Java에서 고성능 인메모리 이벤트 브로커를 구축하기 위해 LMAX Disruptor 사용
I’m happy to translate the article for you, but I’ll need the full text you’d like translated. Could you please paste the content (or the portion you want translated) here? I’ll keep the source line unchanged and preserve all formatting, markdown, and code blocks as requested.
Introduction
나는 대부분의 시간을 데이터 분석, 엔지니어링, 파일 시스템 작업, 웹 프로젝트를 위한 Python 코드를 작성하는 데 사용하고, 동시성 모델이 더 단순하게 느껴지는 Go(또는 새로움을 위해 Rust)를 약간 섞어 사용한다. 나는 C로 프로그래밍을 시작했고, 예전에는 Java를 통해 OOP를 배웠다. JVM을 떠난 지 7년이 지나면서 무엇이 바뀌었는지 궁금해졌고, 성능이 중요한 무언가를 만들면서 다시 뛰어들기로 했다. 그 결과는 7 + million dispatches per second 를 노트북에서 처리하는 이벤트 라우터이며, 두 가지 주요 병목 현상인 락과 메모리 할당을 제거했다.
Why Java when Python and Go exist?
Python 개발자로서 나는 보통 이벤트 처리를 위해 PyPubSub이나 Blinker 같은 라이브러리를 사용한다. 이들은 I/O‑bound 애플리케이션에서는 잘 동작하지만, GIL( Python 3.14 이전 버전) 때문에 CPU‑집약적인 이벤트 처리에서는 어려움을 겪는다.
Go의 채널 기반 동시성 모델은 goroutine을 통해 이벤트를 우아하게 처리하고, EventBus 같은 라이브러리는 Go 생태계에서 자연스러운 pub‑sub 패턴을 제공한다. 그러나 두 생태계 모두 Disruptor 의 기계적‑공감 접근 방식과 직접적으로 대응되는 것이 없다.
- Python 인터프리터 오버헤드와 Go 가비지 컬렉터(Python보다 나은 편이지만) 모두 수백만 건의 이벤트당 지연을 초래한다.
- 이벤트당 몇 마이크로초가 곱해져 수백만 건이 되는 상황(금융 시스템, 실시간 분석, 게임 서버 등)에서는 Java의 성숙한 JIT 컴파일, 세밀하게 조정 가능한 GC 옵션, 그리고 CPU 캐시 동작을 활용하는 Disruptor 같은 라이브러리가 매치하기 어려운 성능을 제공한다.
Source: …
잠금 기반 전형적인 이벤트 버스
전형적인 이벤트 버스는 동기화 블록으로 감싼 큐를 사용합니다. 스레드 A가 이벤트를 게시하려고 할 때는 다음과 같이 진행합니다.
- 큐를 잠금합니다.
- 이벤트를 추가합니다.
- 큐의 잠금을 해제합니다.
스레드 B도 동일한 단계를 수행합니다. 처리량이 높아지면, 스레드들은 실제 작업을 수행하기보다 잠금 대기에 더 많은 시간을 소비하게 됩니다.
문제점
- 잠금 경쟁 – 빈번한 잠금/해제 사이클이 병목이 됩니다.
- CAS 오버헤드 – Java의
ConcurrentLinkedQueue조차도 비교·교환(compare‑and‑swap) 연산에 의존하는데, 이는 메모리 배리어와 추가 지연을 초래합니다. - 객체 할당 – 각 메시지마다 새로운
Event인스턴스를 생성하면 많은 가비지가 발생합니다. 초당 수백만 개의 이벤트가 발생하면 가비지 컬렉터가 지속적으로 실행되어 눈에 띄는 일시 정지를 일으킵니다.
The Ring Buffer
Disruptor는 본질적으로 원형 버퍼 자료구조를 매우 정교하게 적용한 것으로, 고정 크기의 배열이 끝에 도달하면 다시 처음으로 돌아가 슬롯을 재사용합니다. 자료구조와 알고리즘을 공부한 사람이라면 이 패턴을 한 번쯤은 접해봤을 텐데, Disruptor는 멀티스레드 이벤트 처리에 특화된 락‑프리 메커니즘으로 이를 최적화합니다.

