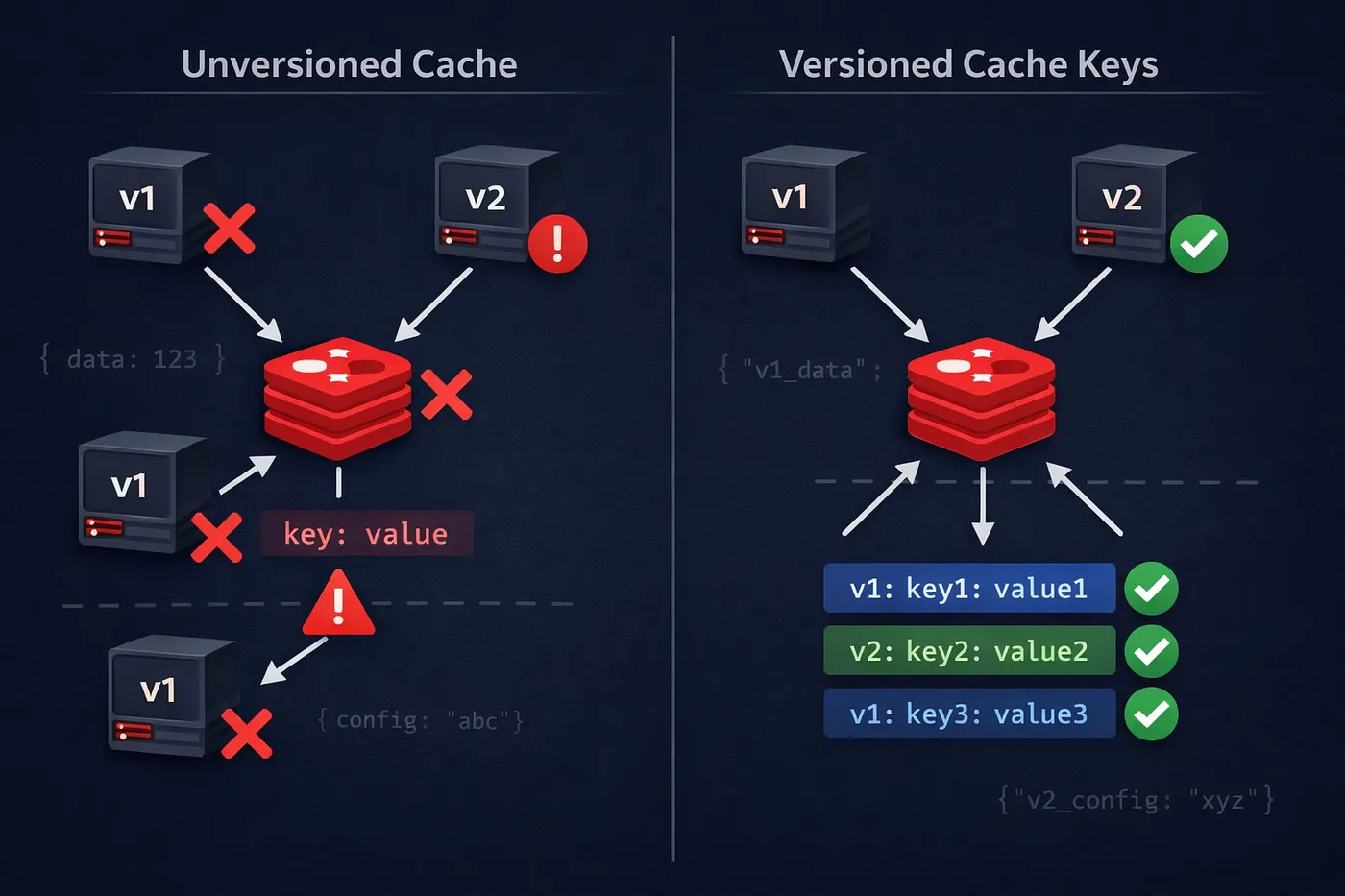
Cache Keys에 버전을 지정하지 않으면 Rolling Deployments가 깨집니다
Source: Dev.to
개요
롤링 배포는 서비스의 여러 버전을 동시에 실행하면서 다운타임 없이 운영할 수 있도록 설계되었습니다. 대부분의 팀은 API와 데이터베이스 계층에서 호환성을 고려하지만, 버전이 조용히 상호 작용하는 또 다른 장소가 있습니다: 캐시.
