UC San Diego 연구실, NVIDIA DGX B200 시스템으로 생성 AI 연구를 진전
Source: NVIDIA AI Blog
2025년 12월 17일, Zoe Kessler

Hao AI Lab은 DGX B200을 어떻게 활용하고 있나요?

Hao AI Lab 구성원들이 NVIDIA DGX B200 시스템과 함께 서 있습니다.
DGX B200이 이제 Hao AI Lab과 UC San Diego 컴퓨팅·정보·데이터 과학 학부의 San Diego Supercomputer Center 전체 커뮤니티에 완전히 개방되면서 연구 기회는 무궁무진합니다.
“DGX B200은 현재까지 NVIDIA가 만든 가장 강력한 AI 시스템 중 하나이며, 그 성능은 세계 최고 수준에 속합니다.” 라고 UC San Diego Halıcıoğlu 데이터 사이언스 연구소 및 컴퓨터 과학·공학과 조교수인 Hao Zhang이 말했습니다. “이 시스템 덕분에 이전 세대 하드웨어를 사용할 때보다 훨씬 빠르게 프로토타입을 만들고 실험할 수 있습니다.”
DGX B200으로 가속화된 프로젝트
-
FastVideo – 텍스트 프롬프트 하나로 5초짜리 영상을 5초 안에 생성할 수 있는 영상 생성 모델군을 학습합니다. 연구 단계에서는 NVIDIA H200 GPU와 DGX B200을 함께 활용합니다.
-
Lmgame‑bench – 대형 언어 모델(LLM)을 테트리스와 슈퍼 마리오 브라더스 같은 인기 온라인 게임과 대결시키는 벤치마크 스위트입니다. 사용자는 단일 모델을 평가하거나 두 모델을 서로 겨뤄 성능을 비교할 수 있습니다.
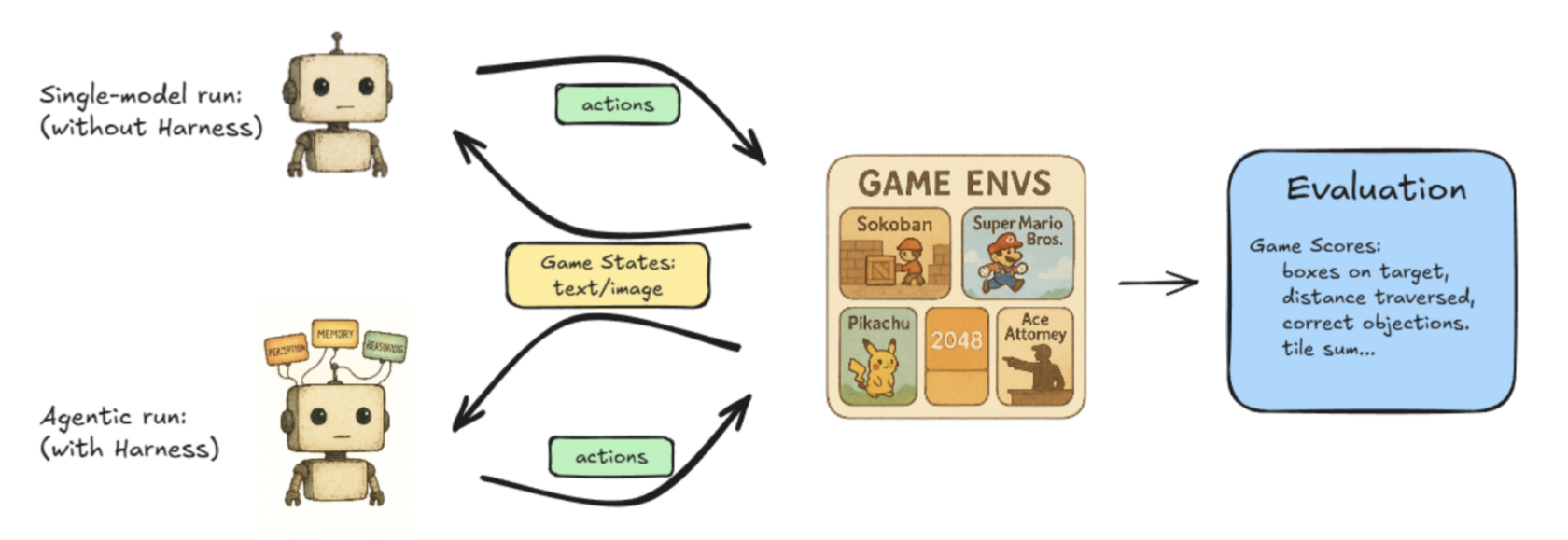
Hao AI Lab의 Lmgame‑Bench 프로젝트 작업 흐름을 그림으로 나타낸 모습. -
Low‑latency LLM serving – 실시간 응답성을 제공하기 위한 새로운 기술을 탐구하는 진행 중인 연구입니다.
“현재 우리는 DGX B200을 활용해 뛰어난 하드웨어 사양이 제공하는 저지연 LLM 서빙의 다음 경계를 탐구하고 있습니다.” 라고 UC San Diego 컴퓨터 과학 박사과정 학생인 Junda Chen이 말했습니다.
DistServe가 분산 서빙에 미친 영향
Disaggregated inference은 대규모 LLM‑서빙 엔진이 전체 시스템 처리량을 최대화하면서 사용자가 인지하는 지연 시간을 허용 가능한 범위 내에 유지하도록 합니다.
왜 분산 추론이 중요한가
- **“goodput”**을 최적화하고 단순한 원시 처리량을 넘어섭니다.
- 시스템 성능을 실제 사용자 경험과 정렬합니다.
처리량 vs. Goodput
| Metric | Definition | What It Captures | Trade‑off |
|---|---|---|---|
| Throughput | 전체 시스템이 초당 생성하는 토큰 수. | 비용 효율성 (토큰 / $). | 지연 시간을 무시; 높은 처리량은 사용자 인지 지연을 증가시킬 수 있음. |
| Goodput | 사용자 지정 지연 목표(SLO)를 충족하면서 달성하는 처리량. | 비용 효율성 및 서비스 품질 모두. | 속도와 응답성을 균형 있게 맞추어 시스템 상태를 보다 전체적으로 파악할 수 있음. |
주요 요점
- 처리량만으로는 사용자가 경험하는 지연을 반영하지 않기 때문에 충분하지 않습니다.
- Goodput은 지연 제약을 포함하므로 LLM‑서빙 워크로드에 더 우수한 지표입니다.
- Goodput에 집중함으로써 DistServe는 최적 효율과 이상적인 모델 출력을 달성하면서 사용자 경험을 희생하지 않습니다.
개발자는 어떻게 최적의 Goodput을 달성할 수 있을까?
사용자가 LLM 시스템에 요청을 하면, 시스템은 사용자 입력을 받아 첫 번째 토큰(prefill)을 생성합니다. 그 후에는 여러 출력 토큰을 하나씩 생성하면서, 과거 요청 결과를 기반으로 각 토큰의 미래 동작을 예측합니다. 이 과정을 decode 라고 합니다.