Source: Wikipedia – Circular Buffer Animation
{kind=link}
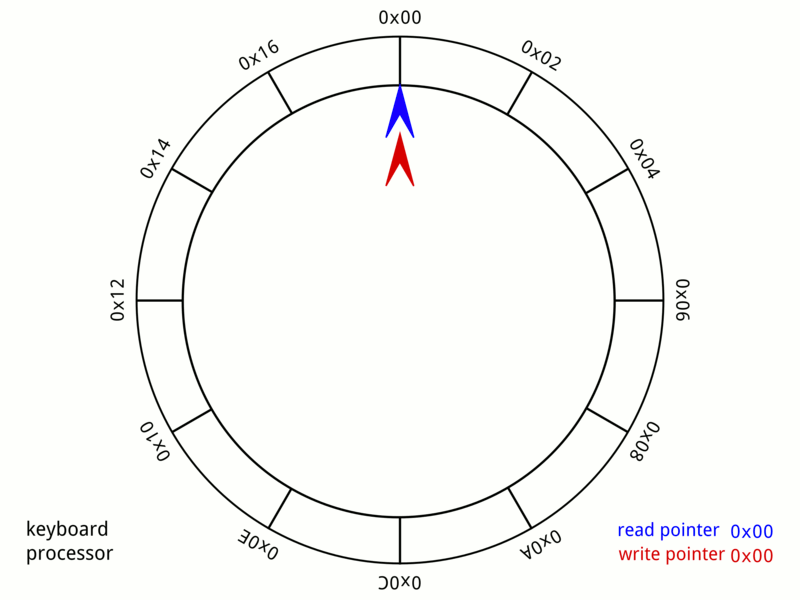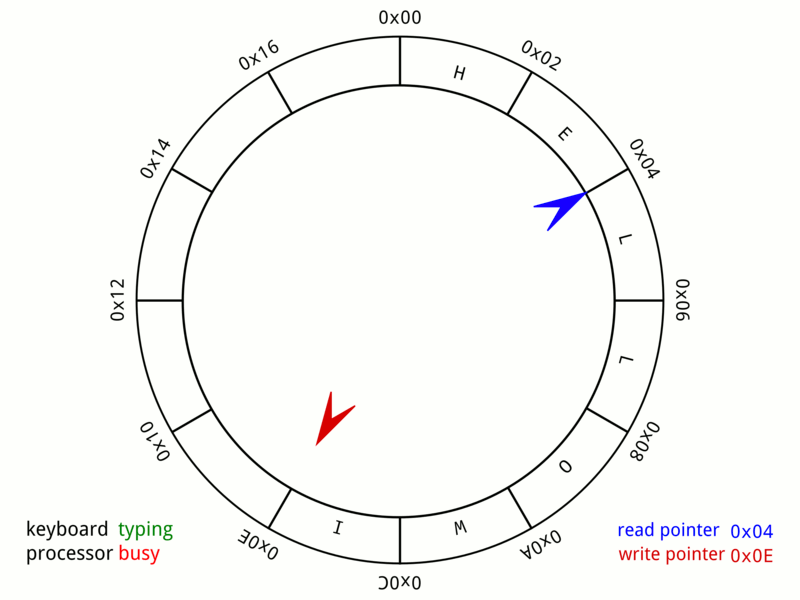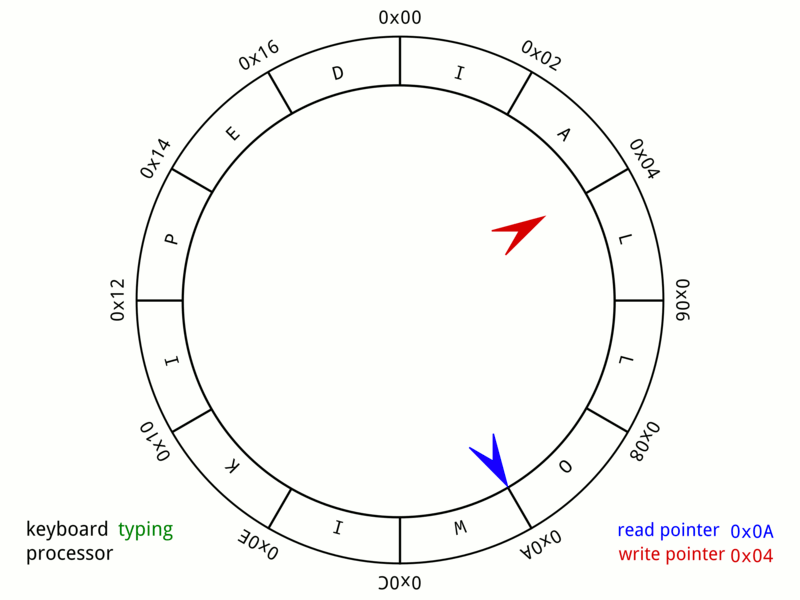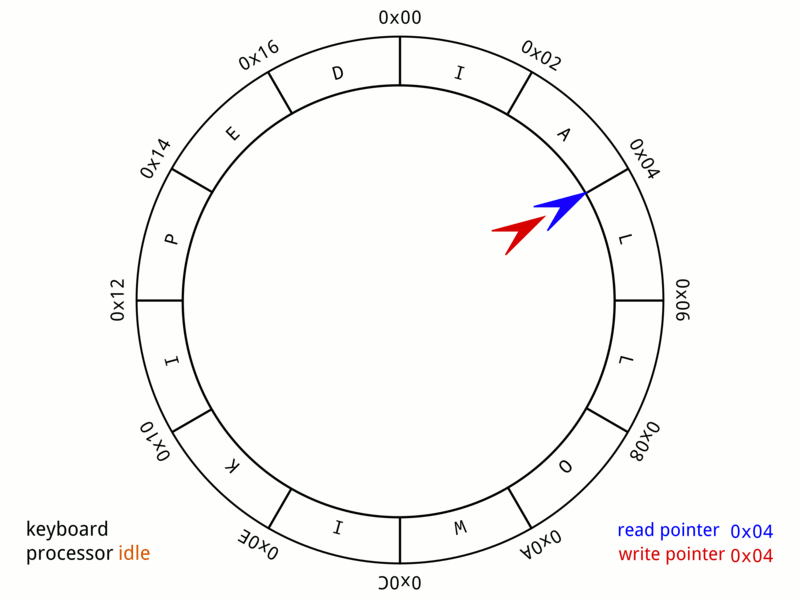
16 384개의 미리 할당된 Event 슬롯을 가진 원형 배열을 상상해 보세요. 퍼블리셔는 다음 사용 가능한 슬롯을 차지하고, 데이터를 직접 그 슬롯에 기록한 뒤, 준비가 되었다고 표시합니다.
- 락이 없습니다.
- 메모리 할당이 없습니다.
- 오직 원자적인 시퀀스 번호만이 누가 어디에 쓸지를 조정합니다.
생산자가 이벤트를 발행할 때는 ringBuffer.next()를 호출해 시퀀스 번호를 확보하고, ringBuffer.get(sequence)에 데이터를 복사한 뒤, 마지막으로 ringBuffer.publish(sequence)를 호출합니다. 여기서 “복사”란 새로운 객체를 생성하는 것이 아니라 기존 Event 인스턴스의 속성을 설정하는 것을 의미합니다.
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import org.jetbrains.annotations.NotNull;
/**
* A router is an event bus for subscribers to attach to and receive relevant events.
*/
public class EventRouter {
private final @NotNull Disruptor disruptor;
private final @NotNull RingBuffer ringBuffer;
/**
* Publish an event in the event bus.
*/
public void publish(@NotNull Event e) {
long sequence = this.ringBuffer.next();
try {
// The Event class has custom attributes: type, from, payload, timestamp.
Event bufferedEvent = ringBuffer.get(sequence);
bufferedEvent.setType(e.getType());
