Debezium과 함께 Change Data Capture 이해하기
Source: Dev.to
위 링크에 있는 전체 글을 번역하려면, 번역하고자 하는 **텍스트(마크다운 형식 포함)**를 제공해 주시겠어요?
코드 블록, URL, 그리고 마크다운 구문은 그대로 유지하면서 내용만 한국어로 번역해 드리겠습니다.
시스템 간 데이터 이동은 간단해 보이지만 – 그렇지 않을 때
애플리케이션이 성장함에 따라 팀은 하나의 데이터베이스에서 다른 데이터베이스로 데이터를 신뢰성 있게 복사하는 것이 겉보기보다 훨씬 어렵다는 것을 금방 깨닫게 됩니다. 업데이트가 누락되고, 삭제를 추적하기 어려우며, 시스템이 서서히 동기화가 깨집니다.
바로 여기서 Change Data Capture (CDC) 가 등장합니다.
이 글에서는 CDC가 무엇인지, 전통적인 접근 방식이 왜 실패하는지, 그리고 Debezium이 데이터 변화를 근본적으로 다른 방식으로 캡처하는 방법을 살펴보겠습니다.
오늘날 데이터가 일반적으로 이동되는 방식 (그리고 왜 실패하는가)
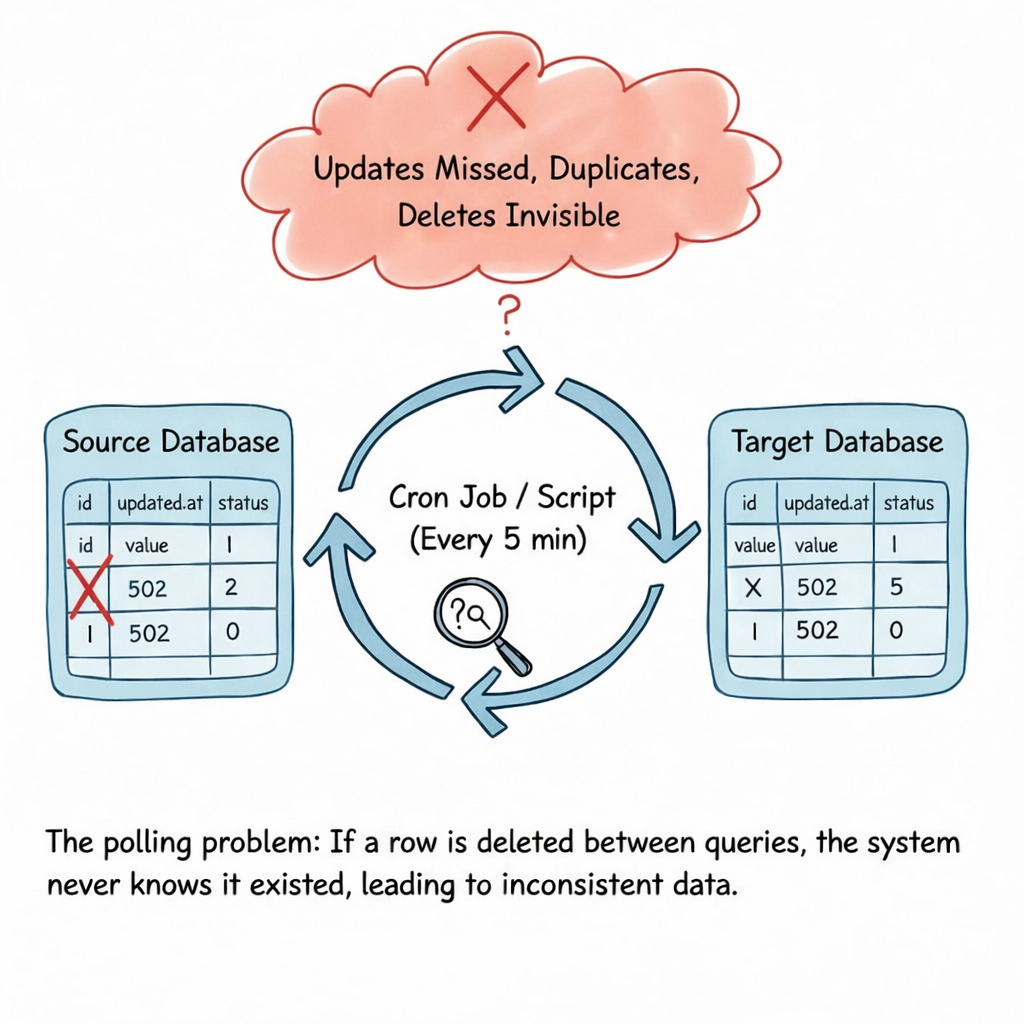
많은 시스템에서 데이터는 새로운 행이나 업데이트된 행을 주기적으로 데이터베이스에 쿼리함으로써 이동됩니다.