우리는 실제 운영 중 롤아웃에서 이 문제를 겪었으며, 해결책은 사고 자체보다도 더 간단했습니다.
사고
프로덕션 배포가 롤아웃 도중에 실패하기 시작했습니다.
- 로그에 역직렬화 오류가 나타났습니다
- 요청 지연 시간이 증가했습니다
- 오류 비율이 상승했습니다
트리거가 된 변경은 아주 작았습니다: 모델 클래스의 단일 필드 이름을 바꾼 것이었습니다.
이는 뒤로 호환되지 않는 변경이었습니다. 일반적으로 이런 변경은 피해야 하지만, 다른 팀이나 외부 시스템이 소유한 스키마를 사용할 때는 불가피할 때도 있습니다.
우리는 하위 서비스가 깨지지 않도록 필요한 변경을 수행했고, 통합 테스트가 통과하도록 업데이트했습니다. API 계약 변경도 없었고 데이터베이스 마이그레이션도 없었습니다. 외부 의존성 관점에서는 이 변경이 안전해 보였습니다.
우리가 예상하지 못한 것은 캐시였습니다.
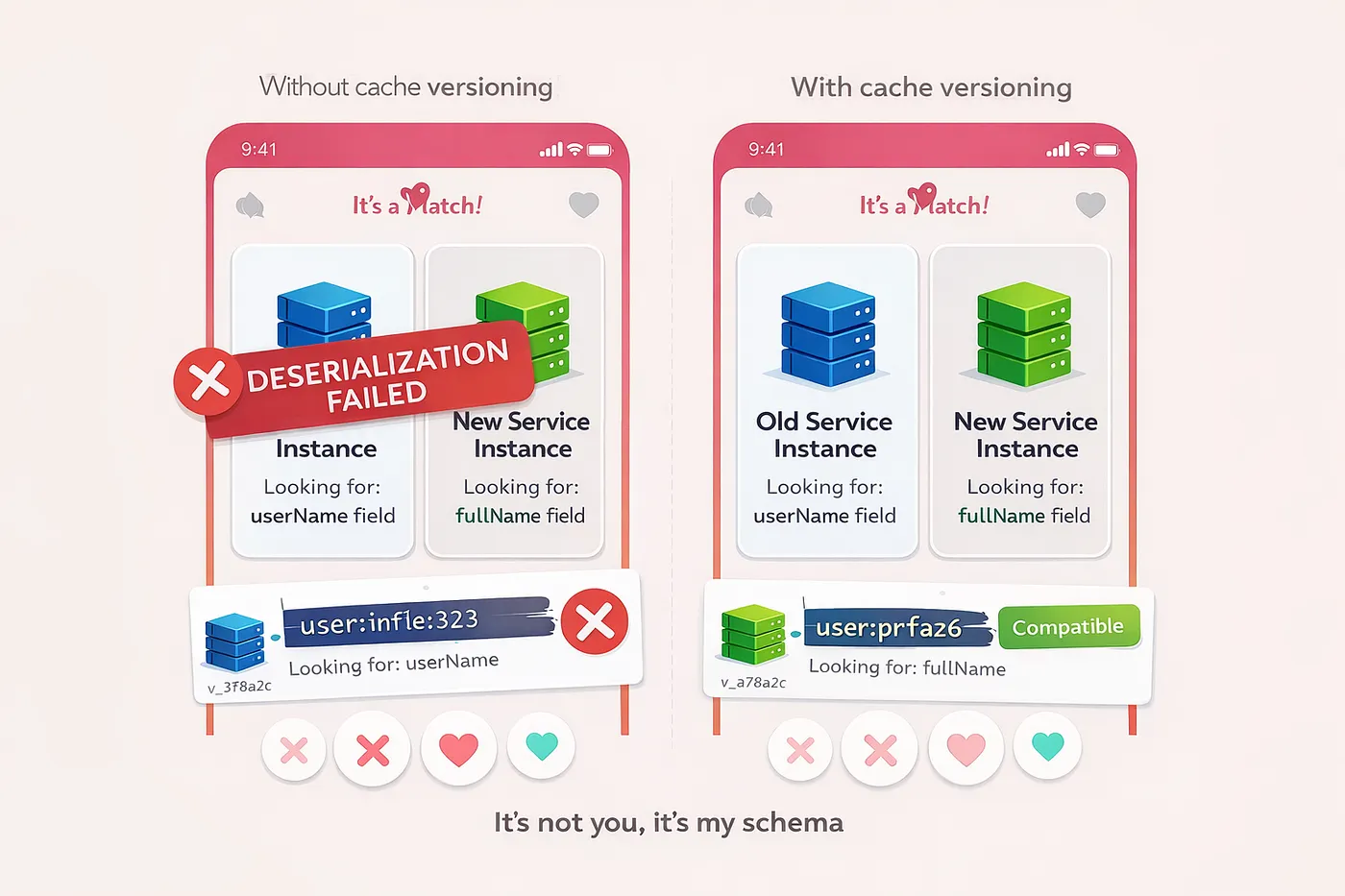
이 서비스는 데이터 집계기였습니다. 상위 데이터를 소비하고, 이를 보강한 뒤 결과를 하위로 전파했습니다. 영구 저장소를 소유하고 있지는 않았습니다. 하지만 롤링 배포 중에 두 버전의 서비스가 동시에 실행되면서, 새 인스턴스가 이전 인스턴스가 기록한 캐시 데이터를 역직렬화하지 못했고, 이전 인스턴스는 새 인스턴스가 기록한 데이터에서 실패했습니다.
이는 우리의 통합 테스트에서 잡히지 않은 문제였습니다. 여러 서비스 버전이 동시에 살아 있을 때 롤아웃 중에만 문제가 드러났습니다.
실패는 우리의 API, 데이터베이스 계층, 혹은 하위 의존성에 있던 것이 아니라
공유 캐시에 있었습니다.
이 문제가 존재하는 경우(그리고 존재하지 않는 경우)
The issue doesn’t apply to every architecture.
이 문제는 모든 아키텍처에 적용되는 것은 아닙니다.
If your cache is:
