시계열 데이터베이스 vs. 관계형 데이터베이스, 차이점은 무엇인가
Source: Dev.to
번역하려는 전체 텍스트를 제공해 주시면, 요청하신 대로 한국어로 번역해 드리겠습니다. (코드 블록, URL, 마크다운 형식 등은 그대로 유지됩니다.)
소개
많은 팀이 친숙하고 다재다능하기 때문에 관계형 데이터베이스를 기본 선택으로 합니다. 비즈니스 시스템에서는 그 선택이 종종 옳습니다.
하지만 워크로드가 변할 때 — 변동 가능한 비즈니스 레코드에서 고주파 텔레메트리 스트림으로 전환될 때 — 데이터베이스 아키텍처는 매우 다른 방식으로 중요해집니다.
모든 데이터 문제에 관계형 접근이 필요한 것은 아니며, 모든 데이터베이스가 시간을 위해 설계된 것도 아닙니다.
**Relational databases (RDBMS)**는 일반 목적 모델링 능력과 강력한 트랜잭션 보증 덕분에 전자상거래 플랫폼, 물류 플랫폼, ERP 시스템과 같은 기업 시스템을 구동합니다.
**Time‑series databases (TSDB)**는 반대로 시간 인덱스 데이터를 위해 특화되어 있습니다. 산업용 IoT, 에너지 시스템, 가시성 플랫폼, 모니터링 인프라, 금융 시계열 분석 등에 널리 사용됩니다.
각 데이터베이스가 언제 적합한지 이해하기 위해, 우리는 다섯 가지 아키텍처 차원에서 비교합니다.
1. Transaction Mechanism: Essential vs. Often Secondary
Relational Databases – ACID Is Fundamental
Relational databases support ACID transactions, ensuring atomicity, consistency, isolation, and durability.
Example – Bank Transfer
| Step | Action |
|---|---|
| 1 | Account A deducts $10 |
| 2 | Account B credits $10 |
Both operations must either succeed together or fail together. If a system crash or network failure occurs mid‑operation, the database must roll back to preserve consistency.
To achieve this in distributed systems, RDBMS engines maintain:
- Write‑ahead logs (WAL)
- State tracking
- Concurrency‑control mechanisms
- Rollback and recovery protocols
Transactional integrity is a core requirement because business data is frequently modified and subject to concurrent updates.
Time‑Series Databases – Transactions Are Often Less Critical for Ingestion
In many industrial IoT ingestion workloads, data originates from sensors. Each record represents a real‑world measurement at a specific timestamp (e.g., temperature, wind speed, voltage).
Typical characteristics:
- Append‑only data
- Each record is independent
- No multi‑row atomic updates
- No write‑write conflicts
In these workloads, heavy transactional coordination adds overhead without proportional value. TSDB systems therefore trade transactional complexity for ingestion scale — prioritising high‑throughput, stable streaming writes.
2. Write Patterns: Consistency‑Centric vs. Throughput‑Centric
Relational Databases – Strong Schema & Consistency
RDBMS typically store:
- Configuration data
- Personnel records
- Business entities
- Financial transactions
데이터는 보통 구조화된 양식을 통해 입력되며 미리 정의된 스키마와 제약 조건을 엄격히 따라야 합니다. 트랜잭션 의미론 때문에:
- 쓰기가 그룹화됨
- 전체 배치가 커밋되거나 롤백됨
- 원시 처리량보다 일관성이 우선시됨
이 설계는 관련 엔터티 간의 정확성이 중요한 시스템에 이상적입니다.