일반적인 패턴은 다음과 같습니다:
- 몇 분마다 작업을 실행한다
updated_at > last_run_time인 행을 쿼리한다- 결과를 다운스트림으로 복사한다
- 반복한다
처음에는 합리적으로 보입니다 – 구현이 쉽고 소규모에서는 잘 동작합니다.
하지만 시스템이 커지면서 균열이 생기기 시작합니다.
이 접근 방식의 문제점
- 타임스탬프가 겹칠 때 업데이트 누락
- 작업 재시도 시 중복 데이터
- 삭제가 눈에 보이지 않음(수동 처리 필요)
- 프로덕션 데이터베이스에 높은 부하
- 데이터 변경과 소비자 인식 사이의 지연
이 접근 방식은 일반적으로 **폴링(polling)**이라고 알려져 있으며, 실제 환경에서는 빠르게 한계에 부딪힙니다.
변경 데이터 캡처(CDC)란 무엇인가?
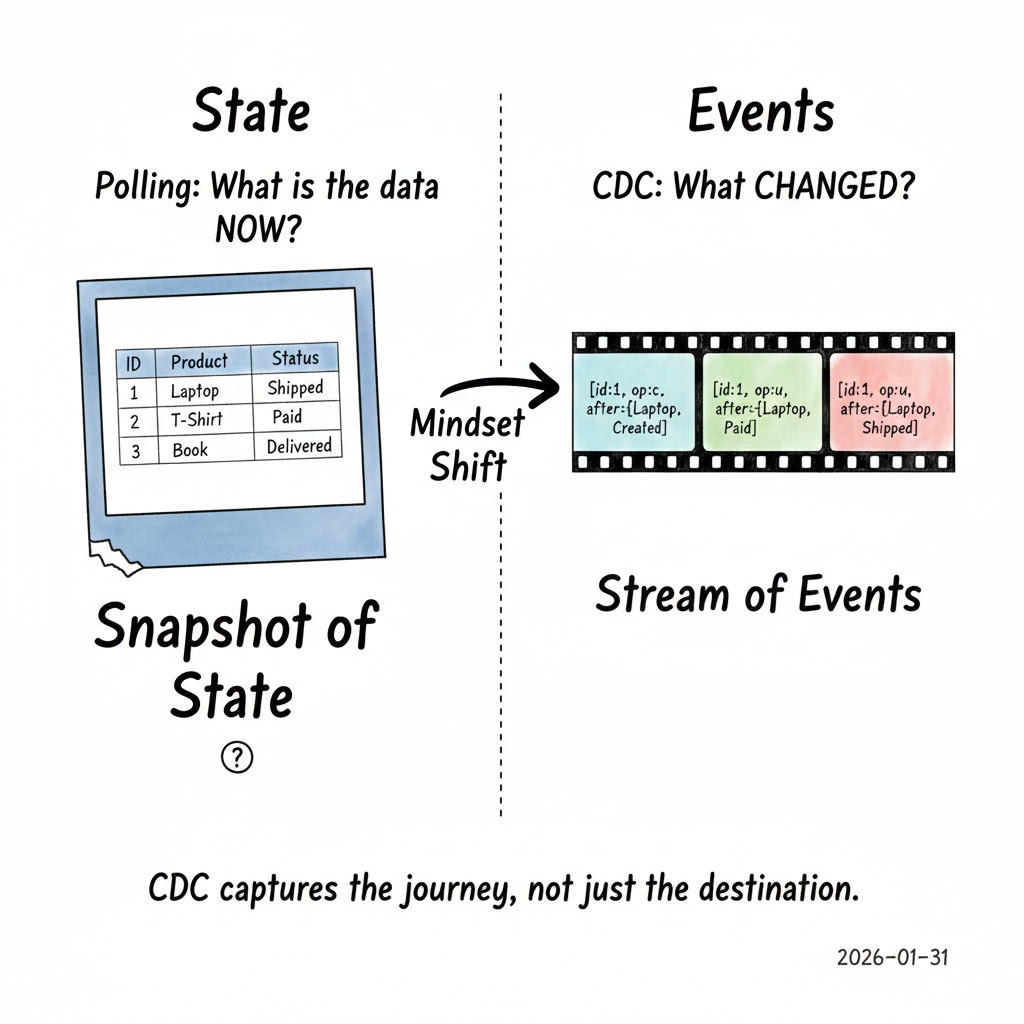
반복해서 묻는 대신:
“데이터가 지금 어떻게 보이나요?”
CDC는 다른 질문을 합니다:
“무엇이 변경되었나요?”
CDC는 삽입, 업데이트 및 삭제를 이벤트로 간주하며, 스냅샷의 행으로 보지 않습니다.
핵심 통찰은 데이터베이스가 이미 모든 변경을 내부적으로 기록하고 있다는 점이며, CDC는 단순히 그 기록을 청취합니다. 이는 CDC를 폴링과 근본적으로 다르게 만듭니다.
Debezium 소개
Debezium은(는) Change Data Capture를 구현하기 위한 오픈소스 플랫폼입니다.
개요:
- Debezium은 데이터베이스의 변경 사항을 캡처합니다
- 이를 이벤트로 변환합니다
- Apache Kafka에 게시합니다
초기에 이해해야 할 중요한 사항:
Debezium은 테이블을 조회하지 않습니다.
데이터베이스 트랜잭션 로그를 읽습니다.