- Local
- 로컬
- In‑memory
- 인메모리
- Scoped per instance or per host
- 인스턴스 또는 호스트당 범위 지정
then each service version only sees data it wrote itself, and schema changes are naturally isolated.
그러면 각 서비스 버전은 자신이 기록한 데이터만 보게 되며, 스키마 변경은 자연스럽게 격리됩니다.
The problem appears only when all of the following are true:
- The cache is shared or distributed (Redis, Memcached, etc.)
- 캐시가 공유되거나 분산되어 있음(Redis, Memcached 등)
- Multiple service versions run simultaneously
- 여러 서비스 버전이 동시에 실행됨
- Those versions read and write the same cache entries
- 해당 버전들이 동일한 캐시 엔트리를 읽고 씀
In other words: rolling deployments + shared cache.
다시 말해: 롤링 배포 + 공유 캐시.
If that’s your setup, this failure mode isn’t rare — it’s inevitable.
만약 여러분의 환경이 그렇다면, 이 실패 모드는 드문 것이 아니라 필연적입니다.
실제로 잘못된 점
대부분의 팀은 캐시를 내부 최적화로 간주합니다. 하지만 공유 캐시는 공유 상태이며, 독립적으로 배포된 버전 간의 공유 상태는 사실상 계약과 같습니다.
롤링 배포 중에 캐시는 단일 서비스 버전보다 오래 살아남습니다. 오래된 코드와 새로운 코드가 동시에 캐시와 상호 작용합니다.