Time‑Series Databases – Extreme Write Throughput
시계열 워크로드는 크게 다릅니다:
- 데이터는 센서 또는 디바이스에서 발생함
- 디바이스 수는 수천 대에서 수백만 대까지 다양함
- 샘플링 간격은 초 또는 밀리초일 수 있음
- 쓰기 속도는 초당 수천만 포인트에 이를 수 있음
TSDB 시스템은 다음을 위해 설계되었습니다:
- 고동시성 인제스트
- 높은 처리량
- 순서가 뒤섞인 데이터 처리
Example – Apache IoTDB는 기본 스토리지 포맷 Apache TsFile을 활용하여:
- 컬럼형 데이터 인제스트
- 밀리초 수준 데이터 접근
- 불안정한 네트워크 환경을 위한 순서 뒤섞인 분리 저장 메커니즘
- 벤치마크 시나리오에서 안정적인 고처리량 인제스트
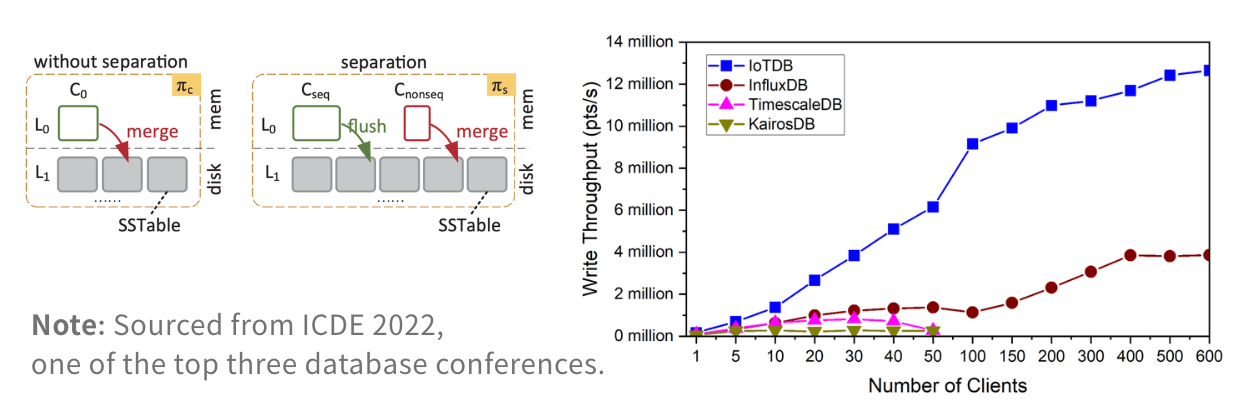
Source:
3. Storage & Compression: General‑Purpose vs. Time‑Series‑Optimized
Relational Databases – B+ Trees & Generic Compression
RDBMS 스토리지 엔진은 일반적으로 다음을 사용합니다:
- B+‑tree 인덱싱
- Row‑based 또는 하이브리드 스토리지
- Generic compression 알고리즘 (LZ77, DEFLATE 등)
Compression은 선택 사항이며 워크로드 요구사항에 따라 조정됩니다. 스토리지 포맷은 다차원 쿼리와 트랜잭션 일관성을 위해 최적화됩니다.
