Elasticsearch에 지속적인 에이전트 메모리 계층을 구축해 0.89 회상률 달성
출처: Hacker News
에이전트 메모리 구축하기 (Elasticsearch)
세 개 인덱스, 하이브리드 재랭커를 이용한 리콜, 스프레션(재정적 대체), 덴데이션, DLS. 영구 메모리 레이어의 아키텍처와 그 뒤에 숨은 숫자.
사라의 스마트 전구는 오직 흰색만 표시됩니다. 그녀의 스마트 홈 어시스턴트는 허브 재설정을 제안합니다. 그녀는 3월에 한 번, 그리고 지난 주에 또 재설정했지만, 어느 것도 문제를 해결하지 못했습니다. 에이전트는 그 사실을 모르고, 또한 센서 케이블을 개가 씹었다는 사실도 모릅니다. 중요한 기록은 무엇이 효과적이었는지, 무엇이 아니었는지, 그리고 사라의 정체까지 매 세션마다 끝납니다.
표준 우회책은 이전 컨텍스트를 문맥 창문에 넣는 것입니다. 이는 비용, 지연 시간, 그리고 모델이 프롬프트 가장자리에서 멀리 떨어진 사실들을 무시하는 잘 알려진 “중간에 빠짐” 효과에 따른 문제를 일으킵니다. 1M 토큰 컨텍스트 창은 스케치보드일 뿐, 메모리 시스템이 아닙니다.
문맥 창은 단기 메모리입니다: 단일 인퍼런스를 위한 활성 추론 공간. 부족한 것은 장장 메모리 — 세션 종료 후에도 유지되는 영구 저장소이며, 수년 간의 상호작용을 스케일링하고 내용, 시간, 사용자별로 사실을 검색할 수 있게 해줍니다.
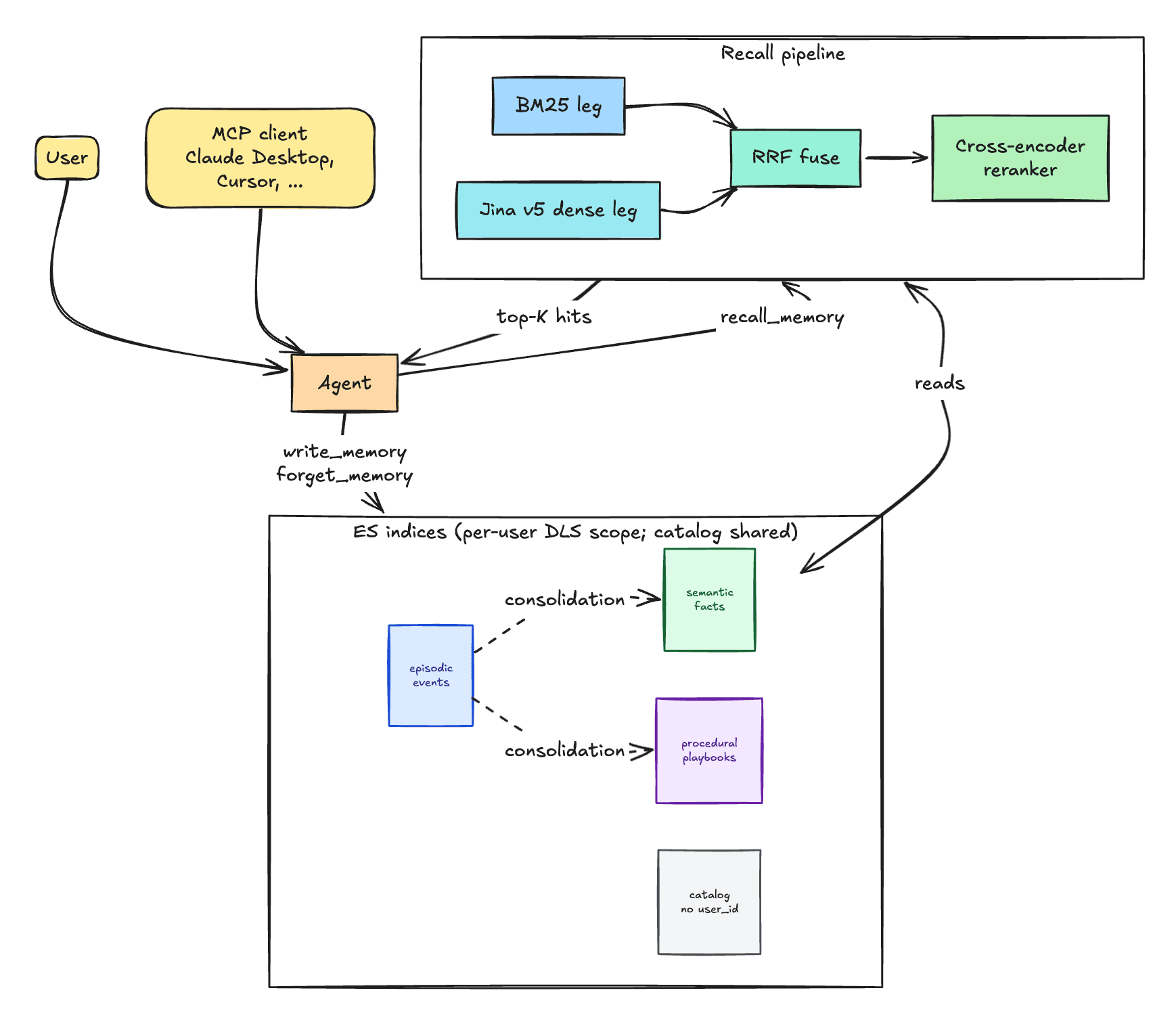
이 포스트는 Elasticsearch를 기반으로 구축된 실제 에이전트 메모리 시스템의 아키텍처에 대해 다룹니다. 이는 인지 과학에서 온 세 가지 카테고리로 구성되며, 하이브리드 재검색 쿼리(RRF)와 크로스-인코더 리러ンキнг, 대조(재정적 대체)를 위한 쿼리, 그리고 사용자별 DLS 격리를 포함합니다. 168개의 질문으로 구성된 QA 스타일 평가에서 R@10 평균은 0.89이며, 크로스-테넌트 유출이 없습니다.