간소화된 타임라인
14:23:01 - Deployment starts, new instances come up
14:23:15 - Old instance writes: {"userId": 123, "userName": "alice"}
14:23:18 - New instance reads same key, expects: {"userId": 123, "fullName": "alice"}
14:23:18 - Deserialization fails
14:23:19 - New instance writes: {"userId": 456, "fullName": "bob"}
14:23:20 - Old instance reads same key, expects: {"userId": 456, "userName": "bob"}
14:23:20 - Deserialization fails필드 이름을 바꾸는 것이 깨지는 변경을 도입했습니다 — API 레이어가 아니라 캐시 레이어에서 발생했습니다.
일반적인 대안이 잘 확장되지 않는 이유
이러한 상황이 발생하면 팀은 보통 다음 중 하나를 고려합니다:
- 배포 중 트래픽을 일시 중지하거나 배출하기
- 전체 캐시를 플러시하기
- 팀 간에 긴밀하게 타이밍을 맞춘 릴리스 조정하기
이 모든 방법이 작동할 수는 있지만 운영 부담을 증가시키고 배포 유연성을 감소시킵니다. 또한 시스템과 팀이 성장함에 따라 잘 확장되지 않습니다.
우리는 롤링 배포를 다시 지루하게 만들 수 있는 해결책을 원했습니다.
The Solution: Version Your Cache Keys
Instead of using cache keys like this:
user:123we added an explicit version prefix:
v1:user:123
v2:user:123Each service version reads and writes only the keys that match its own version.
That’s it.
캐시‑키 버전 계산 방법
캐시‑키 버전 관리와 관련된 한 가지 미해결 질문은 버전 자체를 어떻게 관리하느냐입니다.
버전 번호를 하드코딩하거나 수동으로 올리는 방법도 가능하지만, 잊어버리기 쉽고 절차적인 부담이 추가됩니다. 우리는 버전 관리가 자동적이고 투명하기를 원했습니다.
우리의 접근 방식은 캐시되는 모델 클래스의 구조에서 직접 버전을 도출합니다:
- 리플렉션을 사용해 모델 클래스를 검사합니다.
- 구조적 형태를 추출합니다:
- 필드 이름
- 필드 타입
- 중첩 객체(재귀적으로)
- 해당 형태의 정규화된 표현을 생성합니다.
- 그 표현에 해시를 계산합니다.
- 해시를 캐시 키의 버전 식별자로 사용합니다.
버전이 실제 데이터 스키마에 연결되어 있기 때문에, 필드 이름을 바꾸거나, 필드를 추가/제거하거나, 타입을 변경하는 등 어떤 변화가 있더라도 자동으로 새로운 버전이 생성되어 인간 실수 위험을 없앨 수 있습니다.
핵심 요약
- 공유 캐시는 롤링 배포 중 서비스 버전 간의 계약이 됩니다.
- 버전이 지정되지 않은 캐시 키는 스키마가 진화할 때 역직렬화 실패를 일으킬 수 있습니다.
- 간단한 키 버전 관리(
v1:…,v2:…)는 각 버전의 데이터를 격리합니다. - 모델 구조에서 버전을 파생하면 프로세스가 자동이며 실패 방지됩니다.
캐시를 버전이 지정된 계약으로 취급하면 롤링 배포가 원활하게 진행되고, 팀은 비용이 많이 드는 조정 없이도 자유롭게 반복 작업을 할 수 있습니다.
Source:
캐시 키에 대한 해결책
버전은 모델 구조에서 파생됩니다:
- 구조가 변경되면(필드 이름 변경, 타입 변경, 필드 추가 또는 제거) 새로운 버전이 생성됩니다.
- 모델에 아무 변화가 없으면 버전은 동일하게 유지됩니다.
- 버전 상승은 자동으로 발생하며 필요할 때만 이루어집니다.
버전은 전역이 아니라 모델 클래스당 적용됩니다. 각 캐시된 모델은 독립적으로 진화합니다.