Time‑Series Databases – Time‑Series‑Optimized Storage
시계열 데이터는 스토리지 엔진이 활용할 수 있는 구조적 특성을 가집니다:
- 강한 시간적 지역성
- 순차적 append 패턴
- 연속 데이터 포인트 간 작은 delta
이러한 특성은 다음을 가능하게 합니다:
- Columnar 스토리지
- Run‑Length Encoding (RLE)
- Delta encoding
- Specialized compression 알고리즘
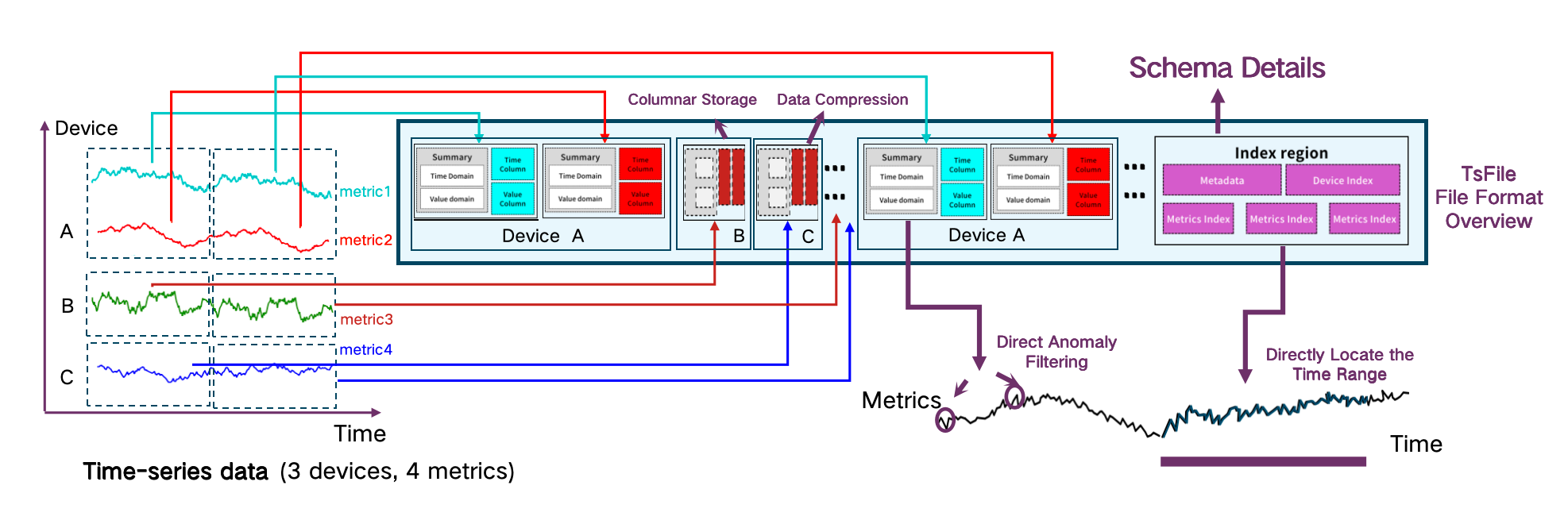
IoTDB에서 기반이 되는 포맷 Apache TsFile 은 다음을 제공합니다:
- 다차원 인덱싱 (device, sensor, timestamp)
- 빠른 시간 범위 필터링
- 일반 포맷에 비해 5–10배 향상된 쿼리 처리량
- 최대 15배 높은 압축 비율
위 비교는 관계형 데이터베이스가 일관성 중심의 스키마 기반 워크로드에 뛰어난 반면, 시계열 데이터베이스는 대규모 append‑only, 타임스탬프가 있는 스트림을 처리할 때 강점을 보임을 강조합니다.
Source:
Query Patterns: Precise Retrieval vs. Time‑Dimension Analytics
Relational Databases – Entity‑Based Querying
Typical SQL constructs:
SELECT -- select target columns
