개발자들이 AI 앱을 출시하기 위해 사용하는 Top 8 Fal.AI 대안
I’m happy to translate the article for you, but I need the full text of the post in order to do so. Could you please paste the content you’d like translated (excluding the source line you already provided)? Once I have the article text, I’ll translate it into Korean while preserving the original formatting, markdown, and any technical terms.
왜 Fal.AI를 넘어볼까?
분명히 말하자면, Fal.AI는 자신이 하는 일에 뛰어납니다. Fal.AI는 다음에 집중합니다:
- 빠른 추론
- 간단한 API
- 관리형 GPU 접근
하지만 현대 AI 애플리케이션은 종종 단일 추론 엔드포인트 이상을 필요로 합니다. 오케스트레이션, 멀티모달 파이프라인, 글로벌 규모, 그리고 프로덕션 수준의 신뢰성이 필요합니다. 바로 이런 점에서 대안들이 의미를 갖기 시작합니다.
Source:
1. Hypereal AI

Hypereal은 AI 앱을 위한 인프라 레이어를 목표로 하며, 특히 풍부한 미디어와 실시간 상호작용을 다루는 경우에 초점을 맞추고 있습니다.

Hypereal의 핵심 아이디어는 간단합니다: 개발자는 AI 제품을 출시해야지 GPU를 관리하지 않아도 된다. 모델 라우팅부터 전역 추론까지 모든 것이 자동으로 처리되므로, 인프라가 아닌 기능 구축에 집중할 수 있습니다.
주요 특징
- 여러 AI 모달리티를 위한 통합 신경 인터페이스
- LLM, 디퓨전, 오디오, 비디오 모델을 아우르는 내장 오케스트레이션
- 예측 기반 자동 스케일링을 통한 적응형 추론
- 실시간 사용 사례에 최적화된 50 ms 미만 지연 경로
- H100 및 H200 텐서 코어를 활용한 전용 AI 컴퓨팅
- 프로덕션 준비가 된 오픈소스 모델 큐레이션 카탈로그
- 실시간 스트리밍을 지원하는 REST API
- 사용량 기반 요금제로 제로 스케일링 가능
가장 적합한 경우
- 생성형 미디어 제품을 개발하는 팀
- 실시간 아바타 및 디지털 휴먼
- 멀티모달 AI 애플리케이션
- AI가 핵심 경험을 이루는 제품(단순 기능이 아닌)
2. Modal

Modal은 Python 개발자를 위해 즉시 클릭할 수 있습니다. Python 함수를 작성하고, 컴퓨팅 리소스를 연결한 뒤, 플랫폼이 스케일링과 실행을 처리하도록 하세요.
핵심 하이라이트
- Python 우선 개발 모델
- AI 워크로드를 위한 서버리스 실행
- 내장 GPU 지원
- 수요에 따른 자동 스케일링
- 로컬 코드와 프로덕션 간 최소 격차
가장 적합한 대상
- Python 중심 팀
- 모델을 프로덕션으로 옮기는 연구원
- 개발자 편의성을 중시하는 소규모 팀
- 인프라 제어보다 빠른 반복이 필요한 프로젝트
3. RunPod