개념적으로, 캐시 키는 다음과 같은 형태를 가집니다:
<version>:<model>:<id>이렇게 하면 모델 구조가 변경될 때마다 투명하게 버전이 상승하며, 개발자가 리팩터링 중에 캐시 버전을 직접 업데이트해야 하는 부담이 사라집니다.
예시 (Java)
아래는 리플렉션을 사용해 클래스 구조에서 안정적인 해시를 도출하는 간단한 예시입니다:
import java.lang.reflect.Field;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.util.*;
import java.util.stream.Collectors;
public class RecursiveCacheVersioner {
public static String getVersion(Class<?> rootClass) {
// 순환 종속성에 대한 무한 재귀를 방지하기 위해 Set 사용
String schemaBuffer = buildSchemaString(rootClass, new HashSet<>());
return hashString(schemaBuffer);
}
private static String buildSchemaString(Class<?> clazz, Set<Class<?>> visited) {
// 기본 사례: 이미 본 클래스이거나 기본 타입이면 이름만 반환
if (isSimpleType(clazz) || visited.contains(clazz)) {
return clazz.getCanonicalName();
}
visited.add(clazz);
StringBuilder sb = new StringBuilder();
sb.append(clazz.getSimpleName()).append("{");
// 해시가 결정적이도록 필드를 정렬
List<Field> fields = Arrays.stream(clazz.getDeclaredFields())
.sorted(Comparator.comparing(Field::getName))
.collect(Collectors.toList());
for (Field field : fields) {
sb.append(field.getName()).append(":");
// 재귀 단계: 필드가 다른 모델이면 그 구조 문자열도 가져옴
sb.append(buildSchemaString(field.getType(), visited));
sb.append(";");
}
sb.append("}");
return sb.toString();
}
private static boolean isSimpleType(Class<?> clazz) {
return clazz.isPrimitive()
|| clazz.getName().startsWith("java.lang")
|| clazz.getName().startsWith("java.util");
}
private static String hashString(String input) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hash = digest.digest(input.getBytes(StandardCharsets.UTF_8));
// Java 17+ 네이티브 16진수 포맷팅
return HexFormat.of().formatHex(hash).substring(0, 8);
} catch (Exception e) {
return "default";
}
}
}제너레이터가 보는 내용:User 클래스에 Address 객체가 포함된 경우, 빌더는 다음과 같은 정규화 문자열을 생성합니다:
User{address:Address{city:String;zip:String;};id:int;name:String;}이 문자열을 해시하여 버전 접두사를 만듭니다.
언어 지원에 대한 참고
이 접근 방식은 런타임에 타입 정보를 얻을 수 있는 강타입 언어(예: Java, Kotlin, C#)에서 가장 효과적입니다. 리플렉션을 통해 모델 구조를 신뢰성 있게 검사하고 안정적인 버전을 도출할 수 있습니다.
런타임 타입 정보가 제한적이거나 암시적인 JavaScript와 같은 동적 언어에서는 동일한 기법을 적용하려면 명시적인 스키마 정의, 스키마 버전 관리, 혹은 빌드 타임 코드 생성과 같은 다른 접근이 필요할 수 있습니다. 기본 아이디어는 동일하지만 구현 세부 사항은 달라집니다.
성능에 대한 참고
캐시 키 버전은 서비스 시작 시 모델 클래스당 한 번 계산되며, 매 캐시 읽기·쓰기 시마다 계산되지 않습니다. 따라서 런타임 오버헤드는 무시할 수준이며, 캐시 작업은 기존과 동일하게 빠르게 유지됩니다. 버전 계산은 pa
초기화의 일부; 정상 상태 요청 처리에는 영향을 주지 않습니다.
왜 이 접근 방식이 잘 작동하는가
캐시 키에 버전을 부여하면 롤링 배포 중에 이전 버전과 새로운 버전이 안전하게 공존할 수 있습니다. 각 버전은 자신이 이해할 수 있는 데이터만 읽고 쓰므로, 호환되지 않는 표현이 충돌하지 않습니다.