FROM -- define the source table
WHERE -- set filtering conditionsRDBMS strengths
- 정확한 필터링
- 다중 테이블 조인
- 복잡한 비즈니스 로직 쿼리
- 외래 키 관계
목표는 구조화된 데이터 세트 전반에 걸쳐 정확한 엔터티 검색과 관계 일관성을 유지하는 것입니다.
Time‑Series Databases – Temporal Analysis at Scale
Common TSDB query characteristics:
- 주, 월, 연도 단위의 트렌드 분석
- 수십만 개 포인트에 대한 대규모 집계
- 높은 빈도의 대시보드 새로 고침(예: 초당 수백 개 메트릭)
User expectations
- 높은 쿼리 처리량
- 효율적인 시간 창 필터링
- 네이티브 시계열 처리 기능
IoTDB capabilities
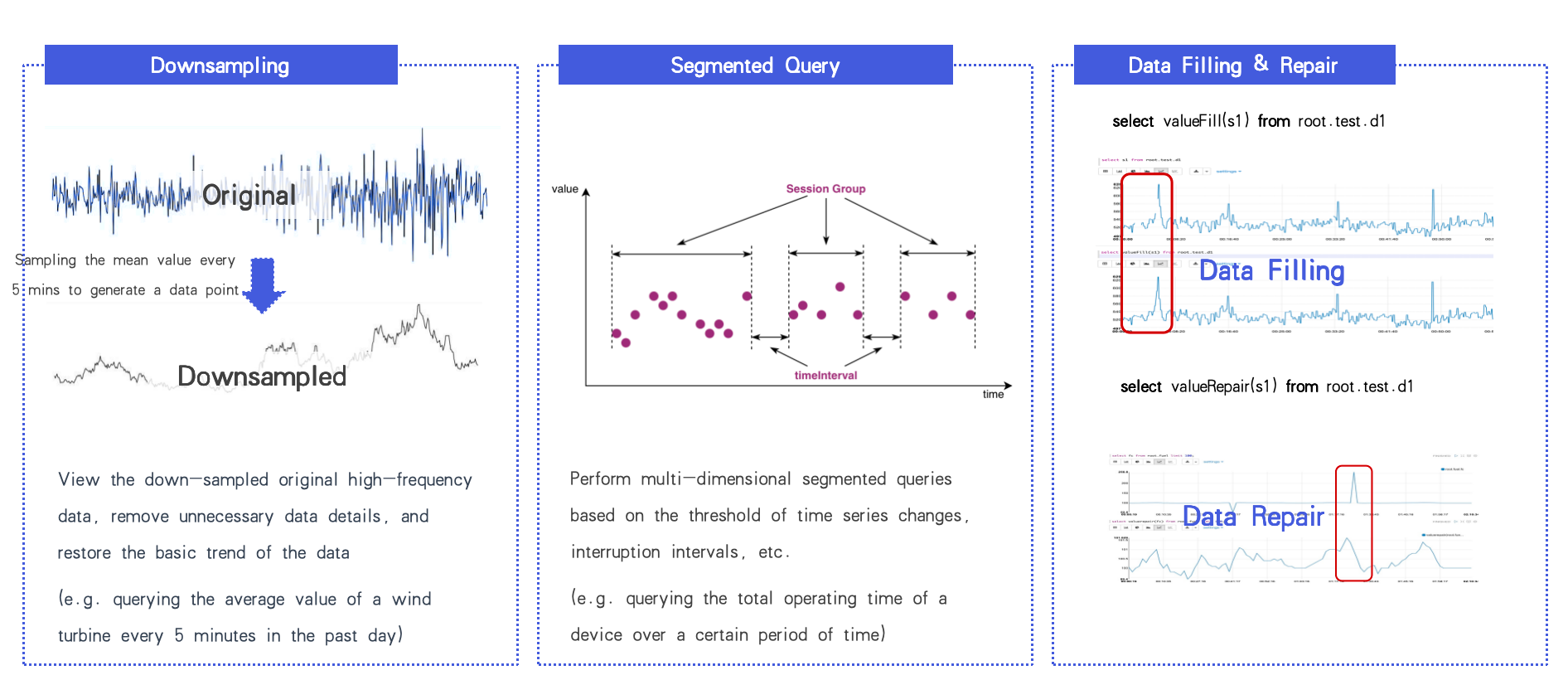
- TsFile을 통한 고처리량 시간 범위 쿼리
- 시각화 효율성을 위한 다운샘플링
- ~100개의 내장 시계열 함수(세분화, 결측 보정, 데이터 복구 등)
데이터 순환: 중앙 집중식 관리 vs. 엣지‑클라우드 협업
관계형 데이터베이스 – 플랫폼 중심 스토리지
일반적인 RDBMS 사용:
- 내부 비즈니스 데이터 저장
- 독점 스토리지 포맷 사용
- 중앙 집중식 애플리케이션 워크로드 제공
시스템이 진화할 때 데이터 마이그레이션은 종종 포맷 변환을 필요로 합니다.
