Power BI에서 스키마와 데이터 모델링 이해
I’m happy to translate the article for you, but I need the text you’d like translated. Could you please paste the content (or the portion you want translated) here? I’ll keep the source link at the top and preserve all formatting, markdown, and technical terms as requested.
소개
Power BI는 Microsoft에서 개발한 비즈니스 인텔리전스 및 데이터 시각화 도구로, 사용자가 여러 데이터 소스에 연결하고, 데이터를 변환·모델링하며, 보고서와 대시보드를 만들 수 있게 합니다. 이 기사에서는 Power BI의 다양한 스키마와 데이터 모델을 살펴보겠습니다.
스키마부터 시작해 봅시다.
스키마란 무엇인가?
Power BI에서 스키마는 데이터 모델 내 데이터의 구조와 조직을 의미하며, 데이터가 어떻게 연결되고 연관되는지를 정의합니다. 스키마를 이해함으로써 포괄적인 분석을 가능하게 하는 최적의 데이터 모델을 설계할 수 있습니다.
Power BI의 스키마 유형
1. 스타 스키마

스타 스키마는 하나의 중앙 Fact Table(사실 테이블) 주변에 Dimension Table(차원 테이블)들이 배치된 형태로, 별 모양을 이루게 됩니다.
- Fact Table – 측정 가능한 데이터(예: Sales)를 포함합니다.
- Dimension Table – 사실과 관련된 설명 속성(예: Customers, Date)을 보관합니다.
스타 스키마는 직관적인 보고와 질의에 적합하여 대시보드 및 요약 보고서에 이상적입니다.
2. 스노우플레이크 스키마
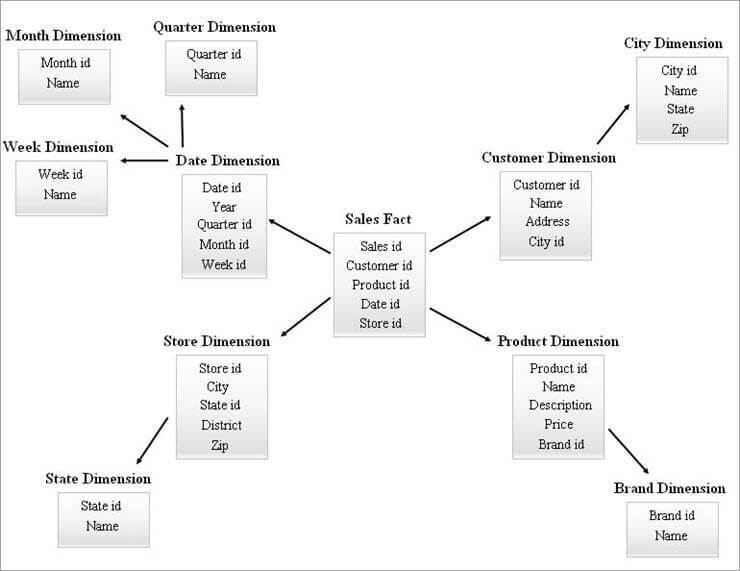
스노우플레이크 스키마는 스타 스키마를 확장한 형태로, 차원 테이블을 추가로 정규화하여 서브‑차원 테이블로 분리함으로써 눈송이 모양의 구조를 만들습니다.
예시: Products 차원을 Category와 Brand 테이블로 나눌 수 있습니다.
장점: 테이블 수와 조인이 늘어나 데이터 중복을 줄이고 저장 공간을 절약할 수 있습니다. 스노우플레이크 스키마는 저장소 최적화가 중요하고 상세한 데이터 모델이 필요한 경우에 적합합니다.
3. 갤럭시 스키마(Fact Constellation Schema)
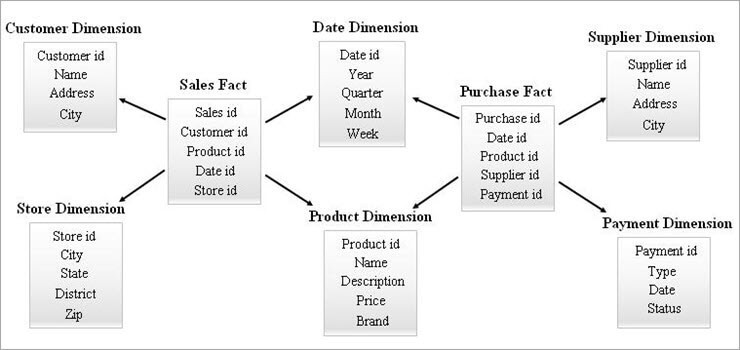
갤럭시 스키마(또는 Fact Constellation Schema)는 여러 개의 Fact Table이 동일한 Dimension Table을 공유하면서 복잡하고 상호 연결된 별자리 형태를 이루는 구조입니다.