전체 구현은 GitHub에 있습니다. 이 포스트는 왜 이렇게 설계되었는지에 대해 다룹니다.
에이전트 메모리 스토어가 해야 할 일
사용자가 “이전엔 어떤 해결책을 시도했나요?” 라는 시계적 질의(정확한 매치 제약 조건)를 하거나, “왜 내 스마트 전구는 오직 흰색만 표시되나요?” 와 같이 개인 메모리와 공유 카탈로그를 결합해야 하는 경우가 있습니다. 메모리 자체는 균일하게 행동하지 않습니다: 사용자가 경험한 사건, 안정된 사실, 단계별 플레이북은 각각 다른 기록률과 노화 규칙을 가지고 있어, 스토어가 유형을 인식하고 그에 따라 처리해야 합니다. 또한 다중 사용자 환경에서는 각 사용자의 메모리가 다른 사용자와 보이지 않아야 합니다.
신선한 이벤트는 빠르게 축적되므로 내구성 있는 형태로 통합해야 하며, 그렇지 않으면 인덱스가 헤이스트랙이 되어 버립니다.
사용자가 회상된 사실을 contradicit(반박)하면, 삭제 대신 오래된 버전을 재정의해야 하며, 감사 기록이 유지됩니다. 오래된 사실은 새것보다 상위 순위에 올라와서는 안 되며, 자주 사용되는 사실은 가라앉지 않아야 합니다. 전체 메모리 레이어는 MCP-speaking 클라이언트에서 접근 가능해야 하며, 특정 에이전트 런타임에 묶이지 않아야 합니다.
벡터 스토어, 키워드 엔진, 감사 레이어, 그리고 별도 인증 서비스로 나누면 사물을 깨뜨릴 수 있는 네 가지 요소가 생기고, 매 회상 시 추가 라운드트립이 발생합니다. 요구 사항은 검색 엔진을 설명하므로 이 구현에서는 하나의 검색 엔진을 사용합니다.
에이전트 메모리 유형 3가지: 에피소딕, 의미론적, 절차적
-
에피소딕 메모리. 시간 표시된 이벤트: 사용자 턴이 발생하는 순간, 추출이나 해석 이전에. 대부분은 단기적이며 지속할 가치가 없음. 몇 건의 항목은 나중에 영구적인 사실 증거가 됩니다.