시계열 데이터베이스 – 엣지‑클라우드 동기화
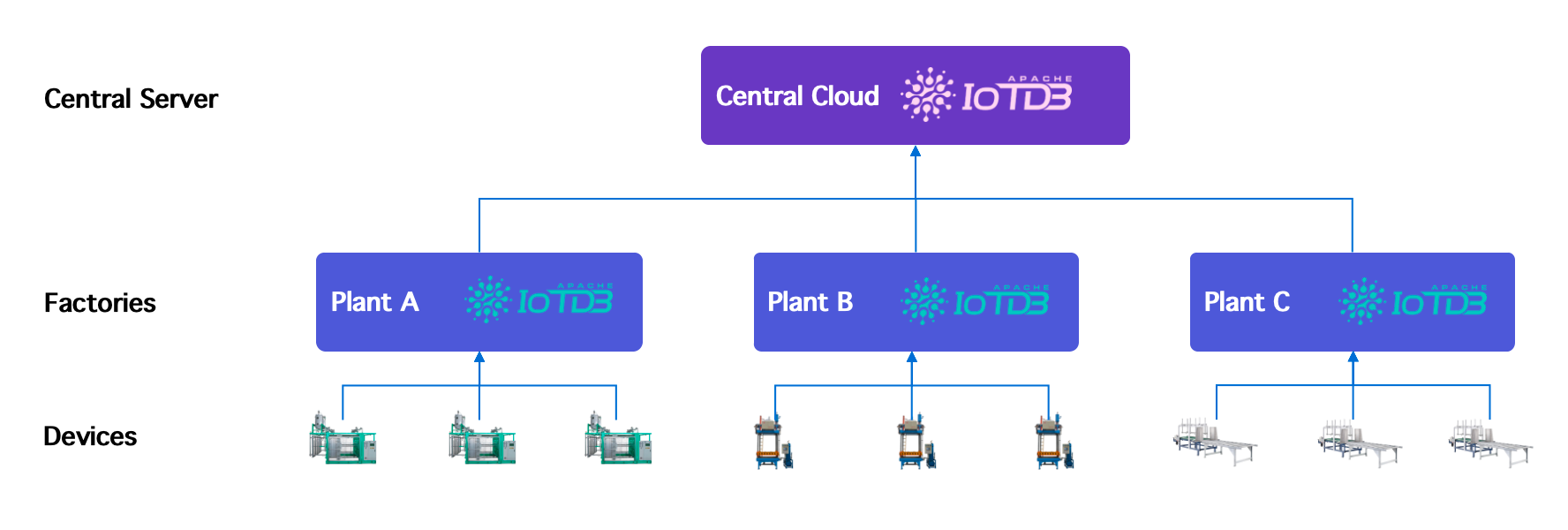
산업용 IoT 아키텍처는 종종 다음 흐름을 따릅니다:
Devices → Edge nodes → Regional data centers → Central cloud platforms추가 제약 조건은 다음과 같을 수 있습니다:
- 생산 네트워크 격리
- 단방향 데이터 게이트웨이
- 대역폭 제한
TSDB 최적화 목표
- 효율적인 단말 간 동기화
- 저대역폭 복제
- 최소 CPU 오버헤드
- 파일 기반 전송
IoTDB는 통합된 TsFile 포맷으로 이러한 요구를 충족시키며, 다음을 가능하게 합니다:
- 파일 기반 데이터 교환
- 구독 기반 동기화
재수집 방식과 비교했을 때 얻어지는 이점:
- 최대 90 % 네트워크 대역폭 절감
- 수신 노드에서 최대 95 % CPU 절감
결론
시계열 데이터베이스와 관계형 데이터베이스 간의 차이는 근본적으로 이들이 다루는 데이터의 특성에서 비롯됩니다.
| 차원 | 관계형 데이터베이스 | 시계열 데이터베이스 |
|---|---|---|
| 데이터 모델 | 엔터티 관계 | 시간 인덱스 메트릭 |
| 트랜잭션 | 필수 | 대량 수집 워크로드에서는 덜 중심적 |
| 쓰기 초점 | 일관성 | 높은 처리량 |
| 스토리지 | B+ 트리, 일반 압축 | 시간 최적화, 컬럼 지향 포맷 |
| 쿼리 스타일 | 다중 테이블 정밀도 | 대규모 시계열 분석 |
| 데이터 흐름 | 애플리케이션 중심 | 엣지‑클라우드 협업 |
TSDB와 RDBMS 중 선택할 때 조직은 다음을 평가해야 합니다:
- 데이터 생성 패턴 – 데이터가 시간에 연관되어 있나요?
- 쓰기 처리량 요구사항
- 쿼리 복잡도
- 엣지‑클라우드 동기화 필요성
- 인프라 제약 조건
올바른 데이터베이스 아키텍처를 선택하는 것은 단순한 기술적 선호가 아니라, 확장성 한계, 인프라 비용, 장기 운영 효율성에 직접적인 영향을 미칩니다.
Note: 이것은 기능별 비교가 아니라 워크로드‑아키텍처 결정입니다.