되었습니다.
무엇을 하는가
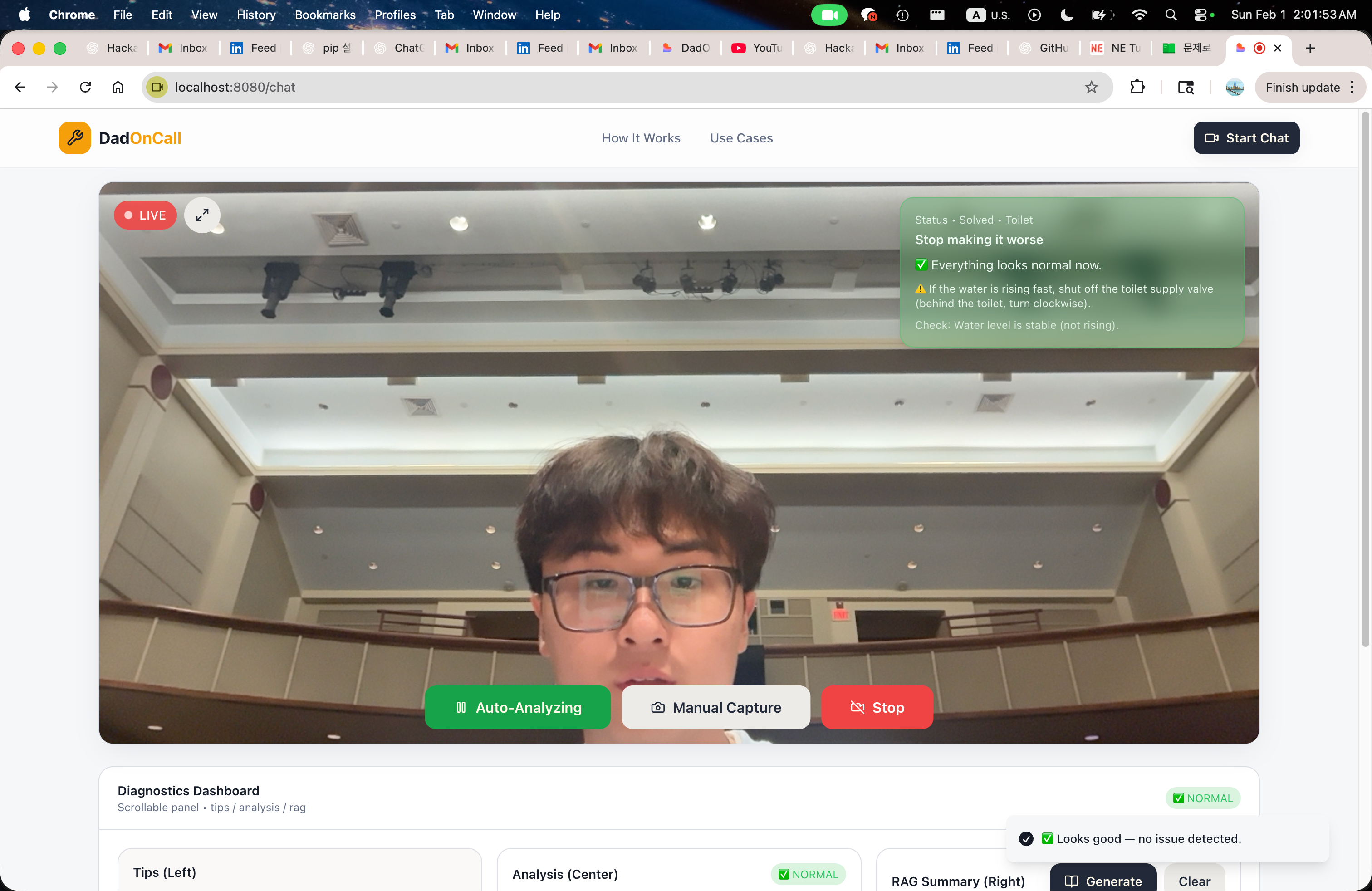
HandyDaddy는 가정 문제를 다룰 때 도움이 됩니다. 간단한 선풍기 문제부터 화장실을 뚫는 방법 같은 스트레스가 큰 작업까지. HandyDaddy가 없던 시절엔 아빠에게 전화하거나 정보를 찾으러 오래 검색했지만, 그런 방법은 특정 상황에 대한 실시간 피드백을 제공하지 못했습니다.