-
의미론적 메모리. 사용자에 대한 압축된, 안정된 주장들. 사라가 Lumio Hub v2를 소유하고 있다. 사라는 iOS 17.4을 사용한다. 사라의 허브는 3월에 재설정되었다. 이 내용은 세션 간에 지속되며, 에이전트가 근거로 삼습니다.
-
절차적 메모리. 다단계 플레이북. Zigbee 연결 문제 해결 방법. 사실보다는 과정을 담고 있습니다. 각 항목은
success_count와failure_count를 가지며, 사용자가 해결책이 성공했는지 확인할 때 통합을 통해 증가합니다. 이 카운터는 컨솔리데이션 LLM에 의해 플레이북을 정교화하거나 교체할지 여부를 판단하는 데 문맥으로 제공됩니다.
각 카테고리는 다른 수명 주기를 가집니다. 에피소딕은 지속적으로 기록되고 감소합니다. 의미론적 메모리는 정리되고 중복 제거되며, 사용자가 변경함에 따라 재정의됩니다. 절차적 메모리는 success_count, failure_count 와 같은 결과 피드백을 축적하여 컨솔리데이션을 지원합니다.
한 개 버킷은 이를 모델링할 수 없습니다. 세 개의 인덱스 — 메모리 유형별로 하나씩 — 는 각기 자체 기록률, 노화 규칙, 업데이트 규칙을 따르게 하여 서로를 결합하지 않게 합니다.
이 세 가지와 함께 네 번째 검색 표면도 존재합니다: Elasticsearch에 이미 존재하는 세계 데이터(카탈로그, 지식 베이스). 이는 인지적 의미에서 “기억”이 아니지만, 다음 섹션에서 설명한 동일한 하이브리드 리콜 파이프라인을 통해 에이전트가 읽습니다. 따라서 같은 그림에 포함됩니다.
리콜 파이프라인: 하이브리드 검색 + RRF와 리러ンキнг
메모리는 두 단계 하이브리드 검색을 통해 회상됩니다: RRF를 이용한 BM25 + Jina v5 밀도 벡터, 그다음에 합쳐진 후보자들에 대한 크로스-인코더 리러ンキнг. 각 문서는 한 번의 기록으로 두 가지 방식으로 인덱싱됩니다: 원본 텍스트는 BM25 반전 인덱스에 저장되고, copy_to를 사용해 동일한 값을 semantic_text 필드에 자동 생성하는 Jina v5 벡터로 라우팅합니다. 같은 내용을 두 번 인덱싱하면 저장량이 평평해집니다: 한 source-of-truth 기록은 양쪽 리콜 레그(index mapping)를 생성합니다. 각 레그는 별개의 문제를 해결합니다. BM25는 에이전트가 재구성한 문장(paraphrase)으로 사라지는 문자열 매치(버전 번호, 오류 코드, “Lumio Hub v2”와 같은 고유명사)를 앵킹합니다. 밀도 벡터는 답변이 다른 단어를 사용하는 질문 형태의 의미를 포착합니다. 각각의 레그만으로는 상충하는 경우를 놓치지만, RRF는 BM25 점수를 코시 유사성과 비교해 교정하지 않고 랭킹을 융합합니다.
과잉 가져오기. 리러ンキング은 자신이 보는 후보자들만 재정렬할 수 있으므로, 후보 풀은 충분히 넓어야 합니다. 하이브리드 검색기는 각 레그당 80개의 후보를 가져와 rank_constant=30(ES 기본값인 60보다 더 가늘게, 즉 상위 항목이 더 우세하게 지배) 로 RRF 융합합니다. (_rrf_fetch)
리러ンキнг. Jina v2 크로스-인코더는 합쳐진 후보자들을 사용자 쿼리와 비교해 점수를 매깁니다. BM25와 bi-encoder 밀도 벡터는 각각 쿼리와 문서를 독립적으로 평가하지만, 크로스-인코더는 쌍을 전체 주목하면서 공동으로 점수를 부여하여 더 강력한 관련성 신호를 제공합니다(이는 높은 per-pair 비용에서 유리). 이것이 두 단계 파이프라인의 동기: 하이브리드 검색기로 저렴하게 과잉 가져오고, 비싼 스코어러로 소규모 후보 풀을 리러ンキング합니다.(_rerank)
위 다이어그램에 표시된 미묘한 점은, 에이전트의 툴킷에 recall_memory가 포함되어 있으며(tools.py) 정의되어 있습니다.