갤럭시 스키마는 재무와 운영 분석처럼 다중 프로세스 또는 상호 연관된 메트릭 분석이 필요한 대규모 기업 환경에 적합합니다.
Power BI에서 스키마 구현 방법
a. 스타 스키마
- 사실 및 차원 테이블 설정 – 중앙 사실 테이블과 주변 차원 테이블을 식별하고 생성합니다.
예시: Sales 사실 테이블과 Product, Customer 차원 테이블. - 테이블 연결 – 외래 키를 사용하여 사실 테이블과 각 차원 테이블 간의 관계를 설정합니다.
예시:CustomerID외래 키를 통해 Sales를 Customer와 연결합니다.
b. 스노우플레이크 스키마
- 차원 테이블 정규화 – 차원 테이블을 관련 서브 테이블로 분할합니다.
예시: Product를 Category와 Brand 테이블로 분할합니다. - 관계 생성 – 서브 테이블과 메인 테이블 간의 관계를 정의하고 참조 무결성을 유지합니다.
예시: Customer를 City와 Region 테이블로 분할하고CityID를 통해 Customer 테이블과 연결합니다. - 스토리지 최적화 – 복잡한 조인을 효율적으로 관리하기 위해 적절한 스토리지 및 인덱싱 전략을 사용합니다.
c. 갤럭시 스키마
- 사실 테이블 식별 – 다양한 비즈니스 프로세스에 필요한 여러 사실 테이블을 결정합니다.
예시: Sales 사실 테이블과 Shipping 사실 테이블. - 공유 차원 테이블 식별 – 여러 사실 테이블에 공통으로 사용되는 차원 테이블을 결정합니다.
예시: Sales와 Shipping 모두 공유 Product 차원 테이블을 통해 연결될 수 있습니다.
데이터 모델링
데이터 모델링이란?
데이터 모델은 비즈니스를 위해 우리가 만드는 데이터의 구조를 말합니다. 데이터 모델링은 다양한 소스의 데이터를 일관된 의미 모델로 구조화하고 조직하는 과정으로, 다음을 수행합니다:
- 테이블 정의.
- 테이블 간 관계 설정.
- DAX를 사용하여 계산된 열 및 측정값 생성.
- 계층 구조 설정.
- 성능 최적화.
데이터 모델 유형
1. 개념 데이터 모델링
시스템이 포함할 내용, 조직 방식, 관련 비즈니스 규칙을 높은 수준에서 보여줍니다. 다음과 같은 질문에 답합니다:
- 어떤 데이터가 필요합니까?
- 비즈니스가 원하는 것은 무엇입니까?
- 어떤 데이터에 접근할 수 있습니까?
- 이 데이터를 어디에서 찾을 수 있습니까?
2. 논리 데이터 모델링
도메인 내 개념과 관계에 대한 더 자세한 정보를 제공합니다. 사실(예: 구매 이벤트)과 차원(예: 고객)을 포함하고 이들 간의 관계를 정의합니다.
3. 물리 데이터 모델링
데이터베이스에 데이터가 저장되는 방식을 설명합니다. 여기에는 테이블, 컬럼, 인덱스 및 저장 사양이 포함됩니다.
문서 끝.
물리적 데이터 모델
물리적 데이터 모델은 데이터가 데이터베이스 내에 물리적으로 저장되는 방식을 설명합니다. 관계형 데이터베이스로 구현할 수 있는 최종 설계를 제공합니다. 물리적 데이터 모델은 다음과 같은 질문에 답합니다:
- 데이터의 열은 무엇인가요?
- 데이터의 데이터 타입은 무엇인가요?
- 이 데이터를 어떻게 저장하고 있나요?
- 데이터를 압축하여 크기를 줄이려면 어떻게 해야 하나요?
데이터 모델링 프로세스
다음 작업 순서는 데이터 모델을 만들기 위해 반복적으로 수행됩니다.
