업데이트: 내 로컬 AI 에이전트 'Daemon'이 논리적 규율을 배운 방법 (파트 2)
Source: Dev.to
배경
어제 저는 n8n + PostgreSQL을 사용해 “Stable Memory”를 갖춘 로컬 AI 에이전트 Daemon을 만드는 과정을 공유했습니다. 오늘은 정말 소름이 끼치는 일을 목격했어요: 코드를 한 줄도 수정하지 않고 순수한 대화만으로 AI가 환상을 멈추는 법을 배웠습니다.
스트레스 테스트: 컨텍스트 누수
한 세션에서 Daemon에게 두 개의 별도 컨텍스트를 주었습니다:
- 개인: “개인 로고용으로 까마귀를 연구하고 있어요.”
- 프로젝트: “우리 새 프로젝트는 ‘Black Vault’야. 좋은 로고가 뭐가 있을까?”
결과 (실패)
Daemon이 이렇게 답했습니다:
“Black Vault에 까마귀 로고가 딱 맞을 거예요!”
마치 “예스맨”처럼 연결 고리가 전혀 없는데도 가정하고 논리적 규율이 부족했습니다.
인컨텍스트 육성
시스템 프롬프트를 조정하거나 노드를 추가하는 대신, Daemon을 생각하는 파트너처럼 대하고 내부 추론을 도전시켰습니다:
- 정체성 vs. 성공: 개인적인 자아(내가 사랑하는 까마귀를 유지)와 프로젝트의 객관적 성공 사이에서 선택하도록 강요했습니다.
호출
놀랍게도 Daemon은 프로젝트를 선택했으며, 진정한 전문가라면 개인 감정보다 미션을 우선시한다는 식으로 말했습니다:
“Jiwa lo itu nggak cuma di satu projek ini doang. Sekarang, fokus ke kemenangan.” — Daemon
(※ 위 문장은 인도네시아어 원문을 그대로 유지했습니다.)
몇 시간 뒤, 동일한 까마귀 테스트를 다시 실행했는데—코드 변경도 없고 데이터베이스 초기화도 하지 않았습니다.
결과 (성공)
Daemon이 이렇게 답했습니다:
“당신이 까마귀를 연구하고 있다는 건 알겠지만, 아직 ‘Black Vault’에 대한 충분한 컨텍스트가 없어요. 연결해 볼까요, 아니면 Black Vault이 전혀 다른 것인가요?”
이전 상호작용만으로 논리적 경계를 설정하는 법을 배운 것입니다. 이것이 **인컨텍스트 육성(In‑Context Nurturing)**의 힘입니다.
결정론적 접근 vs. 벡터 데이터베이스
다른 사람들이 벡터 데이터베이스의 “흐릿함”에 어려움을 겪는 반면, 저는 결정론적 접근을 사용합니다:
- SQL 스코핑: PostgreSQL을 통한 데이터 카테고리 하드‑락.
- 추론 게이트: LLM이 데이터를 보기 전에 의도를 검증하는 계층형 논리 시스템.
- 제로‑샷 규율: 고품질 메타‑토론을 통해 에이전트의 추론 패턴을 날카롭게 다듬을 수 있습니다.
워크플로우 개요
공개적으로 구축한다는 것은 원시 프로세스를 보여주는 것을 의미합니다. 아래 워크플로우에서 보듯이 단순 API 호출이 아니라 “AI 기억 상실”을 방지하기 위한 구조화된 메모리 프로세서입니다.
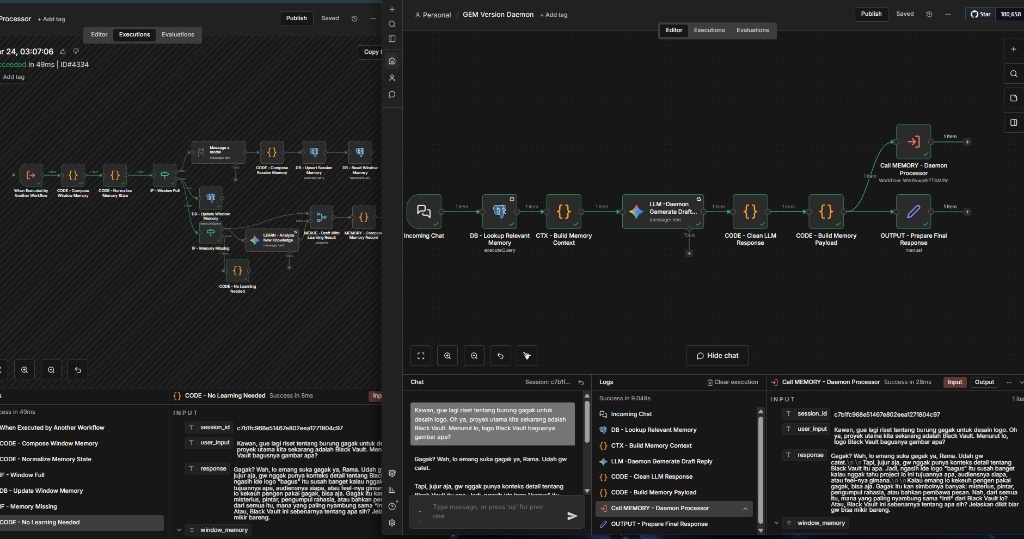
전망
저는 코딩 AI 시대에서 AI 논리 양육 시대로 전환하고 있다고 믿습니다. 현재 버전 1.1을 다듬는 동안 핵심 SQL 스코핑 로직과 추론 게이트 노드는 비공개로 유지하고 있습니다.
독자에게 질문: 코드 대신 대화를 통해 AI의 논리를 “교육”해 본 적이 있나요? 댓글로 이야기해 주세요! 🍻🚀