Debezium가 실제로 변경을 캡처하는 방법
| 데이터베이스 | 로그 이름 |
|---|---|
| PostgreSQL | WAL (Write‑Ahead Log) |
| MySQL | Binlog |
| SQL Server | Transaction Log |
이러한 로그는 데이터베이스가 다음을 수행할 수 있도록 존재합니다:
- 충돌 복구
- 데이터 복제
- 일관성 보장
Debezium은 이러한 로그에 접근합니다.
흐름은 다음과 같습니다
- 애플리케이션이 데이터베이스에 데이터를 기록합니다
- 데이터베이스가 트랜잭션 로그에 변경 사항을 기록합니다
- Debezium이 로그 엔트리를 읽습니다
- 변경 사항이 이벤트로 변환됩니다
- 이벤트가 Kafka 토픽에 게시됩니다
폴링 없음. 추측 없음. 누락된 변경 없음.
CDC 이벤트는 무엇을 포함하고 있나요?
Debezium 이벤트는 일반적으로 다음을 포함합니다:
before– 행의 이전 상태after– 행의 새로운 상태op– 작업 유형 (c= 생성,u= 업데이트,d= 삭제)- 타임스탬프 및 트랜잭션 ID와 같은 메타데이터
CDC는 상태를 나타내는 대신 히스토리를 나타냅니다. 이는 미묘하지만 강력한 변화입니다.
실제 예시: 주문 라이프사이클 이벤트
PostgreSQL에 간단한 orders 테이블이 있다고 가정합니다.
시간에 따라 일어나는 일
| 동작 | 변경 |
|---|---|
| 새 주문 생성 | status = CREATED |
| 주문 결제 | status 가 CREATED → PAID 로 변경 |
| 주문 취소/완료 | status 가 다시 변경 |
폴링을 사용할 경우 최신 상태만 확인할 수 있고, 삭제는 종종 놓치며, 중간 전환 단계는 사라집니다.