HandyDaddy는 실시간 비디오를 사용해 보는 것을 기반으로 단계별 안내를 제공합니다. 언어 모델에만 프롬프트를 주고 그 결과를 신뢰하는 대신, HandyDaddy는 구조화된 출력 + RAG‑지원 검색이라는 더 신뢰할 수 있는 파이프라인을 사용합니다. 따라서 응답이 근거가 있고, 효율적이며, 안전합니다.
어떻게 만들었는가
우리는 HandyDaddy를 개인용 실시간, 비전 우선 홈 리페어 어시스턴트로 만들었습니다. 핵심 아이디어는 간단했습니다: 사용자가 문제를 설명하도록 요구하는 대신, 우리가 SHOW 하게 했습니다.
-
Vision layer – 시스템은 실시간 비디오 피드에서 지속적으로 이미지를 캡처하고 이를 Gemini에 전달합니다. Gemini는 비전 모델 역할을 합니다. 각 프레임마다 Gemini는 JSON 형식의 구조화된 분석을 생성하여 설비, 위치, 잠재적 문제 및 안전 수준을 식별합니다. 이 구조화된 출력은 이후 모든 작업의 기반이 되며, 문서화를 위해 최적화된 의미 검색 쿼리도 생성합니다.
-
Retrieval‑Augmented Generation (RAG) – 우리는 FAISS와 문장 임베딩을 사용해 자체 벡터 스토어를 구축하고, Markdown으로 작성된 실제 수리 및 안전 문서를 색인했습니다. 모델에게 “스스로 알아내라”고 요구하는 대신, 가장 관련성 높은 정보를 검색하여 바로 솔루션 단계에 전달합니다.
-
Planning layer – Groq의 고성능 LLM이 세 가지 입력(정제된 분석, 검색된 문서, 안전 제약)으로부터 명확한 단계별 계획을 합성합니다. 이와 같은 분리(vision → reasoning → retrieval → planning)는 각 모델이 단일 책임에 집중하도록 하여 시스템을 디버깅하고 신뢰하기 쉽게 만듭니다.
-
State management – 모든 중간 상태는 세션당 Redis에 저장되어, 시스템이 각 이미지를 독립적인 요청으로 처리하는 것이 아니라 시간에 따라 진행 상황을 추적할 수 있게 합니다. 이를 투명하게 보여주기 위해 우리는 로컬 “백스테이지 뷰어”를 구축했으며, 원시 비전 출력부터 최종 가이드까지 데이터가 파이프라인을 통해 어떻게 흐르는지 정확히 보여줍니다.
전체적으로, HandyDaddy는 우리 아버지와 비슷합니다: 속도와 힘보다는 신중한 오케스트레이션에 중점을 두며—출력을 제한하고, 책임을 분리하며, 실제 문서에 기반한 결정을 내립니다.
Source: …
우리가 직면한 도전 과제

가장 어려운 과제 중 하나는 GPT 래퍼를 또 하나 만들고 싶어지는 유혹을 피하면서 시스템 아키텍처를 처음부터 설계하는 것이었습니다. HandyDaddy가 상황을 실제로 이해하지 못하고 일반적인 답변만 제공하는 챗봇처럼 느껴지길 원하지 않았습니다. 이 도구는 물, 전기, 안전 등과 관련된 실제 문제를 겪는 사람들을 돕기 위한 것이므로, 추측은 용납될 수 없었습니다.
시스템을 신뢰할 수 있게 만들기 위해서는 처음 예상했던 것보다 훨씬 복잡한 아키텍처를 설계해야 했습니다. 하나의 모델이 모든 일을 하게 하는 대신, 시스템을 명확한 단계로 나누었습니다:
- 시각적 이해 (Gemini)
- 구조화된 추론 및 출력 (JSON)
- 문서 검색 (RAG)
- 단계별 계획 (Groq)
각 단계마다 중요한 역할이 있습니다. 처음에는 개발 속도가 느려지고 어려워졌지만, 결과적으로 훨씬 더 신뢰할 수 있는 제품이 탄생했습니다.
또 다른 도전 과제는 모델의 출력을 자유 형식 텍스트가 아니라 엄격한 JSON 스키마에 맞추는 것이었습니다. 초기 시도에서는 많은 의심과 실패가 있었지만, 곧 이 제약이 필수적이라는 것을 깨달았습니다. 이를 통해 상태를 추적하고, 안전성을 논리적으로 판단하며, 시스템이 특정 권고를 내린 이유를 설명할 수 있게 되었습니다.