전통적으로 prefill과 decode는 동일한 GPU에서 실행되었지만, DistServe의 연구진은 이를 서로 다른 GPU에 분산시킬 경우 Goodput을 극대화할 수 있음을 발견했습니다.
“이전에는 두 작업을 같은 GPU에 두면 서로 자원을 놓고 경쟁하게 되어 사용자 입장에서 느려질 수 있었습니다,” 라고 Chen이 말했습니다. “이제 두 작업을 서로 다른 GPU 세트—계산 집약적인 prefill을 담당하는 GPU와 메모리 집약적인 decode를 담당하는 GPU—에 나누면 두 작업 간 간섭을 근본적으로 없앨 수 있어 두 작업 모두 더 빨리 실행됩니다.”
이 과정을 prefill/decode disaggregation이라고 하며, prefill과 decode를 분리해 Goodput을 높이는 방법입니다.
- Goodput을 증가시키고 분산 추론 방식을 사용하면 낮은 지연 시간이나 높은 품질의 모델 응답을 손상시키지 않으면서 워크로드를 지속적으로 확장할 수 있습니다.
- NVIDIA Dynamo – 비용을 최소화하면서 최고 효율 수준으로 생성 AI 모델을 가속·확장하도록 설계된 오픈소스 프레임워크 – 는 분산 추론 확장을 가능하게 합니다.
이러한 프로젝트 외에도, UC San Diego에서는 의료·생물학 등 여러 부서 간 협업을 통해 NVIDIA DGX B200을 활용한 다양한 연구 프로젝트를 최적화하고 있으며, 연구자들은 AI 플랫폼이 혁신을 가속화하는 방법을 지속적으로 탐구하고 있습니다.
NVIDIA DGX B200 시스템에 대해 자세히 알아보세요.
카테고리 및 태그
카테고리:
태그:
관련 NVIDIA 뉴스
| 이미지 | 제목 |
|---|---|
 | NVIDIA GPU에서 Unsloth를 사용해 LLM 파인튜닝하는 방법 |
 | AI에 건배: ADAM 로봇 바텐더가 베가스 골든 나이츠 경기에서 음료 제공 |
 | AI가 복잡해짐에 따라 모델 제작자들이 NVIDIA에 의존하다 |
 | 클라우드에서 캡콤의 ‘몬스터 헌터 스토리즈’ 시리즈와 함께 모험을 떠나다 |
 | 옵트인 NVIDIA 소프트웨어가 데이터 센터 플릿 관리를 가능하게 하다 |
NVIDIA의 AI 혁신 및 연구 성과에 대한 최신 업데이트를 기대해 주세요.