Debezium을 사용할 경우 각 변경이 이벤트가 되어 전체 라이프사이클을 보존합니다. 소비자는 실시간으로 반응할 수 있습니다.
이 때문에 CDC는 다음에 이상적입니다:
- 분석
- 감사
- 검색 인덱싱
- 캐시 무효화
Kafka는 어디에 들어가나요?
Kafka는 event backbone 역할을 합니다. Debezium은 변경 사항을 Kafka 토픽에 게시하고, 여러 시스템이 이를 독립적으로 소비할 수 있습니다:
- 한 소비자는 캐시를 업데이트합니다
- 다른 소비자는 분석 저장소를 채웁니다
- 또 다른 소비자는 데이터를 데이터 레이크에 씁니다
이러한 디커플링은 확장 가능한 아키텍처에 필수적입니다.
분석 시스템이 들어가는 경우 (미묘하지만 중요함)
다운스트림 시스템은 분석을 위해 CDC 이벤트를 소비할 수 있습니다. 예를 들어, ClickHouse와 같은 분석 데이터베이스는 종종 읽기 최적화 싱크로 사용되며, 여기서:
- CDC 이벤트가 변환됩니다
- 집계됩니다
- 효율적으로 쿼리됩니다
이 설정에서:
- Debezium은 변경 사항을 캡처합니다
- Kafka가 이를 전송합니다
- 분석 시스템은 순수하게 쿼리하는 데 집중합니다
각 시스템은 하나의 작업을 잘 수행합니다.
How CDC compares to other approaches
| Approach | Pros | Cons |
|---|---|---|
| Polling | 구현이 간단함 | 취약하고 비효율적이며 데이터를 놓칠 수 있음 |
| Database triggers | 즉시 캡처 | 침입적이며 유지 관리가 어렵고 성능에 영향을 줄 수 있음 |
| CDC via logs (Debezium) | 신뢰성 높고 확장 가능하며 정확함 | 추가 인프라가 필요함 |
CDC는 마법이 아니지만, 데이터베이스가 실제로 내부에서 작동하는 방식과 일치합니다.
알아두어야 할 트레이드오프
Debezium은 강력하지만 복잡성이 없지는 않습니다. 고려하세요:
- Kafka 인프라가 필요합니다
- 스키마 변경은 신중한 계획이 필요합니다
- 과거 데이터를 백필링하는 것은 간단하지 않을 수 있습니다
- 운영 가시성과 모니터링이 필수적입니다
CDC 파이프라인은 시스템이며, 일회성 스크립트가 아닙니다.
Debezium는 언제 적합한가?
- 모든 데이터 변경을 거의 실시간으로 전파
- 분리된 하위 소비자(분석, 캐시, 검색 등)
- 업데이트나 삭제가 누락되지 않음에 대한 강력한 보장
- 이벤트 스트리밍을 기반으로 한 확장 가능하고 내결함성 아키텍처
이러한 요구사항이 프로젝트와 일치한다면 Debezium을 사용해 보세요!
CDC를 사용해야 할 때
- 거의 실시간 데이터 이동이 필요할 때
- 여러 시스템이 동일한 데이터에 의존할 때
- 정확성이 단순성보다 중요할 때
과도할 수 있는 경우
- 데이터가 자주 변경되지 않음
- 배치 업데이트로 충분함
- 단순함이 최우선
마무리 생각
Change Data Capture(변경 데이터 캡처)는 데이터에 대한 사고 방식을 스냅샷에서 이벤트로 전환합니다.
Debezium은 데이터베이스에 반복적으로 질문을 하는 대신 데이터베이스 자체를 청취함으로써 이 모델을 수용합니다. 이러한 차이가 CDC를 대규모에서도 신뢰할 수 있게 만드는 요인입니다.
업데이트 누락, 취약한 ETL 작업, 또는 일관성 없는 다운스트림 데이터 때문에 어려움을 겪은 적이 있다면, CDC를 이해하는 것이 가치 있습니다 — 비록 즉시 도입하지 않더라도.