결과
- 배포 중에 캐시를 플러시할 필요가 없습니다.
- 다른 팀과의 조정이 필요하지 않습니다.
- 파괴적인 스키마 변경은 버전별로 격리됩니다.
- 이전 버전과 새로운 버전이 오류 없이 나란히 실행될 수 있습니다.
버전은 모델 구조에서 자동으로 파생되므로 수동으로 버전을 관리할 필요가 없습니다. 모델을 변경하는 리팩터링은 호환되지 않는 캐시 항목을 자연스럽게 무효화하고, 호환 가능한 변경은 불필요한 캐시 교체를 일으키지 않습니다.
배포가 완료되면 오래된 버전은 캐시 접근을 중단하고, 해당 항목은 TTL에 따라 자연스럽게 만료됩니다. 이제 캐시는 원래 호환되지 않아야 할 버전 간의 호환성을 강제하지 않습니다.
이 접근법이 특히 유용한 경우
- 여러 서비스 인스턴스 간에 공유 캐시를 사용합니다.
- 롤링 업데이트를 사용하여 자주 배포합니다.
- 업스트림 스키마를 완전히 제어하지 못합니다.
- 다양한 서비스가 독립적으로 진화할 수 있는 집계자 또는 마이크로서비스 아키텍처를 운영합니다.
Middleware Services
우리의 경우, 이는 상위 제공자 팀이 캐시 동작을 우리와 조정하지 않고도 변경을 할 수 있게 하면서, 우리 쪽에서는 배포를 안전하게 유지할 수 있게 했습니다.
트레이드오프 및 제한 사항
대부분의 아키텍처 결정과 마찬가지로, 캐시 키 버전 관리에도 사전에 이해해 두어야 할 트레이드오프가 있습니다.
캐시 내 다중 버전
롤링 배포 중에는 동일한 논리 객체의 여러 버전이 동시에 캐시에 존재할 수 있습니다. 우리 경우 배포 시간은 15분 정도이며, 1시간 TTL을 사용했기 때문에 짧은 기간 동안 캐시 엔트리 수가 약 두 배가 되었습니다.
일시적인 캐시 사용량 증가
이 방법은 안전성을 위해 메모리를 희생합니다. 우리에게는 영향이 작았으며, 배포 중 캐시 사용률이 **~45 %에서 ~52 %**로 증가했다가 오래된 엔트리가 만료되면 정상 수준으로 돌아왔습니다.
모든 환경에 적합하지 않음
캐시 메모리가 매우 제한적이거나, 배포 중에 버전 간 일관성을 엄격히 유지해야 하는 시스템이라면 이 접근 방식은 적합하지 않을 수 있습니다.
전환 중 의도적인 캐시 미스
새 버전은 첫 접근 시 캐시 미스가 발생하고 값을 재계산합니다. 이는 예상된 동작이며 의도된 것입니다—호환되지 않는 데이터를 역직렬화하려는 시도보다 안전합니다. 캐시 TTL과 캐시 미스 경로는 이에 맞게 설계되어야 합니다.
얻는 것: 보다 안전한 롤링 배포, 간단한 운영 행동, 스키마 변경 시 위험 감소.
포기하는 것: 배포 중 일부 캐시 효율성 감소.
우리에게는 그 트레이드오프가 충분히 가치 있었습니다.
캐시를 위한 더 나은 사고 모델
캐시는 종종 구현 세부 사항으로 취급됩니다. 실제로 공유 캐시는 시스템의 런타임 계약의 일부입니다.
여러 버전의 서비스가 동일한 캐시 데이터를 읽고 쓸 수 있다면, 캐시 호환성은 API 또는 스토리지 호환성만큼 중요합니다.
캐시 키에 버전을 지정하면 그 계약을 명확히 할 수 있습니다.
최종 요약
기본적으로 캐시 키에 버전을 지정하세요.
이는 신뢰성에 큰 영향을 미치는 작은 변화이며, 시스템이 진화함에 따라 배포를 예측 가능하게 유지합니다.