전반적으로 가장 큰 도전은 속도와 단순성보다 정확성과 신뢰를 선택하는 것이었습니다. 사람들을 위한 시스템을 구축한다는 것은 불편함이 있더라도 신중해야 함을 의미합니다.
우리가 자랑스러워하는 성과

- 실시간 비전‑우선 지원 – 사용자는 문제를 휴대폰 카메라로 간단히 비추면 실시간 안내를 받을 수 있습니다.
- 안전‑우선 설계 – 구조화된 JSON 출력으로 안전 제약을 강제하고 작업이 위험하다고 판단되면 중단할 수 있습니다.
- 근거 기반 답변 – RAG를 통해 모든 권고가 검증된 수리 문서에 기반하도록 합니다.
- 투명한 파이프라인 – 백스테이지 뷰어를 통해 개발자와 사용자는 시스템이 어떻게 조언에 도달했는지 정확히 확인할 수 있습니다.
- 확장 가능한 아키텍처 – 분리된 구성 요소(비전, 검색, 계획, 상태) 덕분에 모델을 교체하거나 새로운 지식 소스를 추가하기가 쉽습니다.
HandyDaddy는 비전, 구조화된 추론, 검색‑증강 생성(RAG)을 결합하여 까다로운 가정 수리 문제를 관리 가능한 가이드형 경험으로 전환하는 방식을 보여줍니다—마치 영상 통화로 지식이 풍부한 아빠와 함께하는 것과 같습니다.

We’re most proud of the complete full‑cycle architecture we built and how it works in real time. HandyDaddy doesn’t just analyze a single image; it reacts, updates, and guides users step‑by‑step based on what it sees **LIVE**. This makes the experience feel personal and practical, not theoretical.
The live feedback loop is something we genuinely find useful and are proud of. Seeing the system detect a situation, assess risk, and immediately guide the next safe action feels like a full circle—something we would actually want to use in our college dorm starting tomorrow.
We’re also proud that the system is transparent. Every decision, from vision detection to document‑based guidance, can be traced and inspected. That clarity gives us confidence that the system isn’t guessing, and it helps us improve it faster.우리가 배운 것

- 세상은 문제로 가득하지만, 시간은 언제나 제한적입니다. 그런 긴장이 사물을 만드는 것을 흥미롭게 만듭니다. 늦게까지 깨어있고(때로는 1분도 못 자고), 한 줄씩 디버깅하며 시스템이 하나씩 완성되는 모습을 보는 것은 우리에게 진정으로 즐겁고 의미 있는 일이었습니다.
- 우리 중 누구도 처음부터 전체 AI 파이프라인을 설계한 적이 없었습니다. 연구 논문을 읽고, YouTube 영상을 시청하고, 다양한 접근 방식을 실험하면서 기대 이상으로 많은 것을 배웠습니다. 우리는 모델이 어떻게 작동하는지뿐만 아니라 시스템이 어떻게 작동하는지, 그리고 작은 설계 결정이 신뢰, 안전, 사용성에 어떻게 영향을 미치는지를 배웠습니다.
- 무엇보다도, 우리는 대학생, 가족, 심지어 노년층까지 다양한 사람들에게 도움이 될 수 있는 무언가를 만든다는 것이 얼마나 강력한 느낌인지 깨달았습니다. 그 생각만으로도 긴 밤을 견디게 만들었습니다.
HandyDaddy의 다음 단계
- 음성 및 이미지 입력 동기화 – 현재 HandyDaddy는 이미지 분석과 음성 입력을 지원하지만, 각각 별도로 처리됩니다. 이미지 캡처와 음성 업데이트가 프런트엔드에서 서로 다른 상태 리셋을 트리거하기 때문에, 진정한 동시 제출은 아직 완전히 해결되지 않았습니다.
- 스트림 결합 – 다음 단계는 음성과 이미지를 하나의 입력으로 함께 캡처하는 것입니다. 이를 통해 시스템은 단순히 보는 것뿐만 아니라 사용자가 그 순간에 말하는 내용도 이해할 수 있게 됩니다. 이를 해결하면 HandyDaddy가 훨씬 더 자연스럽고 인간적으로 느껴질 것입니다.
- 시나리오 적용 범위 확대 – 멀티모달 입력을 넘어, 우리는 동일한 핵심 원칙을 유지하면서 더 많은 가정 시나리오를 다루고자 합니다: 복잡한 추론, 근거 있는 검증된 지식, 그리고 실제 사람들에게 실질적인 유용성.