-
엔터티 식별 – 모델링할 데이터 세트에 포함된 사물, 사건, 개념(엔터티)을 먼저 식별합니다.
-
각 엔터티의 핵심 속성 식별 – 각 엔터티는 하나 이상의 고유한 속성, 즉 속성(attribute) 으로 구분됩니다.
- 예시: 고객(Customer) 엔터티는 이름(First Name), 성(Last Name), 전화번호(Telephone Number) 와 같은 속성을 가질 수 있습니다.
- 예시: 주소(Address) 엔터티는 거리명 및 번호(Street Name & Number), 도시(City), 주(State), 국가(Country), 우편번호(ZIP Code) 를 포함할 수 있습니다.
-
엔터티 간 관계 식별 – 각 엔터티가 다른 엔터티와 어떤 관계를 갖는지 명시합니다.
- 예시: 고객은 주소에 거주한다(lives at).
-
속성을 엔터티에 완전하게 매핑 – 모델이 비즈니스에서 데이터를 활용하는 방식을 정확히 반영하도록 합니다.
-
키 할당 및 정규화 정도 결정 – 중복을 줄이는 필요성과 성능 요구 사항 사이의 균형을 맞춥니다.
Normalization 은 데이터를 조직하는 기법으로, 숫자 식별자(키)를 데이터 그룹에 할당하여 관계를 나타내고 데이터를 반복하지 않도록 합니다.
-
데이터 모델 최종 확정 및 검증 – 데이터 모델링은 반복적인 작업입니다. 비즈니스 요구가 변하면 모델을 다시 검토하고 다듬습니다.
데이터 모델링 유형
| # | Type | Description |
|---|---|---|
| 1 | Hierarchical data modeling | 각 레코드는 하나의 루트 부모를 가지고 있으며, 하나 이상의 자식 테이블에 매핑되어 트리‑형식 구조를 만듭니다. |
| 2 | Relational data modeling | 데이터 세그먼트가 테이블을 통해 명시적으로 조인되어 데이터베이스 복잡성을 감소시킵니다. |
| 3 | Entity‑relationship (ER) data modeling | 정식 다이어그램이 데이터베이스 내 엔터티 간의 관계를 나타냅니다. |
| 4 | Object‑oriented data modeling | 객체가 클래스 계층 구조로 그룹화되고 관련 기능을 가집니다. |
| 5 | Dimensional data modeling | 데이터 웨어하우스에서 분석 목적의 데이터 검색 속도를 최적화하도록 설계되었습니다. |
데이터 모델링을 수행하는 이유
데이터 모델링은 개발자, 데이터 아키텍트, 비즈니스 분석가 및 기타 이해관계자가 데이터베이스나 데이터 웨어하우스에 있는 데이터 간의 관계를 보다 쉽게 보고 이해할 수 있게 합니다. 또한 데이터 모델링은 다음과 같은 효과를 제공합니다:
- 소프트웨어 및 데이터베이스 개발 시 오류 감소.
- 애플리케이션 및 데이터베이스 성능 향상.
- 조직 전체의 데이터 매핑 용이화.
- 개발자와 비즈니스‑인텔리전스 팀 간의 커뮤니케이션 개선.
- 개념적, 논리적, 물리적 수준에서 데이터베이스 설계 프로세스 가속화.
결론
이 기사에서는 스키마와 데이터 모델링에 대해 다루었습니다. Power BI에서 다양한 스키마를 이해하는 것은 효율적인 데이터 모델을 설계하는 데 필수적입니다. 각 스키마는 고유한 장점을 가지고 있으며, 적절한 스키마를 선택함으로써 쿼리 성능, 데이터 저장 효율성 및 데이터 새로 고침 작업을 개선할 수 있습니다.
이러한 스키마를 마스터하면 견고하고 확장 가능한 데이터 모델을 구축할 수 있어 조직이 데이터 기반 의사결정을 효과적으로 내릴 수 있게 됩니다.
데이터 모델링은 효과적인 데이터 관리와 분석을 위한 중요한 기반입니다. 개념적, 논리적, 물리적 모델을 차례로 진행함으로써 조직은 높은 수준의 비즈니스 요구사항에서 상세하고 구현 가능한 데이터베이스 설계로 나아갈 수 있습니다.