bufferedEvent.setFrom(e.getFrom());
bufferedEvent.setPayload(e.getPayload());
bufferedEvent.setTimestamp(e.getTimestamp());
} finally {
this.ringBuffer.publish(sequence);
}
}
}소비자는 발행된 시퀀스를 관찰하고 순서대로 처리합니다.
디스패치 전략
이벤트가 링 버퍼에 배치되면 라우터는 이를 모든 등록된 구독자에게 디스패치합니다. 각 이벤트 유형은 subscriber list(구독자 목록)를 유지하여 라우터가 해당 유형에 관심 있는 리스너를 빠르게 찾을 수 있도록 합니다. 이벤트가 도착하면 라우터는:
- 이벤트 유형에 대한 구독자 목록을 조회합니다.
- 각 구독자마다 스레드 풀에 디스패치 작업을 제출합니다.
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.jetbrains.annotations.NotNull;
/**
* Thread pool for dispatching events to subscribers.
* The pool size matches the number of available CPU cores, keeping the CPU busy
* without oversubscribing.
*/
private final ExecutorService DISPATCH_POOL =
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* Dispatch an event to all its subscribers.
*
* @param e the event to dispatch
* @param sequence the sequence number of the event in the ring buffer
*/
private void dispatch(@NotNull Event e, long sequence) {
// Retrieve the list of subscribers for the event's type.
List<Subscriber> subs = subscriberMap.get(e.getType());
if (subs == null || subs.isEmpty()) {
return; // No one is interested.