RunPod은 스펙트럼의 인프라스트럭처 쪽에 더 가깝습니다. 개발자에게 GPU 접근을 제공하고, 원하는 제어 수준을 선택할 수 있게 합니다.
주요 특징
- 온‑디맨드 및 지속적인 GPU 인스턴스
- 맞춤형 컨테이너 지원
- 유연한 가격 옵션
- 장기 실행 추론 워크로드에 적합
- 셀프‑관리 추론 서버와 잘 작동
가장 적합한 대상
- 배포 관리에 익숙한 팀
- GPU 비용 최적화에 중점을 둔 개발자
- 맞춤형 추론 파이프라인
추론 설정
서버리스 실행 모델에 맞지 않는 워크로드
4. AWS SageMaker
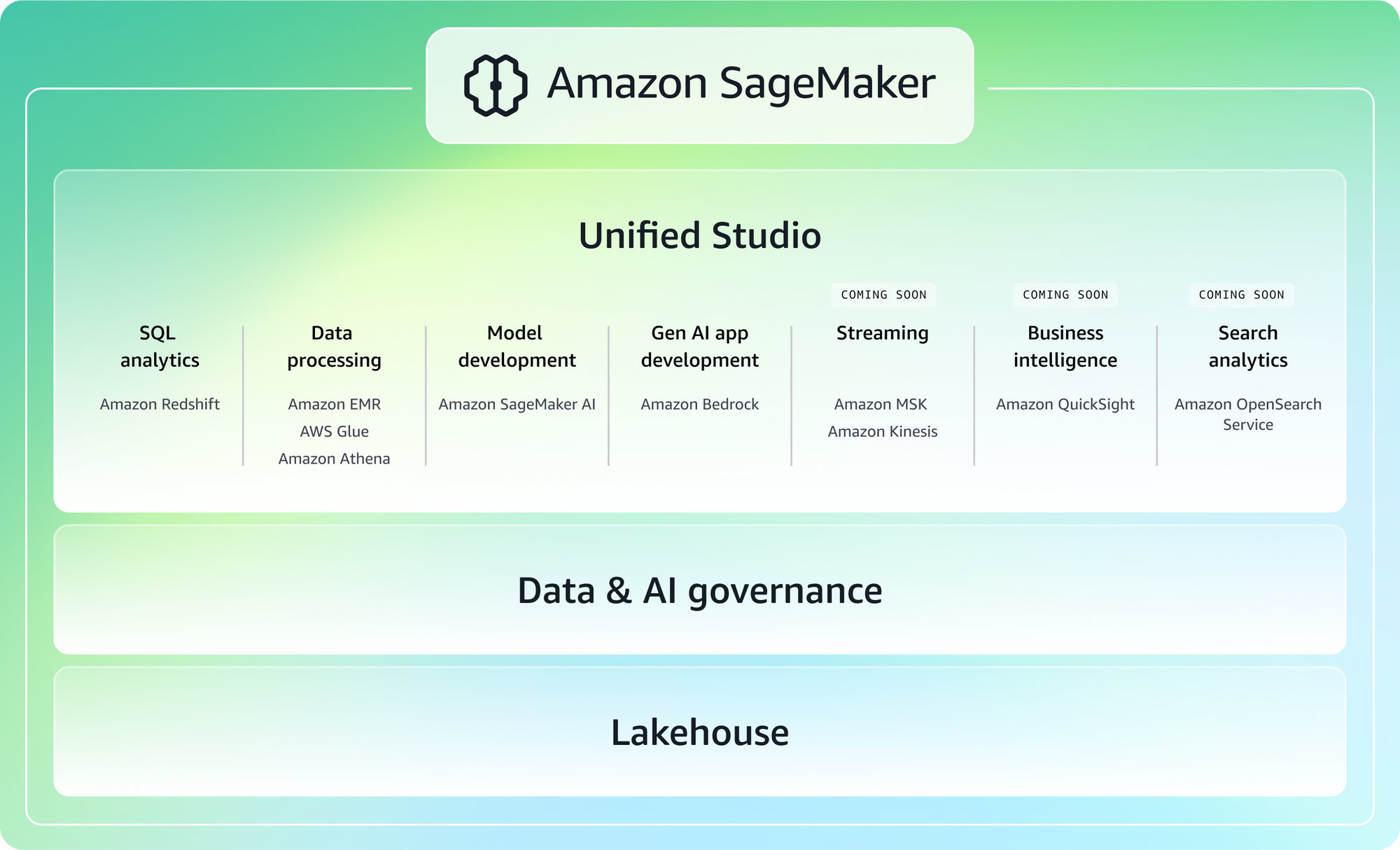
SageMaker는 방대한 플랫폼으로, 교육부터 배포, 모니터링까지 전체 머신러닝 라이프사이클을 포괄하도록 설계되었습니다. 주로 AWS에 깊이 투자한 대규모 조직이나 팀에서 많이 사용됩니다.
핵심 하이라이트
- 엔드‑투‑엔드 ML 라이프사이클 관리
- 관리형 교육 및 추론
- AWS 서비스와의 통합
- 대규모 ML 워크플로 지원
- 거버넌스와 보안에 대한 강력한 초점
가장 적합한 대상
- 이미 AWS를 사용 중인 기업
- 전담 ML 엔지니어가 있는 팀
- 규제나 컴플라이언스가 중요한 환경
- 표준화된 ML 파이프라인이 필요한 조직
5. Google Vertex AI

Vertex AI는 머신러닝 모델을 구축, 학습 및 배포하기 위한 통합 플랫폼을 제공하며, MLOps에 강력히 중점을 둡니다. 구조화된 워크플로와 장기적인 유지보수를 원하는 팀에게 인기가 높습니다.
주요 특징
- 통합된 학습 및 추론 플랫폼
- 관리형 ML 파이프라인
- 강력한 MLOps 도구
- Google Cloud 서비스와의 깊은 통합
- 커스텀 모델 및 워크플로 지원
가장 적합한 경우
- 이미 Google Cloud를 사용 중인 팀
- MLOps를 우선시하는 조직
- 복잡한 ML 파이프라인을 가진 제품
- 장기적인 프로덕션 중심 ML 시스템
6. Hugging Face Inference Endpoints

오픈소스 모델을 사용해 본 적이 있다면 거의 확실히 Hugging Face와 상호작용했을 것입니다. Hugging Face의 인퍼런스 엔드포인트를 사용하면 Hugging Face Hub에서 직접 모델을 손쉽게 배포할 수 있습니다.
주요 특징
- Hugging Face Hub에서 직접 배포
- 인기 있는 트랜스포머 모델 지원
- 커스텀 컨테이너 옵션 제공
- 간단한 API 기반 접근 방식
- 머신러닝 엔지니어에게 친숙한 생태계
가장 적합한 경우
- 오픈소스 중심 팀
- 트랜스포머 중심 워크로드
- 프로덕션 API를 프로토타이핑하는 ML 엔지니어
- 이미 Hugging Face 모델을 사용 중인 팀
7. Baseten

Baseten은 AI 추론의 “프로덕션” 측면에 중점을 둡니다. 사용자에게 AI 기능을 제공하고 신뢰성, 지연 시간, 가시성을 깊이 있게 관리해야 하는 팀을 위해 설계되었습니다.
핵심 하이라이트
- 프로덕션 급 추론 API
- 저지연 모델 서빙
- 내장 가시성
- 확장 가능한 배포 아키텍처
- 실제 사용자 트래픽을 위해 설계
가장 적합한 경우
- AI 기능을 출시하는 제품 팀
- 엄격한 성능 요구 사항을 가진 애플리케이션
- 대규모에서 신뢰성이 필요한 팀
- AI 기반 SaaS 제품
8. 셀프‑호스팅 추론 (Kubernetes + GPU)
모든 것을 직접 운영하면 완전한 제어권을 얻을 수 있지만, 그만큼 책임도 전적으로 따르게 됩니다. 보통 첫 번째 선택은 아니지만, 일부 팀에게는 장기적으로 올바른 선택이 될 수 있습니다.
핵심 요약
- 인프라에 대한 완전한 소유권
- 맞춤형 스케줄링 및 확장
- 벤더 종속성 없음
- Kubernetes와 GPU 노드와 호환
- 고도로 커스터마이징 가능한 배포 파이프라인
가장 적합한 경우
- DevOps·MLOps 경험이 풍부한 팀
- 규제 혹은 보안에 민감한 환경
- 장기 비용 최적화를 추구하는 조직
- 인프라 전반에 대한 완전한 제어가 필요한 제품
내가 이 플랫폼들을 선택하는 기준
“Fal.AI보다 어느 것이 더 좋은가?” 라고 묻는 대신, 다음을 고려해 보세요:
- AI가 기능인가, 아니면 제품 자체인가?
- 멀티모달 파이프라인이 필요할까?
- 얼마나 많은 인프라를 직접 관리하고 싶나요?
- 6개월 후의 확장은 어떻게 될까?
서로 다른 답은 서로 다른 도구를 선택하게 만든다.
최종 생각
Fal.AI는 여전히 많은 사용 사례에 견고한 선택입니다. 하지만 AI 제품이 성장함에 따라 인프라 결정이 가능한 것과 고통스러운 것을 형성하기 시작합니다.
이 목록에 있는 플랫폼들은 AI 배포에 대한 다양한 철학을 반영합니다. 일부는 단순성을 우선시하고, 일부는 제어를, 또 일부는 프로덕션 규모의 오케스트레이션을 중시합니다. 단 하나의 “최고” 옵션은 없으며, 당신에게 맞는 것이 중요합니다.
제가 배운 한 가지가 있다면, 그것은 다음과 같습니다:
최고의 AI 플랫폼은 제품이 실제로 성장했을 때 교체할 필요가 없는 플랫폼입니다.