}
// Submit a dispatch task for each subscriber.
for (Subscriber sub : subs) {
DISPATCH_POOL.submit(() -> sub.handle(e, sequence));
}
}- 스레드 풀 크기 –
Runtime.getRuntime().availableProcessors()는 풀에 CPU 코어 수와 정확히 일치하는 스레드 수를 할당하여 불필요한 컨텍스트 전환을 방지합니다. - 제로 할당 디스패치 –
Event객체는 미리 할당되고 재사용되므로 디스패치는 메서드 호출과 최소한의 부가 작업만 포함하며 추가적인 가비지를 생성하지 않습니다.
결론
락‑프리 링 버퍼(Disruptor 패턴)와 가벼운 디스패치 스레드 풀을 결합함으로써 전통적인 이벤트 버스의 두 가지 주요 성능 저해 요인을 제거합니다:
- 락 경쟁
- 과도한 객체 할당
그 결과, 7 백만 건 이상의 디스패치를 초당 처리할 수 있는 이벤트 라우터가 보통 수준의 노트북에서도 구현되었으며, 이는 Java가 Python 및 Go와 함께 고처리량·저지연 환경에서도 여전히 매력적인 선택임을 증명합니다.
// See section “Copy‑on‑Write subscribers”
public void onEvent(Event e, boolean endOfBatch) {
SubscriberList holder = this.subscribers.get(e.getType());
if (holder == null) return;
var subs = holder.list;
if (subs.isEmpty()) return;
if (subs.size() == 1) {
subs.getFirst().onEvent(e);
} else {
for (Subscriber sub : subs) {
DISPATCH_POOL.submit(() -> sub.onEvent(e));
}
}
}스레드 풀 크기는 CPU 코어 수와 일치합니다. 이는 구독자 콜백을 여러 스레드에 걸쳐 병렬화하면서도 메인 링 버퍼 처리를 단일 스레드로 유지해 빠르게 동작합니다.
각 구독자는 자체 단일 스레드 실행기(onEvent)를 가지고 있어 들어오는 이벤트를 큐에 넣습니다. 이렇게 하면 구독자별 순서가 보장됩니다(이벤트 A가 먼저 발행되었다면 A가 B보다 먼저 처리됨) 동시에 하나의 느린 구독자가 다른 구독자를 차단하지 않게 됩니다.
/**
* A subscriber listens to a given number of event types in his scope's range.
*/
public abstract class Subscriber implements AutoCloseable {
/**
* This executor ensures events are processed one at a time, in the order they are received,
* without blocking the event router.
*/
@NotNull
private final ExecutorService exec = Executors.newSingleThreadExecutor();
/**
* Return the scope of this subscriber.
*/
@NotNull
public abstract Scope scope();
/**
* Process an event received from a router.
*/
protected abstract void processEvent(@NotNull Event e);
/**
* Send data to this subscriber. This is fast and does not block the caller.
*/
public final void onEvent(@NotNull Event e) {
this.exec.submit(() -> this.processEvent(e));
}
@Override
public void close() throws TimeoutException, InterruptedException {
this.exec.shutdown();
if (!this.exec.awaitTermination(1, TimeUnit.MINUTES)) {
throw new TimeoutException("subscriber's executor thread termination timed out");
}
}
}WaitStrategy 선택
Disruptor는 새로운 이벤트가 없을 때 소비자가 어떻게 동작할지를 제어하는 여러 대기 전략을 제공합니다.
| 전략 | 동작 |
|---|---|
BlockingWaitStrategy | 잠금을 사용합니다; CPU 친화적이지만 지연 시간이 늘어납니다. |
BusySpinWaitStrategy | 빡빡하게 스핀합니다; 가능한 가장 낮은 지연 시간을 제공하지만 CPU를 100 % 사용합니다. |
SleepingWaitStrategy | 점진적으로 대기 시간을 늘립니다; CPU 사용량과 합리적인 지연 시간 사이의 균형을 맞춥니다. |
YieldingWaitStrategy | 유휴 시 Thread.yield()를 호출합니다; 낮은 지연 시간을 유지하면서 완전한 스핀을 피합니다. |
저는 **YieldingWaitStrategy**를 선택했습니다. 이는 대기 중에 낭비적인 CPU 사용을 피하면서도 낮은 지연 시간을 제공하기 때문입니다. 이벤트가 급증했다가 가끔 조용해지는 시스템에서는, Yielding이 CPU를 고정시키지 않으면서도 좋은 처리량을 제공합니다.
이 실험적 이벤트 버스의 추가 기능
범위 기반 보안
이벤트는 네 가지 범위 수준을 가집니다:
| 범위 | 가시성 |
|---|---|
PUBLIC | 원격 액터에게 표시됩니다 |
FEDERATED | 신뢰된 서버에게 표시됩니다 |
PRIVATE | 로컬 신뢰 액터에게 표시됩니다 |
ROOT | 전체 접근 권한을 가집니다 |
컴포넌트는 자신의 범위 수준과 같거나 그 이하인 이벤트와만 상호 작용할 수 있습니다.
- 등록 – 이벤트 타입을 등록할 때 해당 범위를 지정해야 합니다.
- 구독 – 라우터는 구독자의 범위가 요청된 이벤트 타입에 대해 충분히 넓은지 확인합니다.
- 발행 – 라우터는 이벤트 타입이 존재하는지 확인한 뒤에 디스패치합니다.
EventRegistry는 ConcurrentHashMap에 등록된 이벤트와 그 범위를 저장합니다. 조회는 해시 테이블 읽기 하나로 이루어지며, 마이크로초 수준의 오버헤드만 추가됩니다.
복사‑쓰기 구독자
각 이벤트 타입은 불변 List를 보유하는 SubscriberList에 매핑됩니다. 새 구독자가 등록되면 라우터는 추가된 구독자를 포함하는 새로운 리스트를 만들고 이를 원자적으로 교체합니다.
- 읽기는 동기화 없이 일관된 스냅샷을 봅니다.
- 쓰기는 리스트 복사 비용을 지불하지만, 구독은 디스패치에 비해 드물게 발생합니다.
이 설계는 핫 경로(디스패치) 를 최적화하고 콜드 경로(구독) 에 비용을 전가합니다.
벤치마크 결과
벤치마크는 4개의 프로듀서 스레드를 생성하고, 각각 250 000개의 이벤트를 5개의 이벤트 타입에 걸쳐 발행합니다. 각 타입당 4명의 구독자가 있어 총 4 M개의 디스패치 연산(1 M 이벤트 × 4 구독자)이 수행됩니다.
| 머신 | 평균 시간 (50회 실행) | 초당 디스패치 |
|---|---|---|
| Intel Core i7‑13600H, 16 GB RAM | 922 ms | 4.34 M |
| Intel Core Ultra 7‑155H, 32 GB RAM | 528 ms | 7.58 M |
이 수치는 가벼운 문자열 페이로드와 단순히 카운터를 증가시키는 구독자를 사용하여 얻은 것입니다. 실제 처리량은 구독자가 이벤트를 어떻게 처리하느냐에 따라 달라지지만, 라우터 자체는 최소한의 지연만을 추가합니다. Disruptor 라이브러리는 이보다 더 높은 성능을 달성할 수 있다고 광고하고 있습니다.
이 실험용 이벤트 버스가 하지 않는 것
- 이벤트 유형 외에 필터링 없음.
- 와일드카드, 콘텐츠 기반 라우팅, 또는 우선순위 큐 없음.
- 보장된 전달 없음 – 구독자가 너무 뒤처져 링 버퍼가 순환하면, 처리되지 않은 오래된 이벤트가 덮어쓰기 됩니다.
- 기본 링 버퍼는 16 K 슬롯을 보유합니다; 16 K 이벤트 이상 뒤처지면 손실이 발생할 수 있습니다.
- 영구 저장 없음 – 이벤트는 메모리 내에만 존재합니다. 프로세스가 충돌하면 진행 중인 모든 이벤트가 사라집니다. 이는 인‑프로세스 이벤트 버스로, Kafka와 같은 내구성 있는 메시지 큐가 아닙니다.
- 백프레시어 없음 – 구독자당 단일 스레드 실행기는 느린 구독자가 큐를 쌓게 만들며, 소비자가 따라가지 못해도 퍼블리셔는 제한되지 않습니다.
결론
Disruptor는 세계에서 가장 빠른 거래 플랫폼이 되기를 목표로 하는 거래 플랫폼인 LMAX에 의해 개발되었습니다. 이는 정교하게 설계된 링‑버퍼가 단일‑프로세스 환경에서 초저지연, 고처리량 이벤트 처리를 어떻게 제공할 수 있는지를 보여줍니다. 이 실험적인 버스는 그 기반 위에 구축된 실용적이고 범위가 제한된 복사‑쓰기 구현을 선보이며, 동시에 프로덕션‑급 메시징 시스템에 필요한 트레이드‑오프와 누락된 기능들을 강조합니다.
코드는 GitHub에서 확인할 수 있습니다.